Experiment 9
Learning local representative templates
The local learning that is initialized from single image learning is opposite to
the EM algorithm that initialized from random clustering, see
page 1 and
page 2.
These two initialization schemes can be considered two extremes of
initializing EM-like learning. We now feel that initializing from
random clustering is preferrable.
See also
Experiment 17, which
allows local shifts of templates.
In experiment 9.1, we learn local representatives in an ensemble of 123 images of animal heads.
Around each image, we learn a template from this image and its K nearest neighbors, using an
iterative scheme based on the log-likelihood with sigmoid transformation. Specifically, we
first learn a template for this single image where no activity is allowed. Then using the learned
template, we find K nearest neighbors based on the likelihood score, where activity is restored.
After that we re-learn the template from these K nearest neighbors. In our experiment, K = 5.
Then again, we find the K-nearest neighbors, and iterate. After learning all the
templates, we trim them to satisfy the constraint that the neighbors of the remaining templates
should not overlap (this may be too aggressive). This leaves 15 templates.
(1)
data, codes, and readme for local learning based on sigmoid model (March 2009)

Experiment 9.1. The 15 representative templates locally learned by the sigmoid model.
They are ordered by the total likelihood scores. Image size is 100*100. Number of elements is 40.
Number of iteration is 3 for learning each template. The allowed activity of location is up to
2 pixels. The allowed activity of orientation is up to pi/15.
eps
The following are the 15 templates and their corresponding 5 nearest neighbors.
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
(1.1)
Code that pools q() from 2 large natural images (May 2009)
(1.2)
Code with local normalization (August 2009)

Experiment 9.1. The scale parameter is 1. The half window size for local
normalization of filter responses is 20. The image size is 150*150.
Number of elements is 40. The allowed activity of location is up to
3 pixels.
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
(1.3)
Code with self among the neighbors and with a weight (November 2009)
(2)
another example (March 2009)
(2.1)
Code that pools q() from 2 large natural images (May 2009)

Experiment 9.2. We use the images in Experiments 1.4 and 1.5, and the first 12
images in Experiment 3.2. The image length is 120. All the images share the same
central horizontal line. Number of elements is 60. All the other parameters are
the same as Experiment 9.1.
eps
The following are the 3 templates and their corresponding 5 nearest neighbors.
 eps
eps
 eps
eps
 eps
eps
(2.2)
Code with local normalization (September 2009)

Experiment 9.2. Filter responses are normalized with a local window whose half
size is 20x20. Scale parameter = .7. Number of elements is 45. All the other
parameters are the same as Experiment 9.1.
eps
The following are the 3 templates and their corresponding 5 nearest neighbors.
 eps
eps
 eps
eps
 eps
eps
(3)
data, codes, and readme for local learning of digits (June 1, 2009)

Experiment 9.4. The 21 templates locally learned by active correlation. Number of
images is 200, image size is 60*60. Original data (28*28) are taken from MNIST data set. Number of elements is 15.
Number of iteration is 3 for learning each template. The allowed activity of location is
up to 2 pixels. The allowed activity of orientation is up to pi/15.
eps
The following are the 21 templates and their corresponding 5 nearest neighbors.
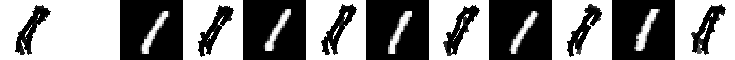 eps
eps
 eps
eps
 eps
eps
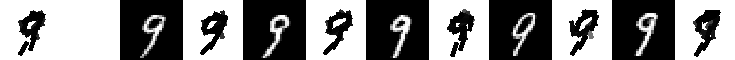 eps
eps
 eps
eps
 eps
eps
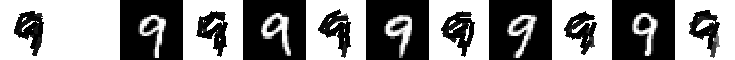 eps
eps
 eps
eps
 eps
eps
 eps
eps
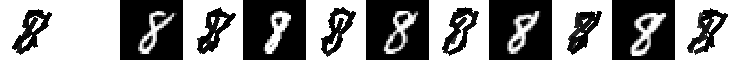 eps
eps
 eps
eps
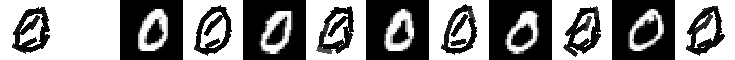 eps
eps
 eps
eps
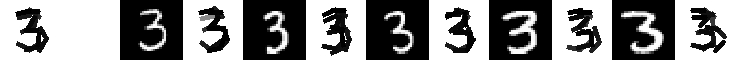 eps
eps
 eps
eps
 eps
eps
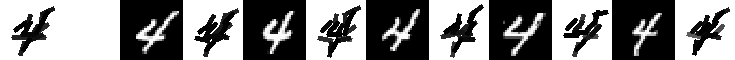 eps
eps
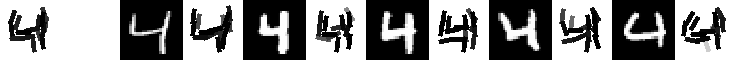 eps
eps
 eps
eps
 eps
eps
(4)
data, codes, and readme for local learning of horses (June 1, 2009)
 eps
eps
The 20 locally learned templates sequentially selected by maximizing a
truncated log-likelihood score. The 912 images are 84 $\times$ 105. The number
of nearest neighbors is 20.
The number of elements is 40. Other parameters are the same as in the
previous experiments.




















