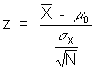
Ó
2004, S. D. Cochran. All rights reserved.DRAWING CONCLUSIONS
Making decisions
After we conduct a statistical test, we either reject the null hypothesis or we fail to reject it. That doesn't mean that the null hypothesis is in fact true or false. That we are never completely certain about. You can think of situation as a 2 X 2 table:
Our decision: |
H0 is in fact true |
H0 is truly false |
We reject H0 |
INCORRECT DECISION Alpha ( a )--Type I error |
CORRECT DECISION Power--(1 - b ) |
|
We fail to reject H0 |
CORRECT DECISION |
INCORRECT DECISION beta ( b )--Type II error |
a = .05. Making an error here is called Type I error.
We set alpha ourselves. Alpha is the percentage of time we are willing to be wrong in rejecting the null hypothesis. There is no true effect or difference, but we are willing to be wrong and conclude there is. There is no magic place to decide what alpha should be. It is generally set by convention or sometimes by how much risk we are willing to take in being wrong. The convention is generally p = .05, or you'll see it written
If the null hypothesis is true and we fail to reject it, we have made a correct decision.
If the null hypothesis is truly false, that is the difference is not due to chance, and we fail to reject it, or another way to put it, we fail to detect a true difference, we have also made a mistake. This is called beta or Type II error. We cannot directly calculate beta, so we are never sure how frequently we will make this error.
The final cell is the situation where there is a difference not due to chance alone, the null hypothesis is truly false, and we are able to reject the null hypothesis. This is the ability to see a difference that is truly there. Scientists call this power. It is 1 minus beta, but since we cannot estimate beta, we have a hard time figuring out how much power we truly have in any analysis. There are techniques that are used to calculate this, but they are far beyond this course and they rely on assumptions that are generally weak.
You might say you are unwilling to accept a Type I error, but it is a balancing act. The less Type I error you are willing to accept the more likely you will make a Type II error.
Further, if you do more than one analysis with your data, each time you are taking a 5% risk of making a Type I error.
It is not that we should never make errors--it is more that we should not let alpha levels and significance cloud our judgment. One of the points in the book is that even articles you read in journals may have made decisions that are open for discussion. Just because they are published doesn't mean they're right or correct. Hopefully, you have learned in the class to be a better consumer of uncertainty.
The utility of results
A second problem with the tests that you have learned is that sample size is a strong influence in whether or not you find statistical significance. How is this so? Remember that the sample size is always in the denominator of these statistics. For example, with z, the formula is:
So as n gets very large, the denominator gets very small, and even minor differences between what we observe and what we expect will result in large z scores. Very minor differences would be statistically significant, but trivial. This would not be a Type I error because the decision is correct in regards to chance, but remember, bias also contributes to observations and with large sample sizes even small bias can create significant results.
Conversely, with very small samples, it will be very difficult to get a large z score even with relatively large differences between what we observe and what we expect under conditions of chance. So we will make Type II errors. We do not have the power to detect a true difference.
There are techniques, more advanced than this class, to estimate the strength of the results we have found.
This is all to say that we must not let statistics do the thinking for us. When you read that something is statistically significant, you still must ask yourself "how important are these results?"
Example: Let's say a new pill came out that caused anyone who took it to lose one pound, no more, no less. A study was done with a large sample. The researchers found this true effect and reported that it was highly significant. What do you think?
Is the research hypothesis supported by the statistical test?
Remember, the statistical test evaluates only whether the effect appears to be due to chance. It is up to the researcher to translate the research question into a statistical question that when resolved provides an answer to the real question of interest, the research question.
In reading articles, one of ways that you can evaluate the value of the statistical result is to ask, if these results came out differently could I use a completely contradictory finding just as to well to prove the point?
Example: Your parents decide to run an experiment, the outcome of which they think will prove that you are an ungrateful college student who takes all their money and feels no gratitude. They put a $50 bill on the driveway at home just before you come home for a visit and watch from the windows to see if you pick it up and put it in your pocket. You do pick it up. AHA, the results are significant, you are greedy and therefore ungrateful! You don't pick it up. AHA, the results are significant, you don't know the value of money, you'll walk right past a $50 bill, and therefore you are ungrateful. With either outcome your parents have proof that the hypothesis is true--but there is no outcome that can disprove the hypothesis.
The role of the model
The book justly points out that the statistical methods you have just been taught rely on models that are dependent on assumptions.
There is generally no way to do research perfectly. Over time, results from studies either hold up or they don't. If they hold up, the findings are said to be robust.
In evaluating the use of statistics, knowledge of these assumptions and models can help you to be sensitive to their violation. Sometimes the violation is relatively harmless; sometimes it is not. One of the reasons scientists learn statistics is so that we can make important judgments about the quality of our own work and the work of others.
One of the most common problems comes from weakness in defining the population to be sampled from (the "box" in the book) and the relationship between the sample and the population.
Most research is done using convenience samples. It's cheaper, and also when you are looking for something and most of the time you find nothing, it doesn't always make sense to make each research study very expensive.
Convenience samples are related to the population in unknown ways. We can be certain about our measure of center and spread within the sample (the descriptive statistics) but taking these estimates and applying them to the population of interest is problematic. And because many of our statistics use the sample to generate estimates of population parameters, the accuracy of these estimates are unknowable.
Example: Let's say we wanted to estimate the positive attitudes towards fraternities and sororities among college students. For convenience, we walked up and down Hilgard and Gayley recruiting subjects. Can we take these responses from what must be a lot of fraternity and sorority members as typical for the whole population of college students?
But just because convenience samples pose problems does not mean that convenience samples should never be used. Most research using samples like this strive to develop designs to mitigate obvious sampling problems.
The truth is that with convenience sampling, the population that the sample is drawn from is still undefined, and using the statistics you have just been taught is, as noted in the book, incorrect but by how much we do not know. This is more uncertainty that all of us have to grapple with. There is no way to avoid it--but by being smart and thoughtful we can reduce as much uncertainty as possible--that is the art of being a skilled researcher.