Our second set of experiments is on the LHI-Animal-Faces dataset [1], which consists of around 2200 images for 20 categories of animal or human faces. We randomly select half of images per class for training and the rest for testing. We learn a codebook of 10 sparse FRAME models for each category in unsupervised way. We then combine the codebooks of all the categories (in total 20 x 10 = 200 codewords). The maps of the template matching scores from the models in the combined codebook are computed for each image, and they are then fed into SPM, which equally divides an image into 1, 4, 16 areas, and concatenates the maximum scores at different image areas into a feature vector. We use multi-class SVM to train image classifiers based on the feature vectors, and then evaluate the classification accuracies of these classifiers on the testing data using the one-versus-all rule. Our classification rate is 79.4%. For comparison, Table 1 lists four published results [1] on this dataset obtained by other methods: (a) HoG feature trained with SVM, (b) Hybrid Image Template (HIT) [1], (c) multiple transformation invariant HITs (Mixture of HIT) [1], and (d) part-based HoG feature trained with latent SVM [2]. Our method outperforms the other methods in terms of classification accuracy on this dataset.
General Parameters: nOrient = 16; sizeTemplatex = 100;
sizeTemplatey = 100;
GaborScaleList = [0.7]; DoGScaleList = []; sigsq = 10; locationShiftLimit = 2; orientShiftLimit = 1; numSketch = 40; isGlobalNormalization = true; isLocalNormalize = true; minHeightOrWidth = 160x160;
HMC Parameters: lambdaLearningRate = 0.1/sqrt(sigsq);
epsilon = 0.03;
L = 10; nIteraton = 40; 12x12 chains;
Codebook Parameters: flipOrNot = false;
rotateShiftLimit = 1; allResolution = [0.8, 1, 1.2]; #EM iteration = 12; numCluster = 10; maxNumClusterMember = 50; LocationPerturbationFraction = 0.4;
HoG+SVM |
HIT |
Mixture of HIT |
Part-based LSVM |
Our method |
70.8 |
71.6 |
75.6 |
77.6 |
79.4 |
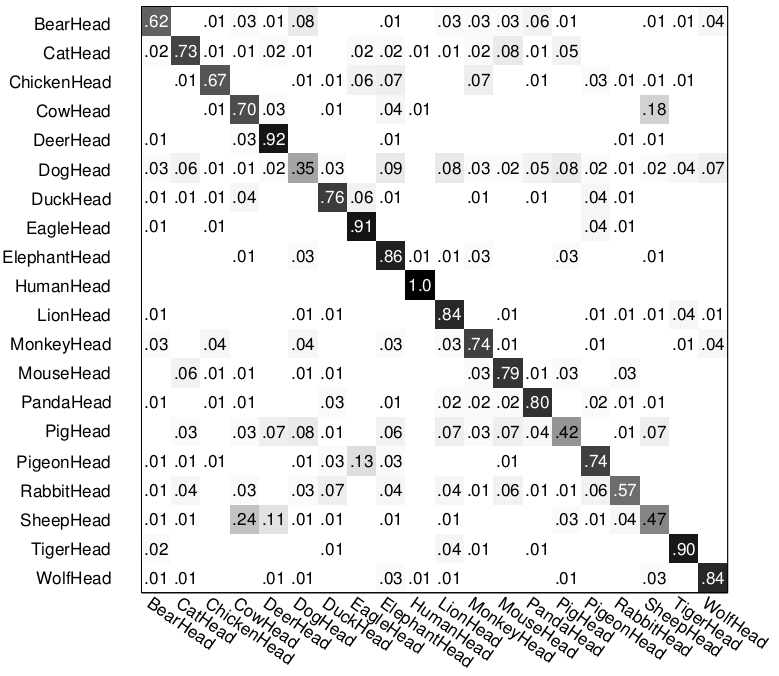
The following figure shows the confusion matrix of multi-class classification by our method, the top two confusions are caused by (1) sheep head vs. cow head, and (2) pig head vs. dog head.
