Note: Below were experiments done at the early stage of this project.
See THIS PAGE for more recent experiments where local shift leads to cleaner templates.
Learning Active Basis Models from Aligned Images
Note: The parameters in the following experiments are slightly different
from those in
IJCV reproducibility page













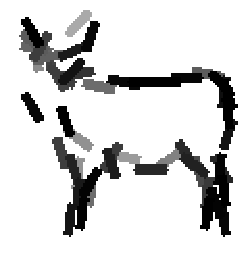
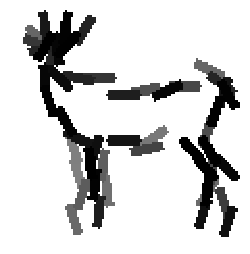







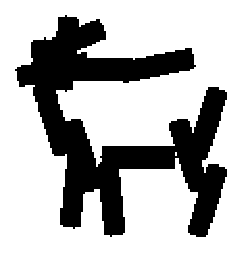










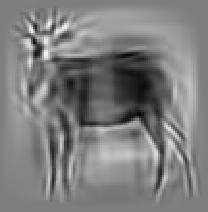
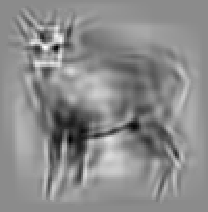
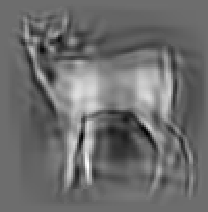

