So what does this mean? We don't ever repeatedly select samples from a population. Instead we select one sample and use that to infer something about the population. The central limit theorem says that we can use our sample mean as an estimate of the population mean. Further, we can, by dividing by the square root of our sample size, use our sample estimate of the standard deviation to estimate the SE of the sampling distribution of the means,
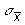 . And, because the sampling distribution of the means has a distribution that approximates normal, if the underlying population distribution is normal, we can use the mean and the newly calculated estimate of SE to create confidence intervals.
. And, because the sampling distribution of the means has a distribution that approximates normal, if the underlying population distribution is normal, we can use the mean and the newly calculated estimate of SE to create confidence intervals.