Energy-based Continuous Inverse Optimal Control
Yifei Xu 1,
Jianwen Xie 2,
Tianyang Zhao
1,
Chris Baker
3,
Yibiao Zhao
3,
and Ying Nian Wu
2
1 University of California, Los Angeles (UCLA), USA
2 Baidu Research USA, Santa Clara, USA
3 iSee Inc., Cambridge, USA
Abstract
The problem of continuous optimal control (over finite time horizon) is to minimize a given cost function over the sequence of continuous control variables. The problem of continuous inverse optimal control is to learn the unknown cost function from expert demonstrations. In this article, we study this fundamental problem in the framework of energy-based model, where the observed expert trajectories are assumed to be random samples from a probability density function defined as the exponential of the negative cost function up to a normalizing constant. The parameters of the cost function are learned by maximum likelihood via an ``analysis by synthesis'' scheme, which iterates the following two steps: (1) Synthesis step: sample the synthesized trajectories from the current probability density using the Langevin dynamics via back-propagation through time. (2) Analysis step: update the model parameters based on the statistical difference between the synthesized trajectories and the observed trajectories. Given the fact that an efficient optimization algorithm is usually available for an optimal control problem, we also consider a convenient approximation of the above learning method, where we replace the sampling in the synthesis step by optimization. To make the sampling or optimization more efficient, we propose to train the energy-based model simultaneously with