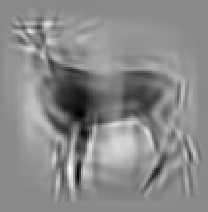
Code for synthesis
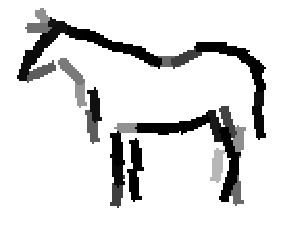
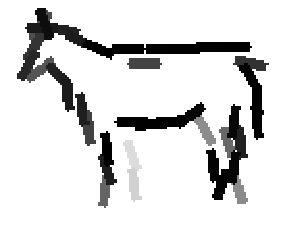
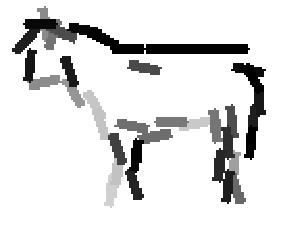
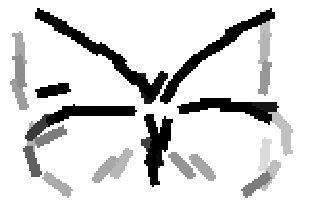
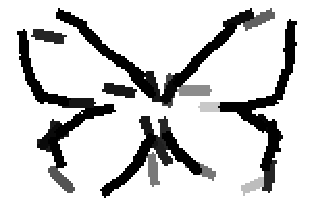
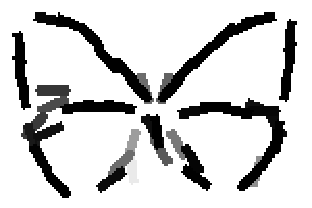
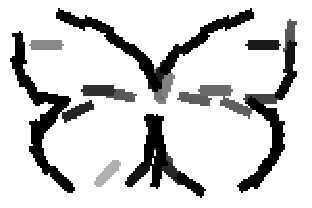
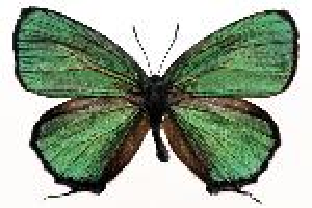
The first row displays the training images (displayed in color for visual clarity,
although the algorithm works on grey level images).
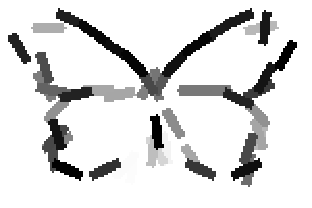
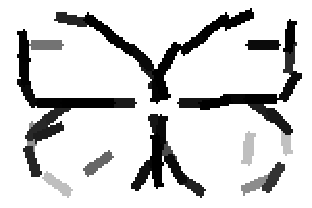
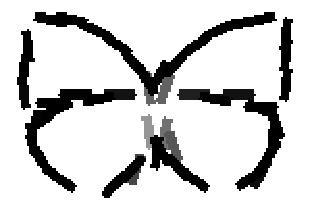
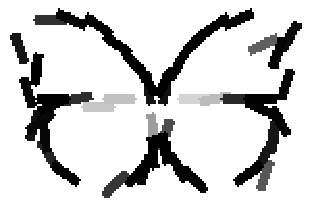
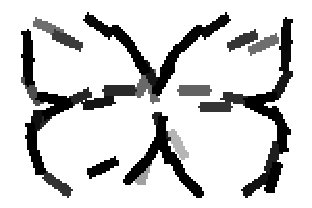
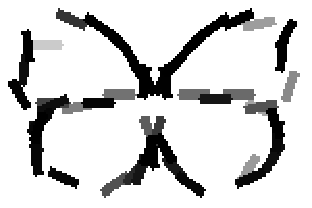
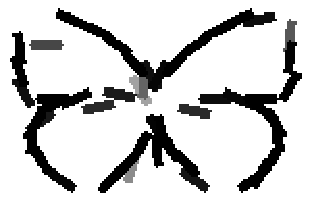
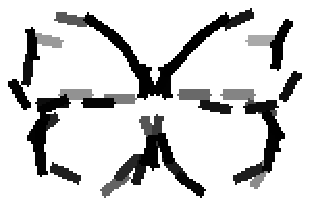
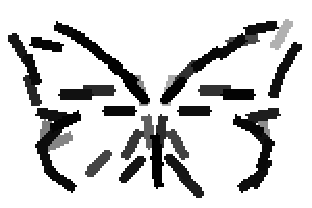
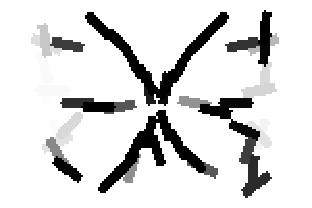
The second and third rows display the learned templates at two different
scales, with the scale in the third row about twice the scale in the second
row. In each of the second and third rows, the first template is the common
template, and the rest are the deformed templates to match the training images.
The number of elements in the templates of the second row is 50. The number of
elements in the templates of the third row is 14.
The fourth row displays the reconstructed images by linearly combining 100
wavelet elements at different scales.
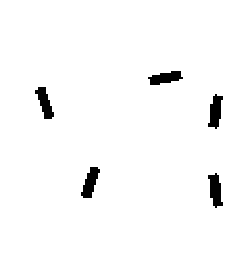
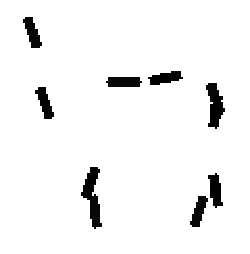
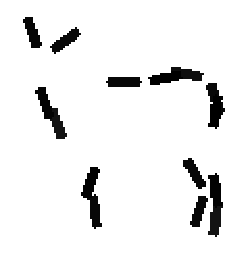
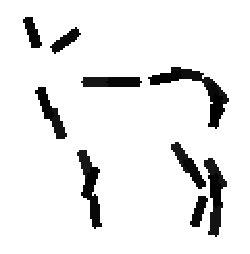
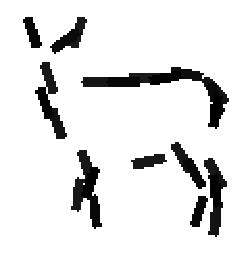
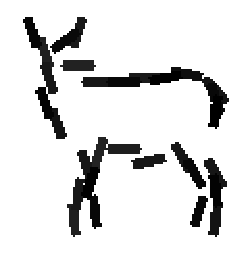
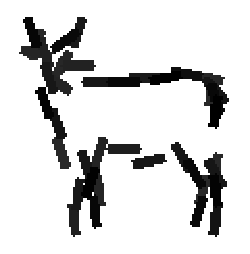

