Seeing what through why: Probing the causal structure of hierarchical motion
Abstract
Although our world is hierarchically organized, the perception, attention, and memory of hierarchical structures remain largely unknown. The current study shows how a hierarchical motion representation enhances the inference of an object’s position in a dynamic display. The motion hierarchy is formed as an acyclic tree in which each node represents a distinctive motion component. Each individual object is instantiated as a node in the tree. In a position inference task, participants were asked to infer the position of a target object, given how it moved jointly with other objects. The results showed that the inference is supported by the context formed by nontarget objects. More importantly, this contextual effect is (a) structured, with stronger support from objects forming a hierarchical tree than from those moving independently; (b) degreed, with stronger support from objects closer to the target in the motion tree; and (c) directed, with stronger support from the target’s ancestor nodes than from its descendent nodes. Computational modeling results further indicated that the contextual effect cannot be explained by correlated and contingent movements without an explicit causal representation of the motion hierarchy. Together, these studies suggest that human vision is a type of intelligence, which sees what are in the dynamic displays by recovering why and how they are generated.
Demo
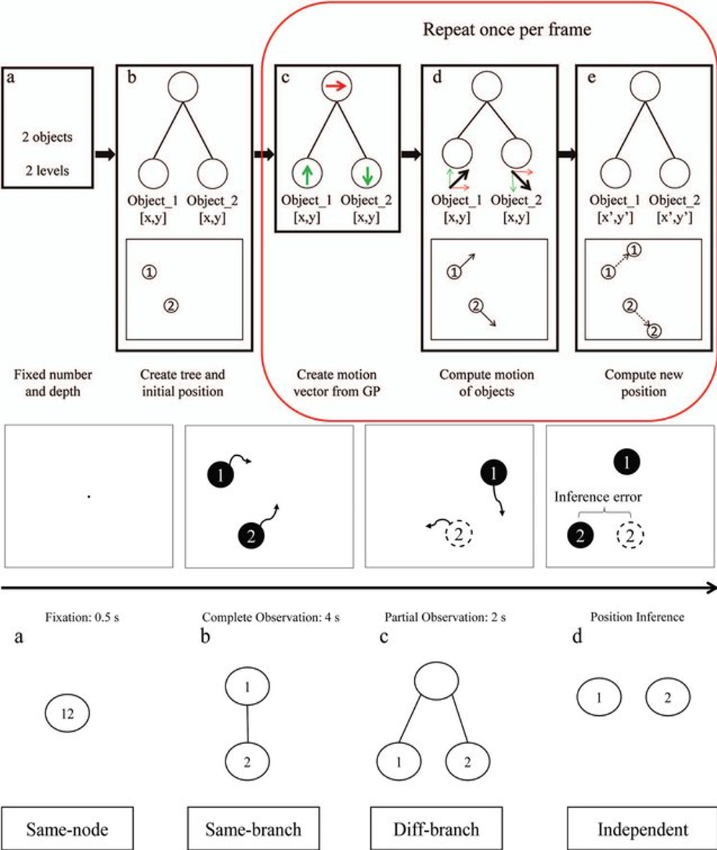
Illustration of generating motion by hierarchy tree and illustration of one trial