
The model can be used for unsupervised hierarchical feature learning. Supervised classifiers learned on top of these features can be used for classification. We use the LHI Animal-Faces dataset [1], which has around 2200 images of 20 categories of animal faces. We randomly select half of the images per category for training and the rest for testing. For each category, we learn a mixture model of 5 or 11 hierarchical sparse FRAME models with 2 x 2 moving parts in an unsupervised manner. We then combine the object templates from all the learned mixture models into a codebook of 20 x 5 = 100 or 20 x 11 = 220 codewords. (Each object templte is a codeword.) The maps of template matching scores from all the codewords in the codebook are computed for each image, and then they are fed into spatial pyramid matching (SPM), which equally divides an image into 1, 4, 16 areas, and the maximum scores at different image areas are concatenated into a feature vector. SVM classifiers with l2 loss are trained on these feature vectors, and are evaluated on the testing data in terms of classification accuracies using the one-versus-all rule. Table 1 lists a comparison of our models with some baseline methods (And-Or template [2], and sparse FRAME model without parts [3]).
# clusters |
AoT [2] |
ours w/o parts [3] |
ours |
5 |
65.80 % |
70.62 % |
74.33 % |
11 |
62.54 % |
72.56 % |
75.83 % |
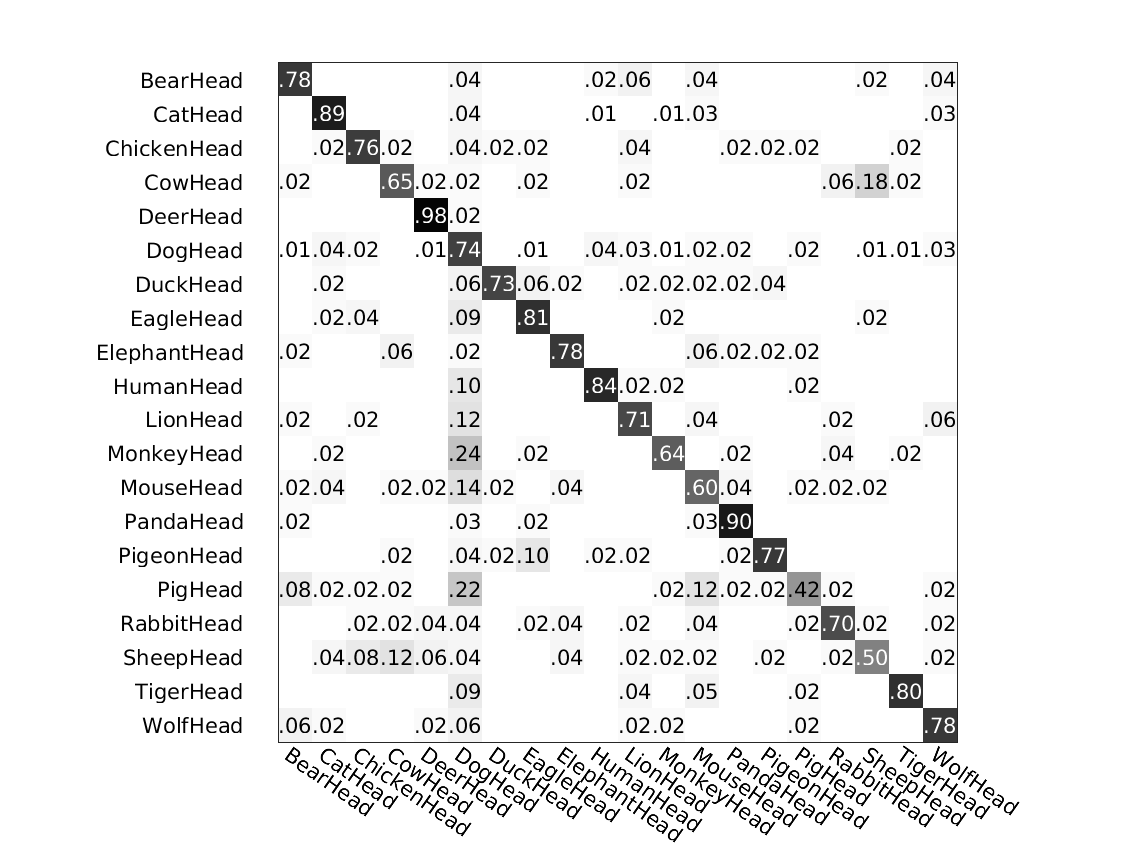
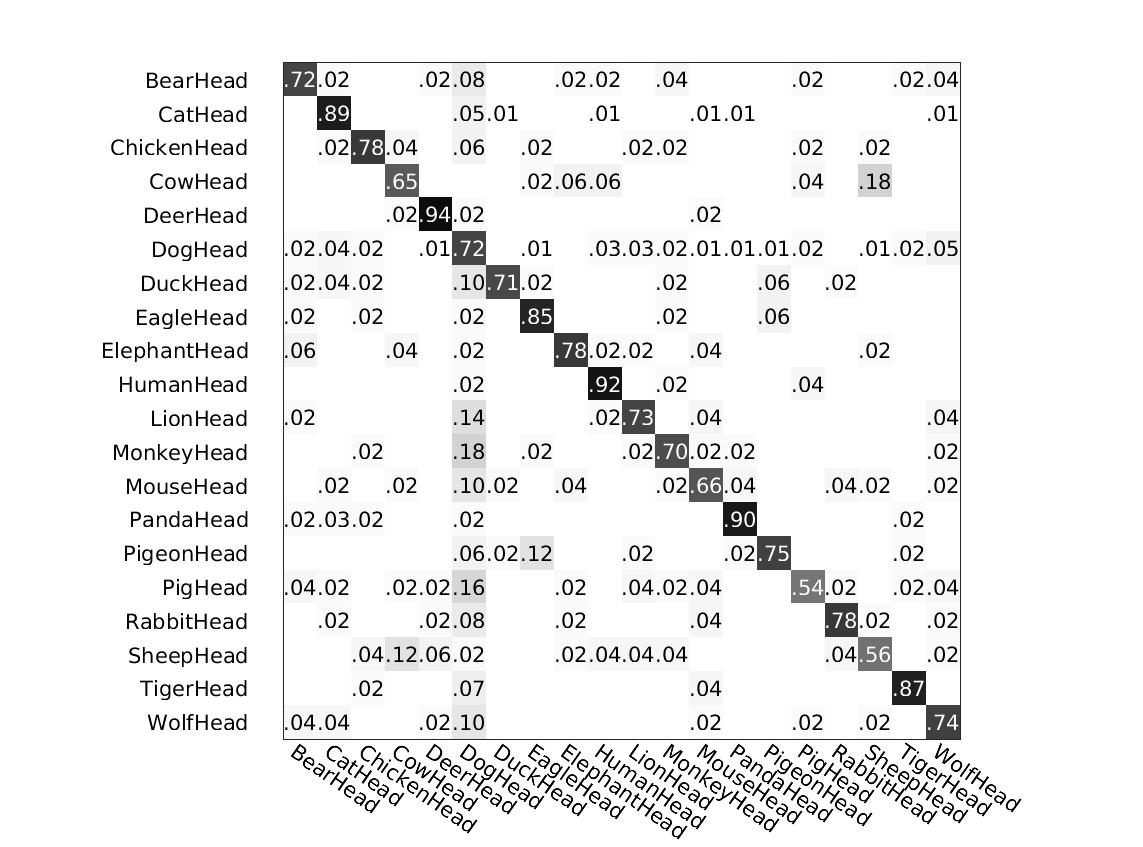
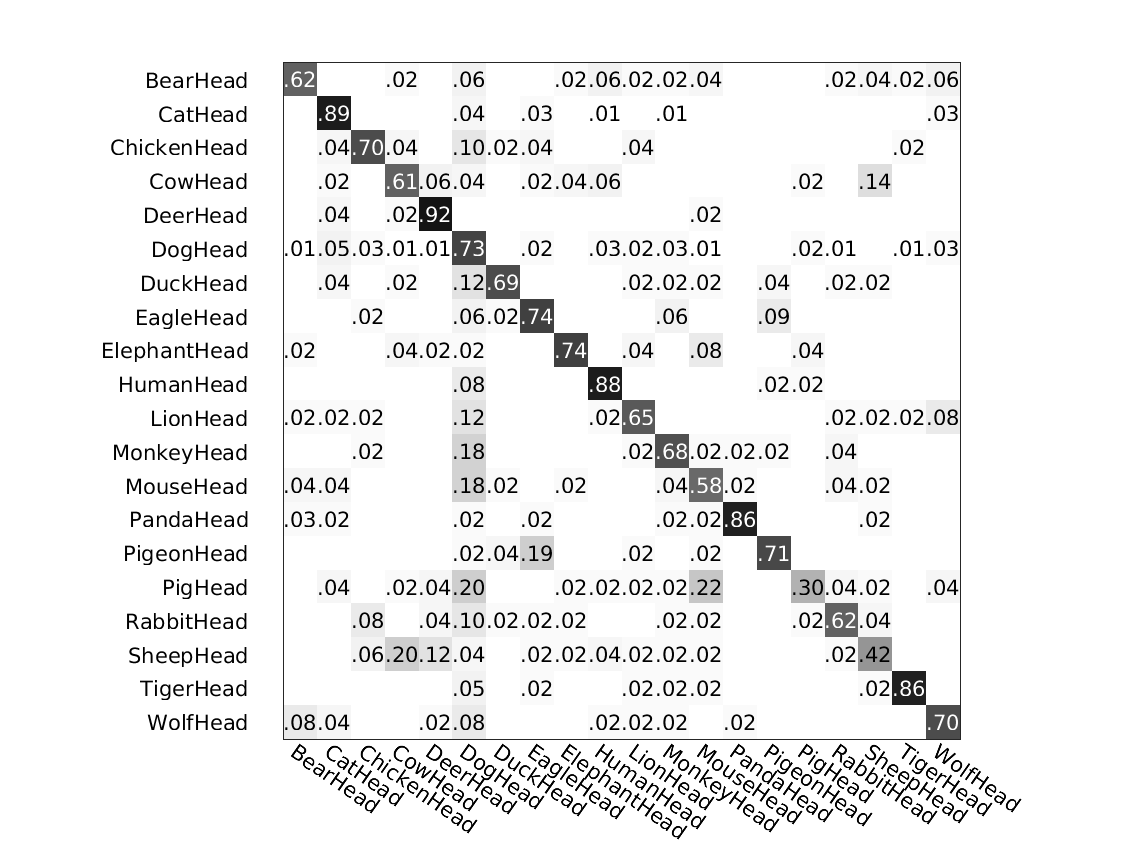
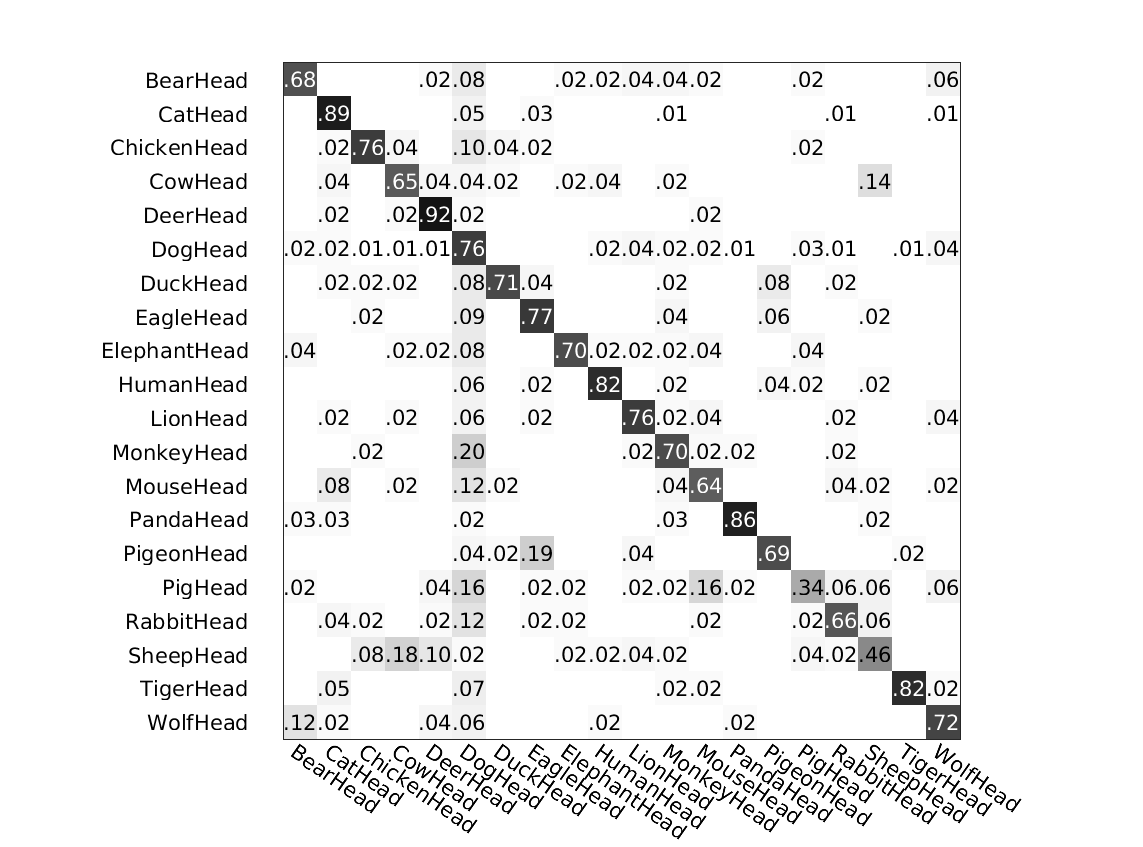
The following figure shows the confusion matrices of the above classifications by different methods.
Method 1: ours
Left: # clusters=5. Right: # clusters=11
Method 2: ours without parts
Left: # clusters=5. Right: # clusters=11
Method 3: And-Or Template
Left: # clusters=5. Right: # clusters=11