Clustering from random initialization, allowing local shift (of location, scale, orientation and flip) of templates
The clustering is model-based (mixture of active basis models). It does NOT require or rely on pairwise similarity meausre.
We initialize the EM-like algorithm from random clustering, and we allow for
multiple random starting. We now feel that random clustering is the least
biased and most convincing starting point for finding clusters in the
images. The initial templates are similar and often not meaningful if the
clusters are very different from each other. Then the algorithm starts a
polarization process, so that the templates become more different from each
other and move towards different clusters.
It is fair to say that all the latent variable models used for unsupervised
learning are different versions of mixture models (sometimes continous
mixtures or scale mixtures). Discovering mixture components is the key to
unsupervised learning. Such mixtures correspond to the OR-nodes in the And-Or
graph advocated by Zhu and Mumford for vision.
The difficulty with mixture model in particular and unsupervised learning
in general is that the likelihood function is not concave and can be highly
multi-modal. So learnability in unsupervised learning is not only about
sample size, but also about whether the algorithm can locate the major modes
from random initialization. Of course, the two issues appear to be related.
For large sample, the likelihood may be less rugged.
Car |
Multiple starting



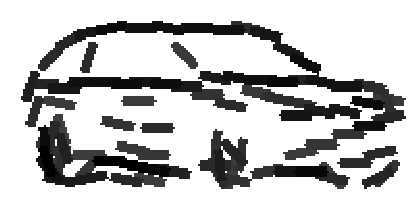

Horse |
Multiple starting


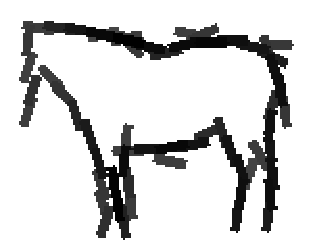






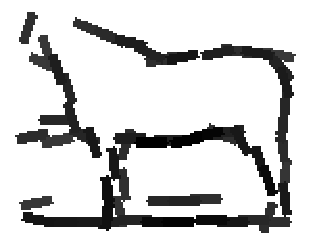

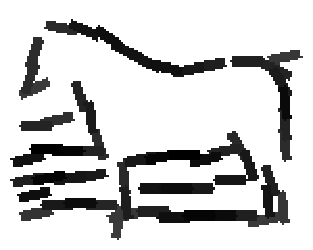



Horse (remove those images with fences)
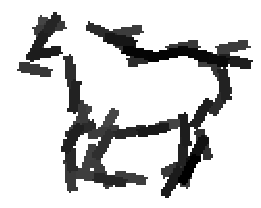









People



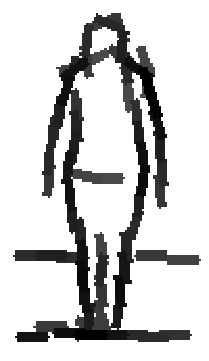
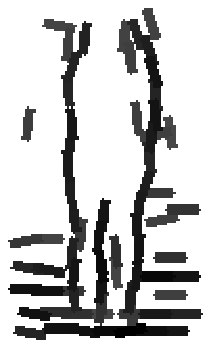
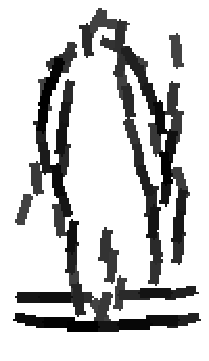
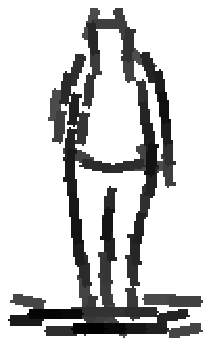
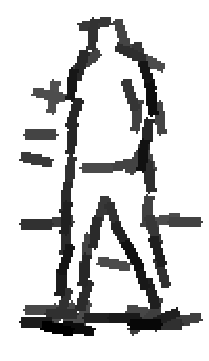
Six animals
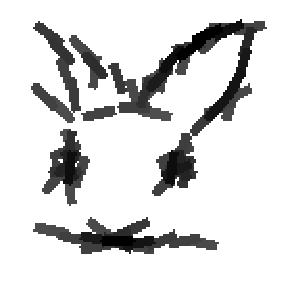

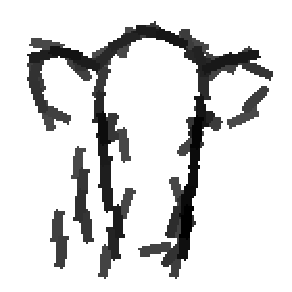



Cat and wolf


Cow

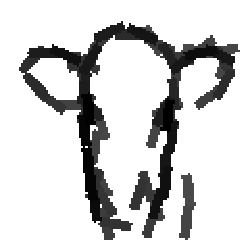
Cow and deer


Bear


Lion
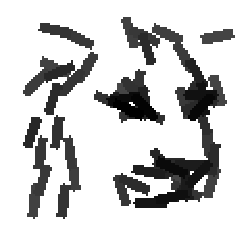

bear and wolf
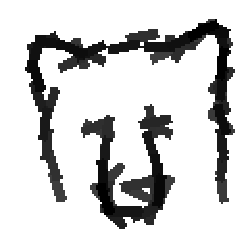

Bear, cattle, cat and wolf |
Multiple starting

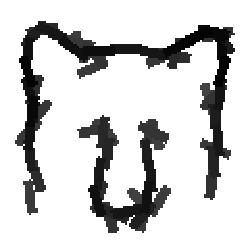


Rabbit


Pig

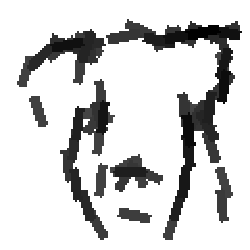
Dog
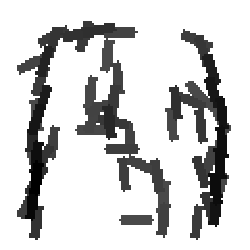



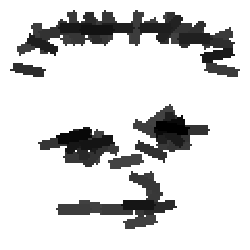
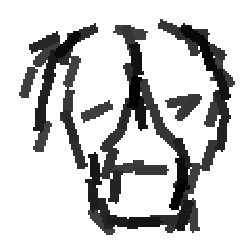
Pigeon and duck |
Multiple starting

Eagle


Clock


Teapot and cup


MNIST digits



















Back to active basis homepage