a trajectory generator via cooperative learning, where the trajectory generator is used to initialize the sampling step or optimization step of the energy-based model. We demonstrate the proposed methods on autonomous driving tasks, and show that it can learn suitable cost functions for optimal control.
Paper
The paper can be downloaded here.
The latex source of the paper can be downloaded at here.
Code and Data
The code can be downloaded here.
NGSIM can be downloaded here. You need to manually preprocessed the data in order to run the code. Run "ngsim_load.py" to preprocess the data.
Extra Experiments
Testing corner cases with toy examples
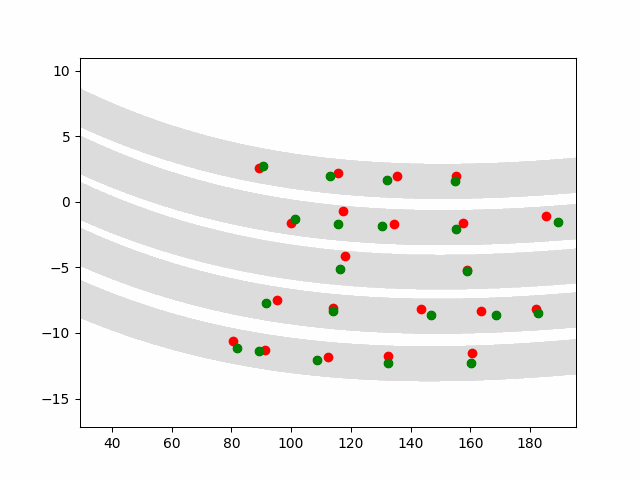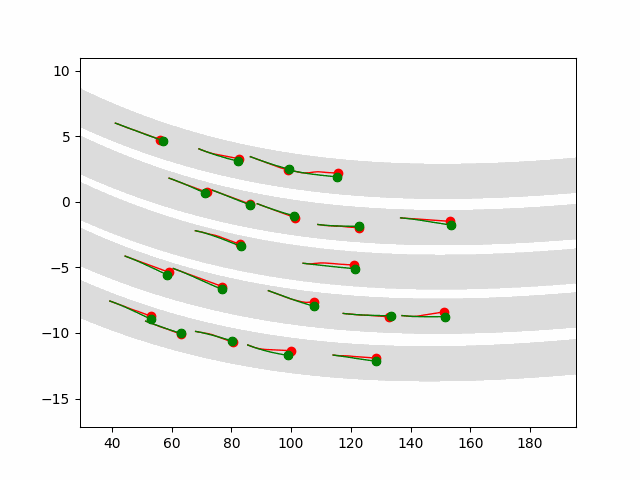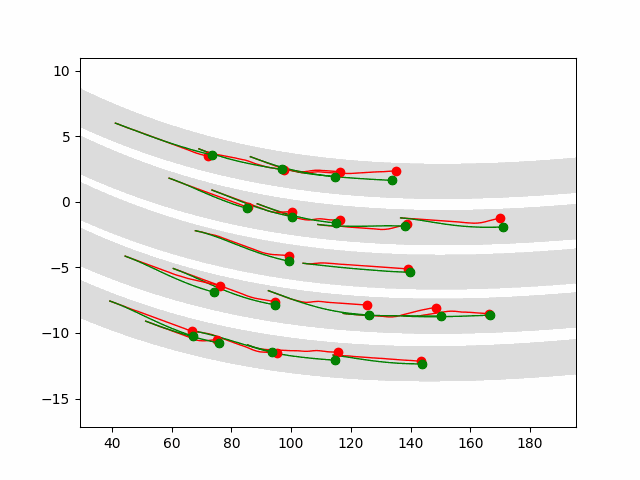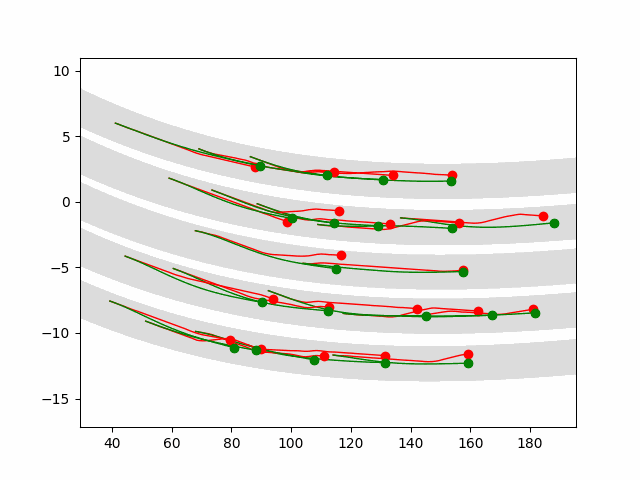
Here we provide animation gif for 6 corner cases. In gif animation, gray lane stands lane, green dot and lane is the predicted positon and trajectory; red lane is a reference lane whose control is set to zero; orange dot is the position for other vehicles. We can see that if we take no control, the vehicle will collision. Our predicted control avoid all collision.|