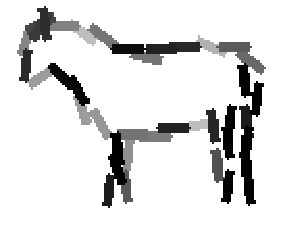
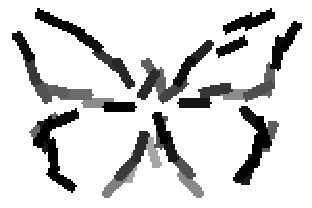
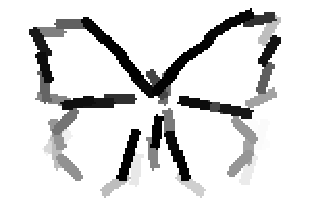
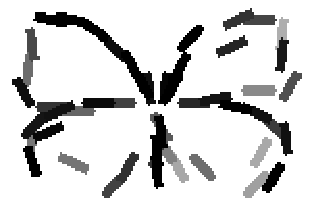
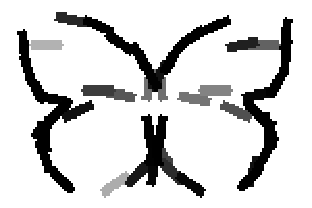
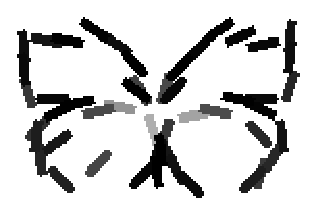
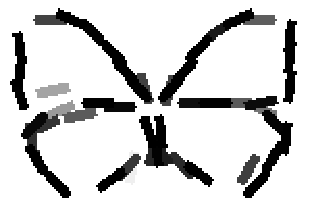
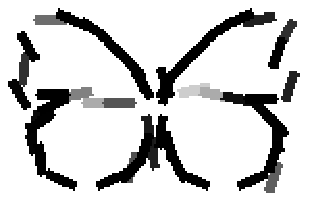
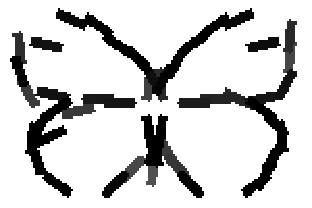
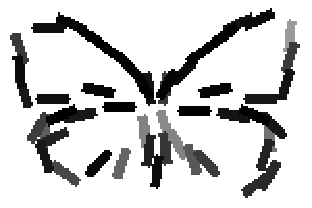
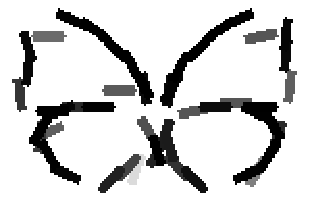
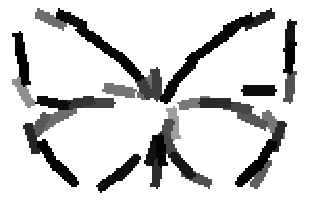
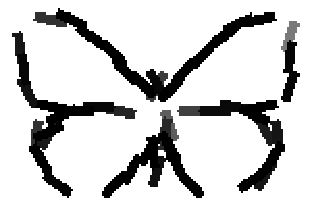
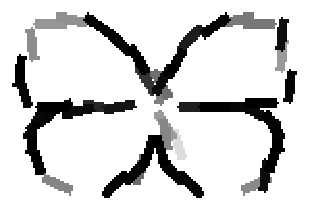
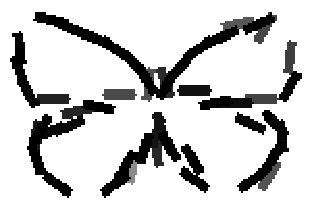
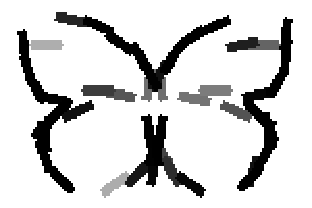
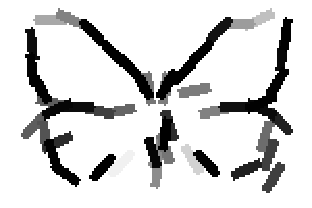
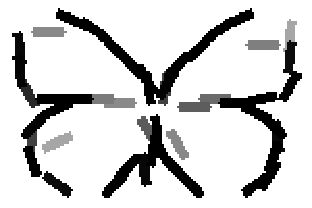
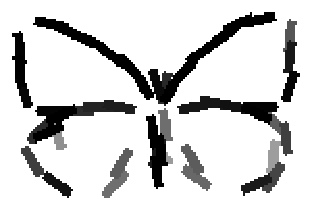
The learned templates with 5, 10, 15, 20, 25, 30, 40, 50 basis elements.
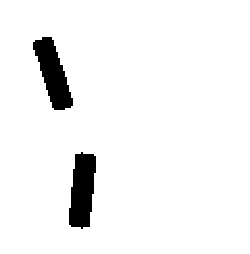
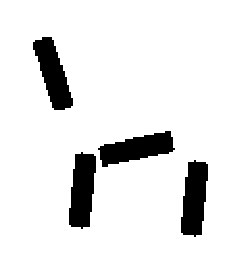
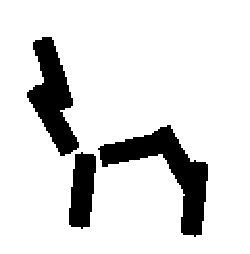




