-
It is generally impractical and unnecessary to poll a population to find out the population parameters.
-
Instead we estimate population parameters from statistics we generate in samples
Samples are subsets of populations
-
A sample distribution can characterized by its center (
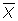 ) and its average spread (S.D.)
) and its average spread (S.D.) -
Both the mean and the S.D. are called statistics
-
Statistics are numerical facts about a sample. They are a mixture (in quantities we cannot be precisely sure of) of true score, chance error, and bias