(a) Overtake due to front vehicle trigger break |
(b) Breaking with multiple other vehicle |
(c) Other vehicle cut in from right |
|
(d) Other vehicle cut in from left |
(e) Curve right |
(f) Curve left |
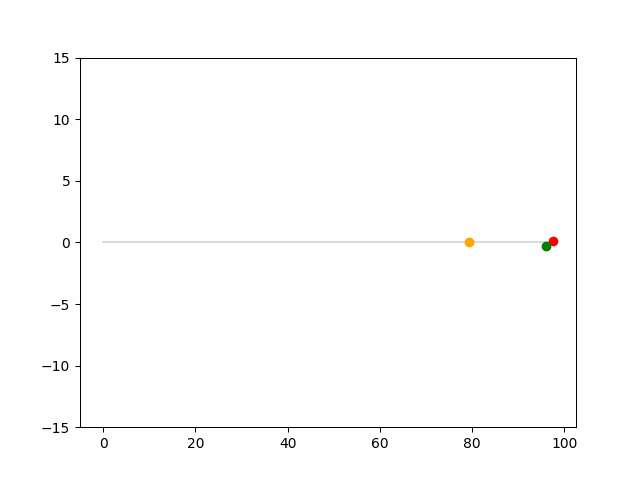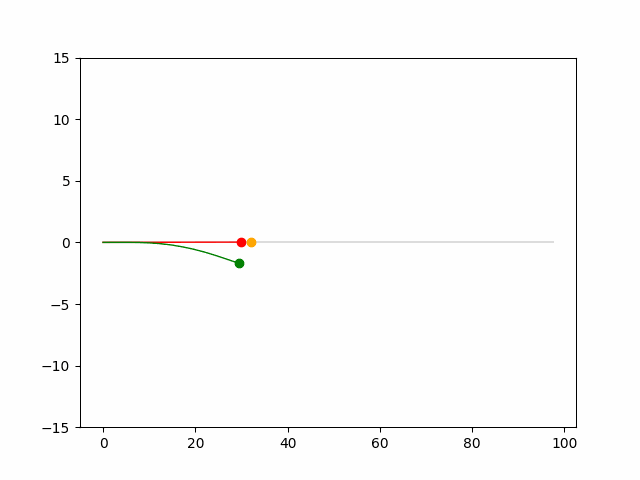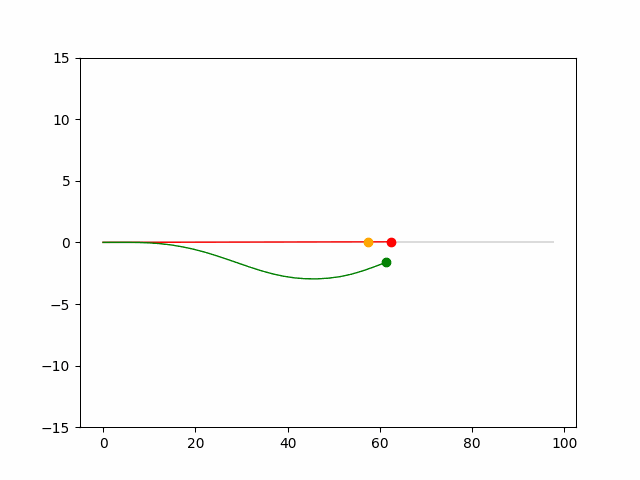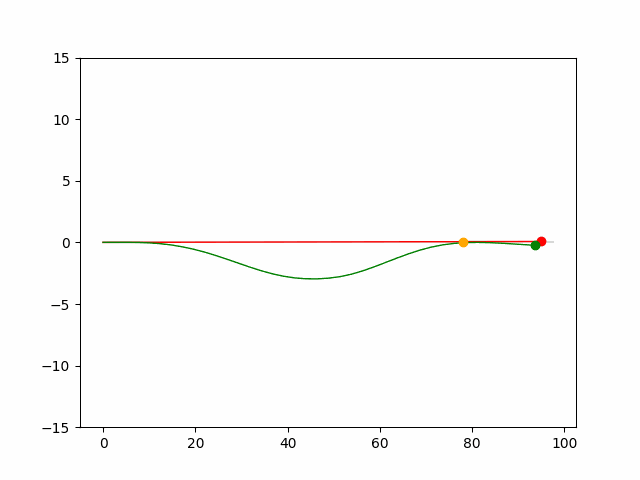
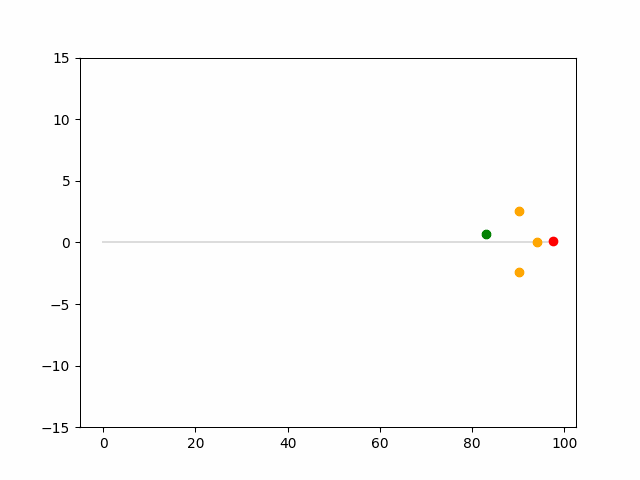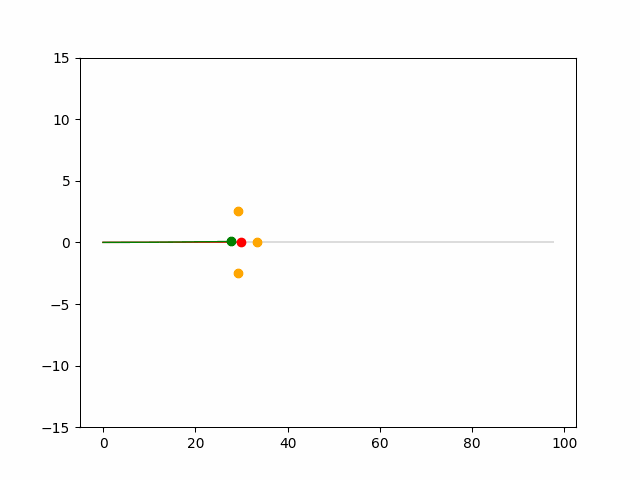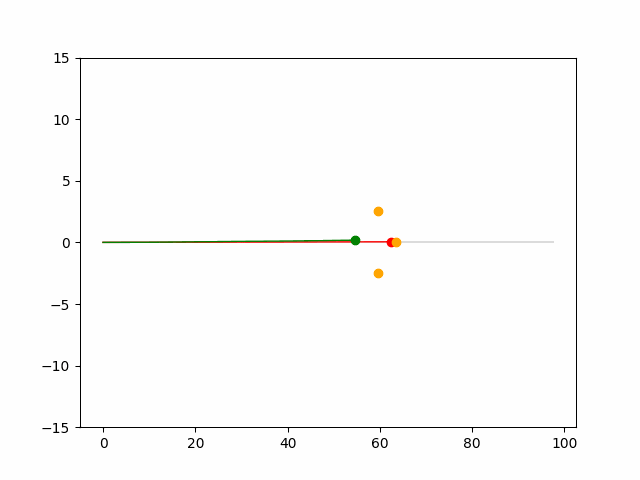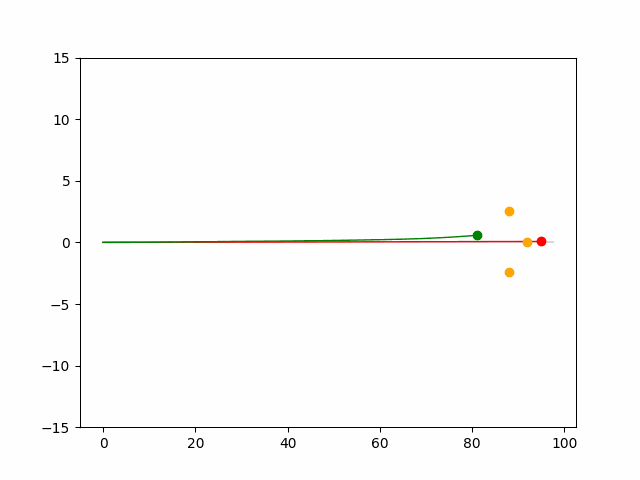
