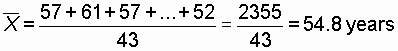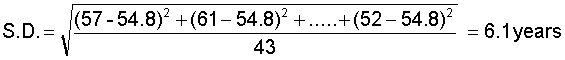- A third way of thinking about average is the mean. The mean is a weighted sum. We calculate it by summing all the scores and then weighting by the number of scores that contributed to that sum. In that way we control for the size of the sample that contributed scores.
- Some final thoughts about the averages
Example: In a second group of 6 children there were the following ages: 5, 9, 11, 6, 3, 1. If we arrange the ages in numerical order we can see that half are 5 and below; half are 6 and above so the median age is 5.5 years
The median gives us a clear sense of the middle of the distribution but often times it is a general sense rather than a precise sense.
For example, if we sampled 3000 students or 300 students from UCLA and asked how frequently they exercised, the mean would be very close to the same, because by dividing by the sample size we adjust or weight for that factor.
The mathematical formula for the mean is: given a list of n numbers,
![]()
Example: In our first group of children the mean is (6+ 5+7+6+6+5)/6=5.83