(4.1)
Code with local normalization of filter responses (September 2009)
 eps
eps
Half size of local window is 20x20.
The threshold for sequential selection is 90.
(5)
another example (August 2009)

eps
The following are the 5 templates and their corresponding 5 nearest neighbors.
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
(6)
Code with local normalization (August 2009)
Local normalization is necessary for the algorithm to avoid excessively sketching
the decorations on the cups.

eps
The following are the 4 templates and their corresponding 10 nearest neighbors.
 eps
eps
 eps
eps
 eps
eps
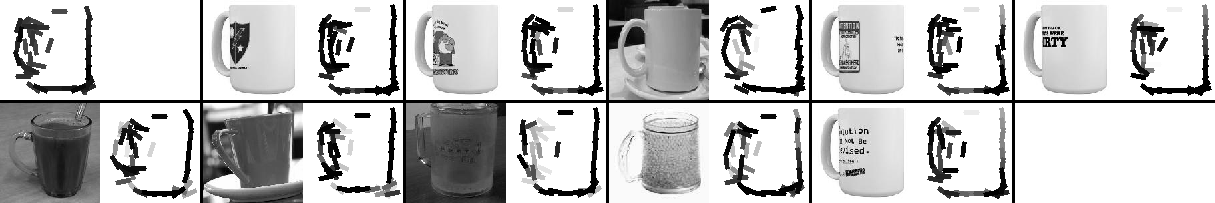 eps
eps
(7)
Code with local normalization (August 2009)

eps
The following are the 5 templates and their corresponding 10 nearest neighbors.
 eps
eps
 eps
eps
 eps
eps
 eps
eps
 eps
eps
Past results and code
The code below is not nearly as efficient as the current code posted above. It performs
unnecessary inhibition steps on all the images in learning. We keep it just for our own record.
In experiment 9 (outdated), we learn local representatives in an ensemble of 123 images of animal heads.
Around each image, we learn a template from this image and its K nearest neighbors, using an
iterative scheme based on the active correlation. Specifically, we first learn a template for
this single image where no activity is allowed. Then using the learned template, we find K
nearest neighbors by active correlation, where activity is restored. After that we re-learn the
template from this image and its K nearest neighbors. The weight for each of the K nearest
neighbors is 1, whereas the weight for this image is $\rho K$. In our experiment, K = 5, and
$\rho$ = 1/3. Then again, we find the K-nearest neighbors, and iterate. After learning all the
templates, we trim them to satisfy the constraint that the neighbors of the remaining templates
should not overlap (this may be too aggressive). This leaves 16 templates.
The local learning identifies the local dimensions and local "metric" in the image ensemble.
(1)
data, codes, and readme for local learning based on active correlation
(1.1)
data and codes based on likelihood
(1.2)
results of k-mean clustering intialized by local learning
The last two clusters are removed because each of them only contains one image.
(2)
another example
results of k-mean clustering
Again we use the learned templates to initialize k-mean. We did not perform merging.
All the 200 templates
Listed in the descending order of active correlation scores.
Back to
active basis homepage