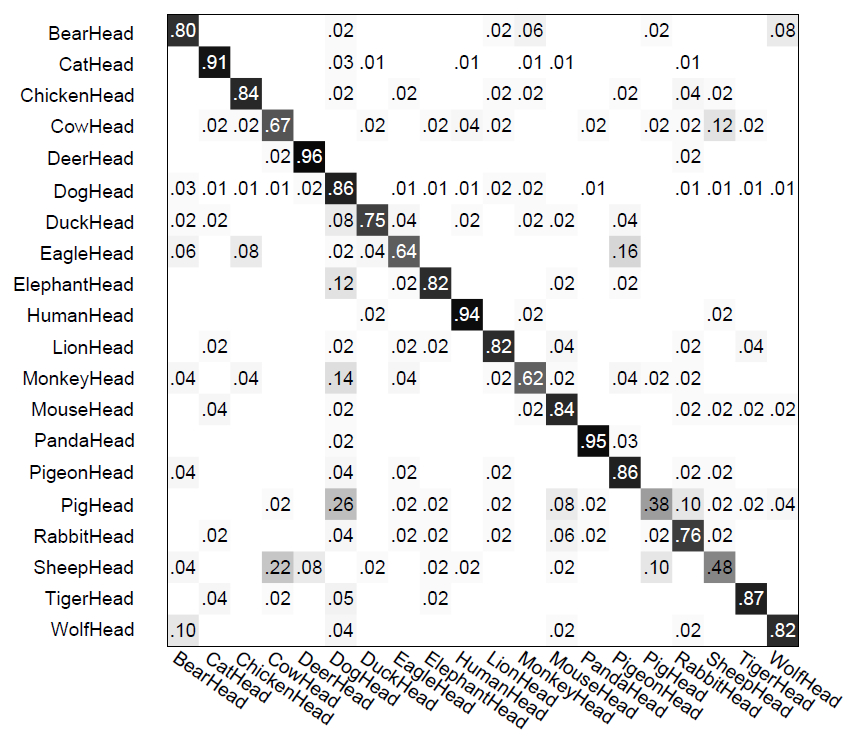
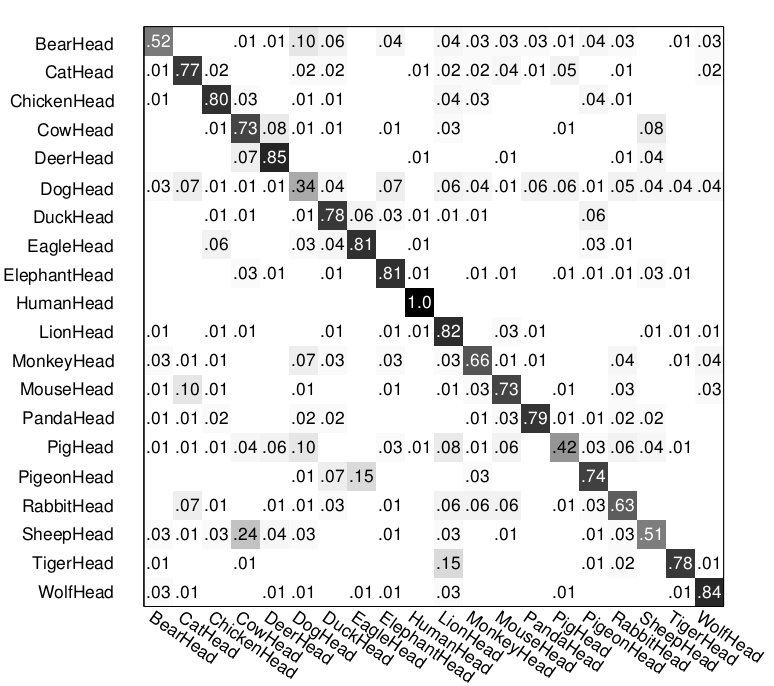
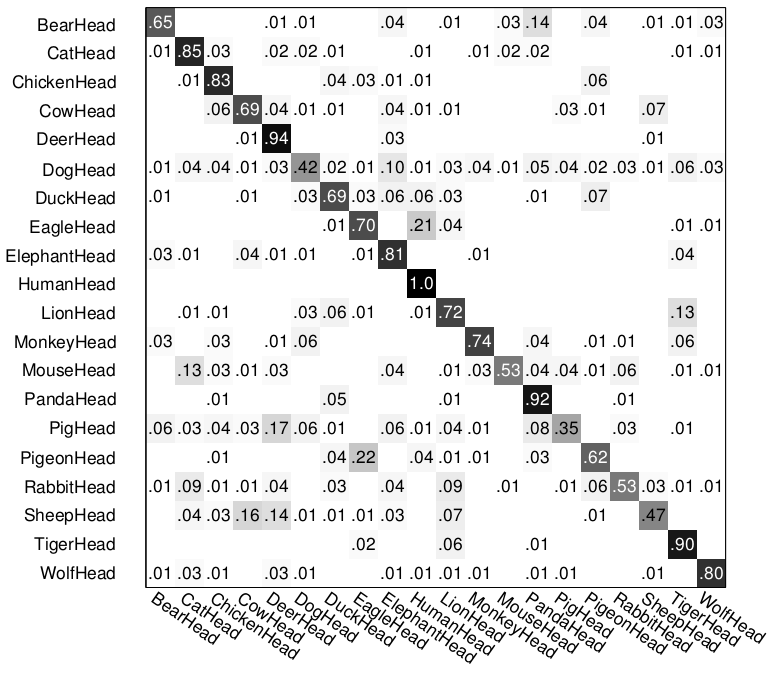
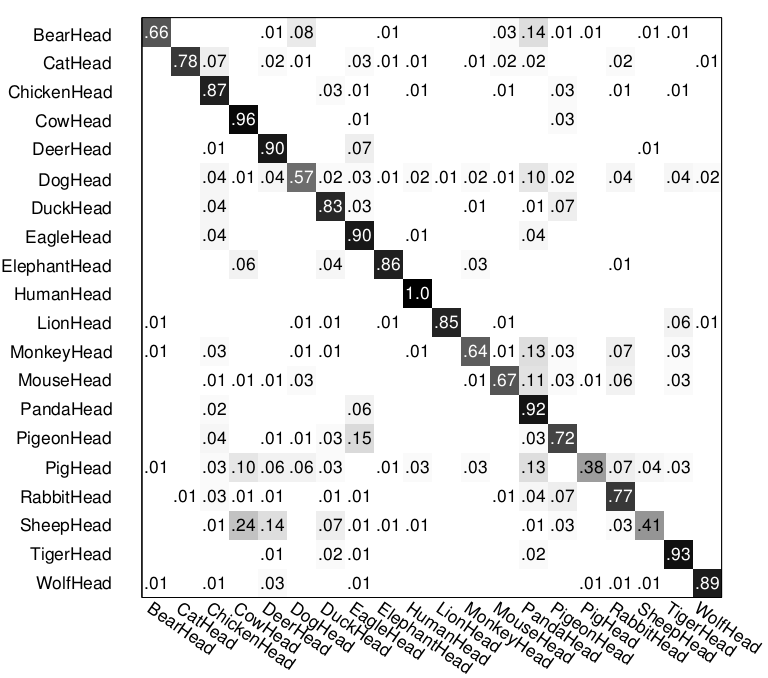
For comparison, confusion matrices of multi-class classification by other methods are listed as follows. They are from the project page of paper [1].
(1) Top left: Mixture of HIT; (2) Top right: HIT; (3) bottom left: HOG+SVM; (4) bottom right: LSVM