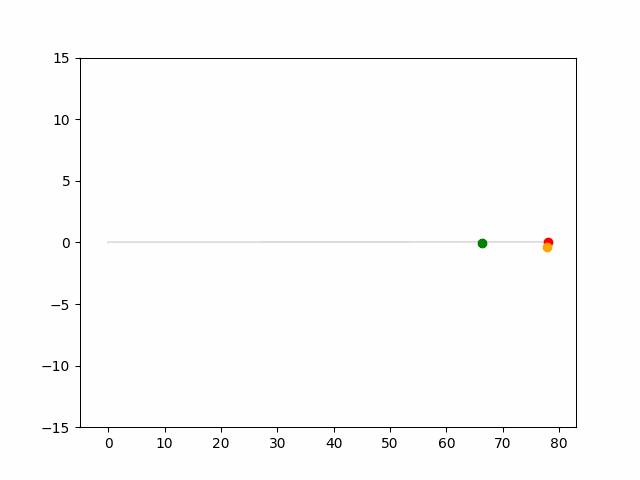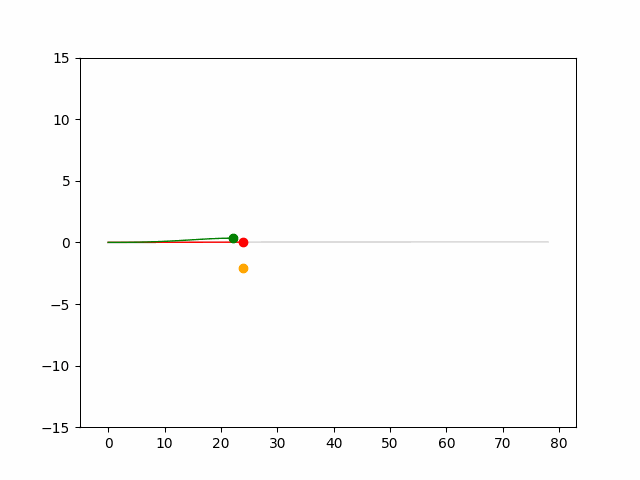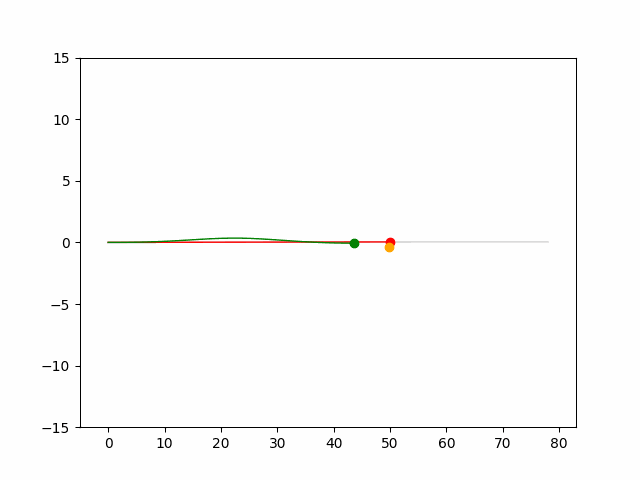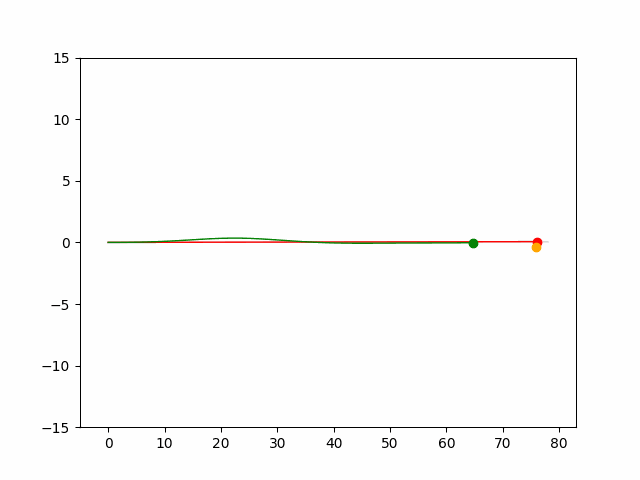
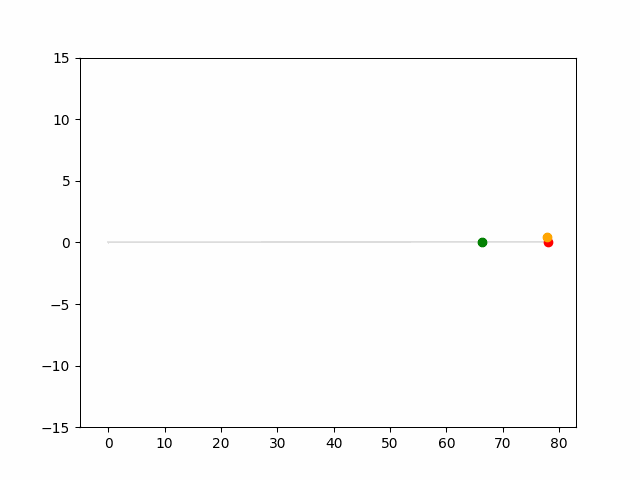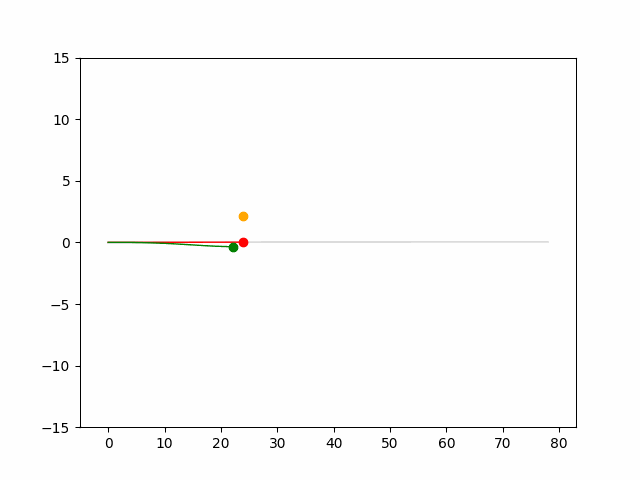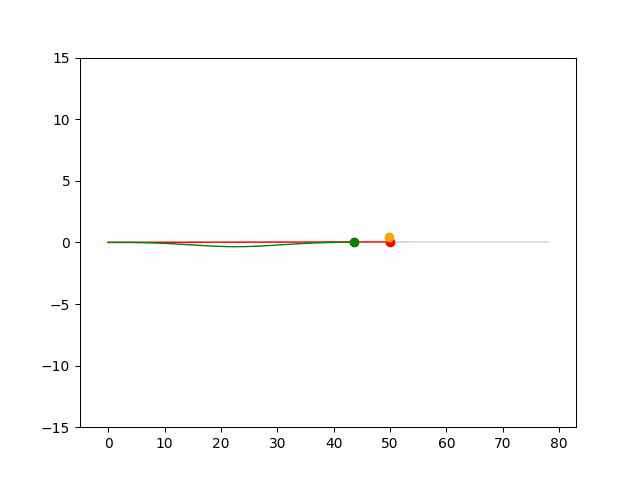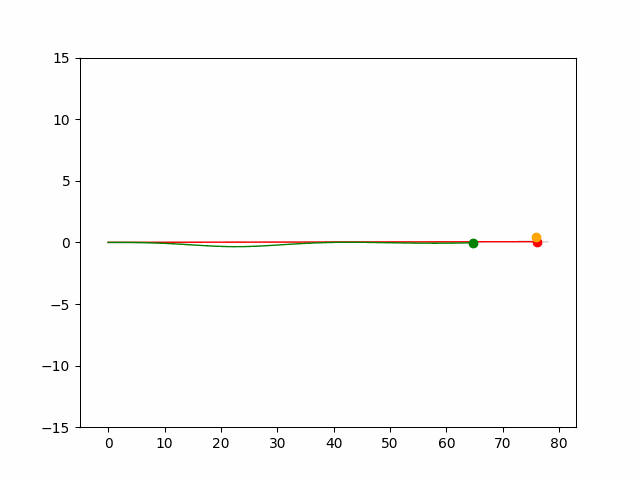
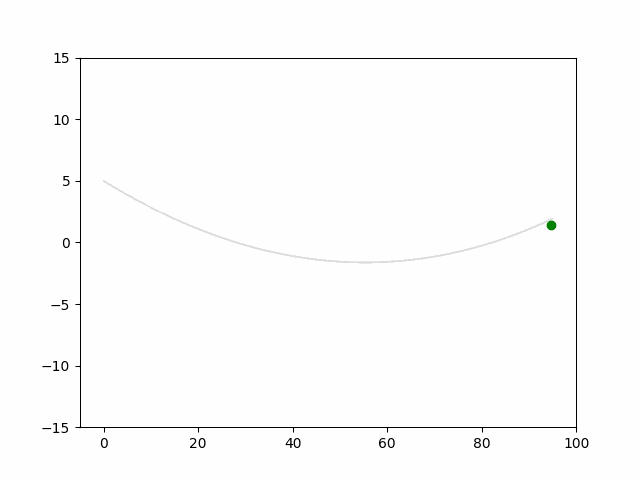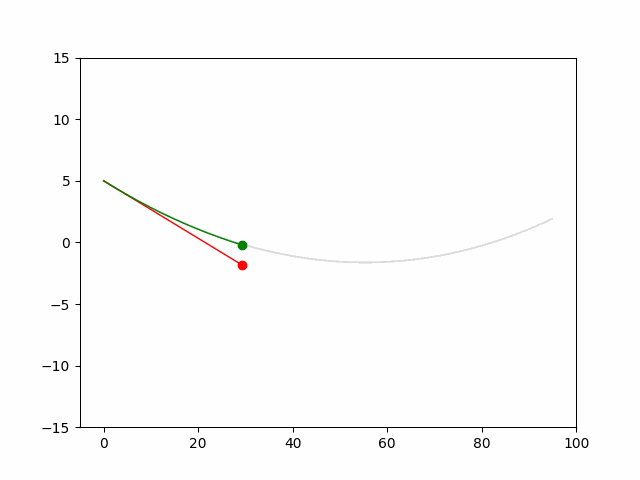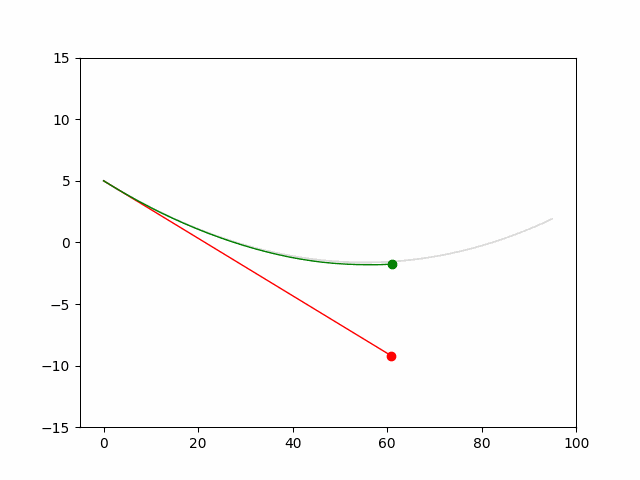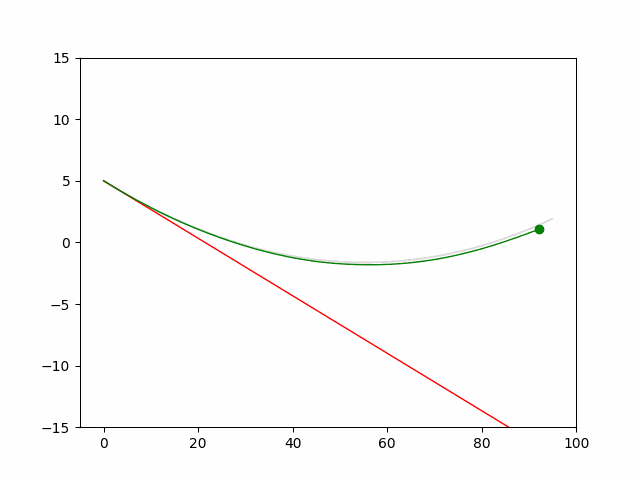
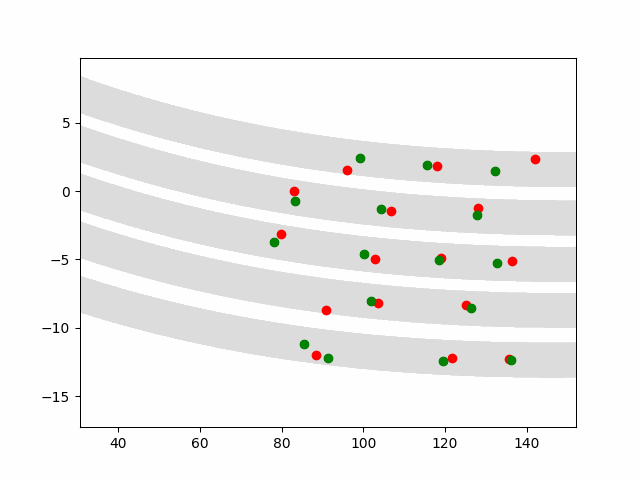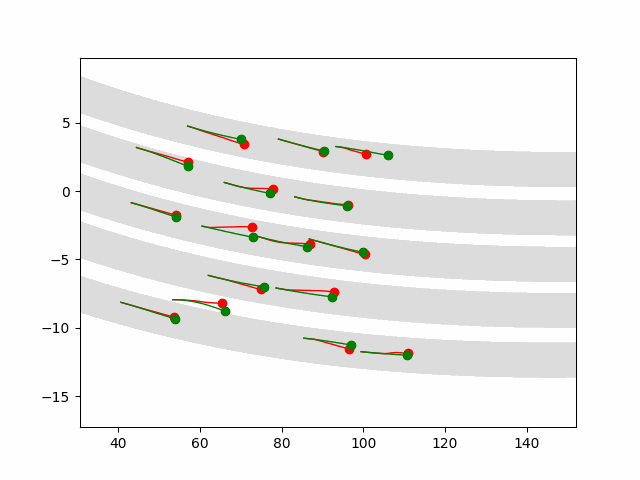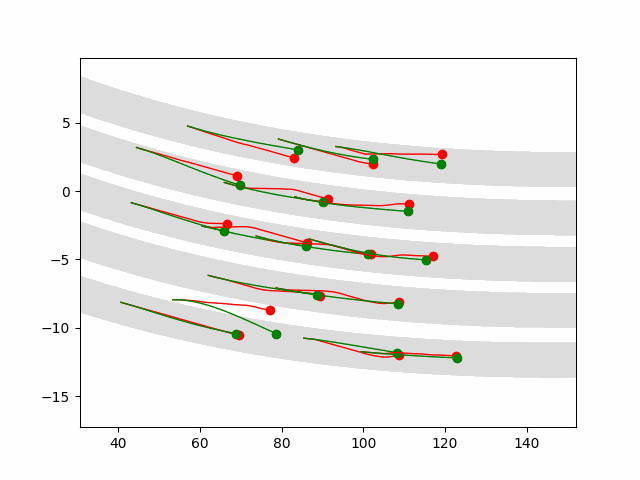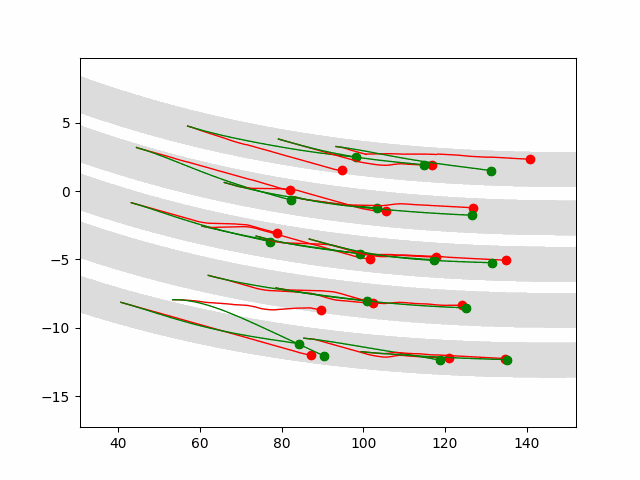
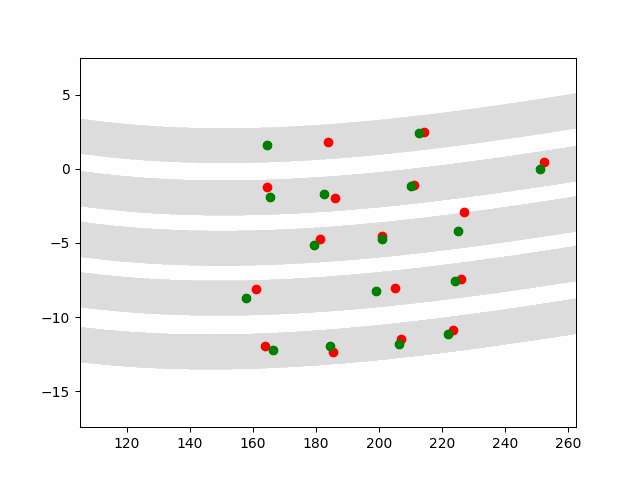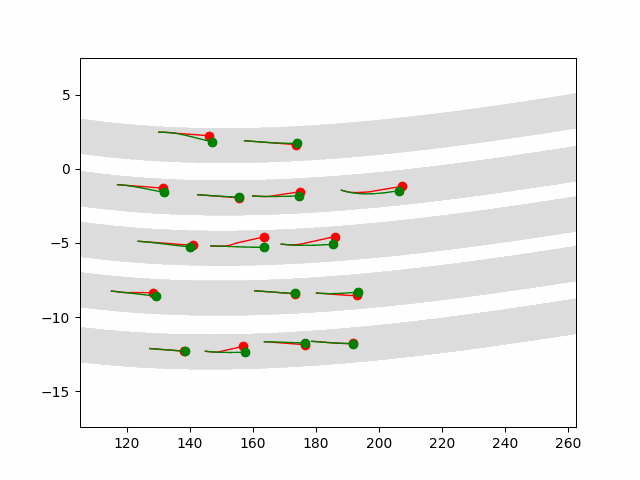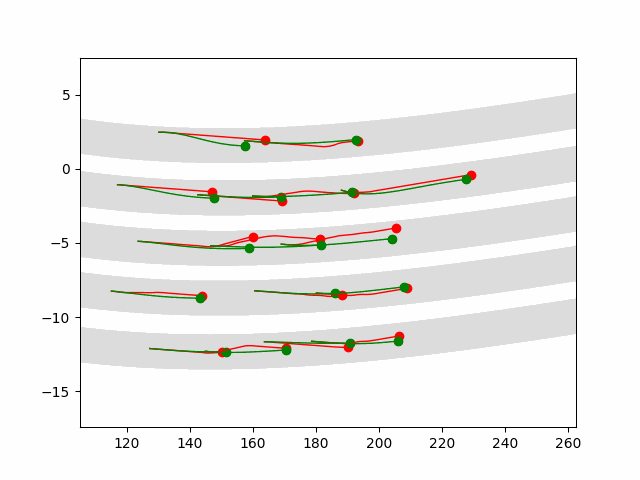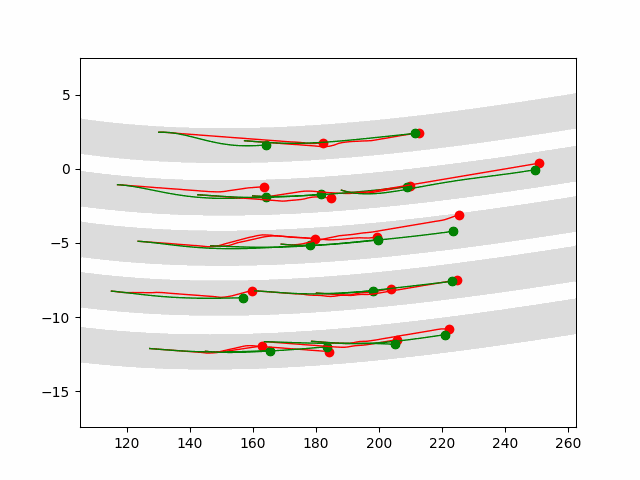
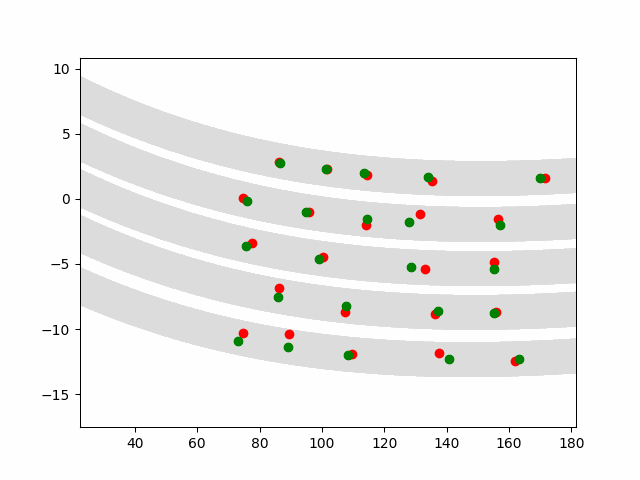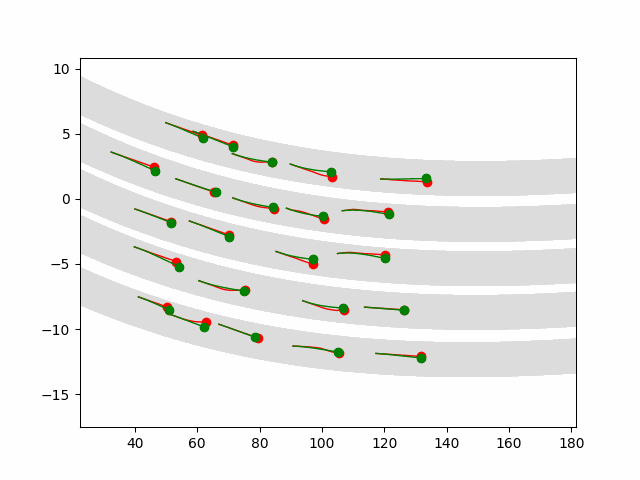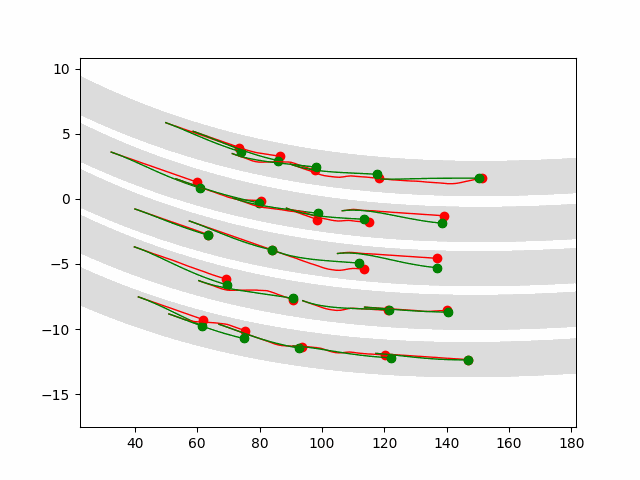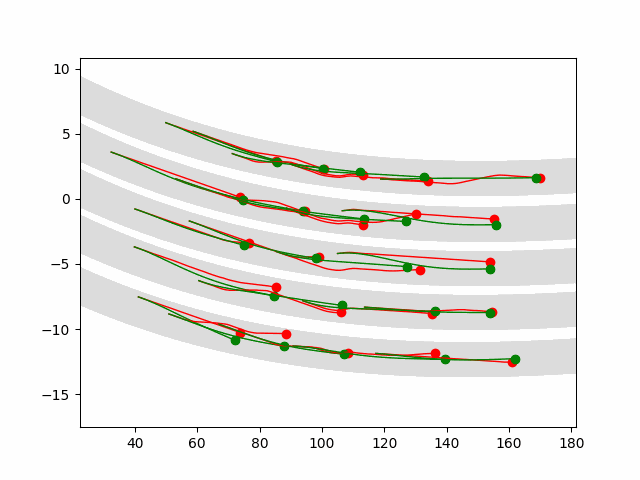
Multi-agent control result
Here we provide animation gif version for figure 5 in paper.