The learned templates with 1, 2, 4, 6, 8, 10, 12, 14 basis elements, at a larger
scale. code




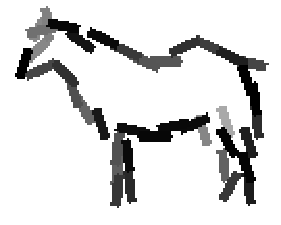
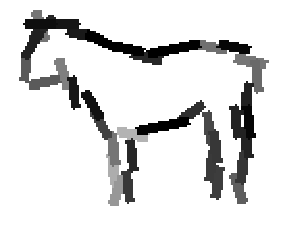
Detecting and sketching the objects in the testing images using the template learned at
the smaller scale.
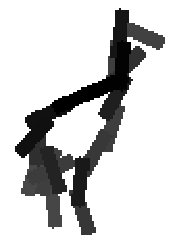


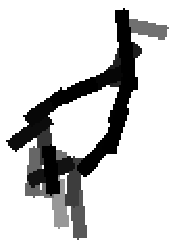

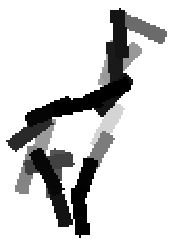

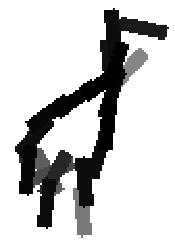

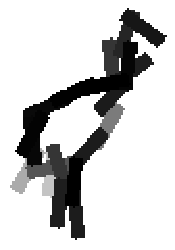



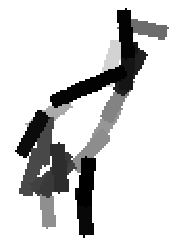


























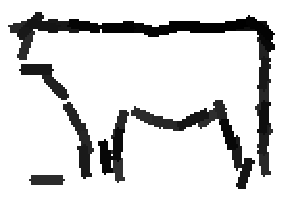








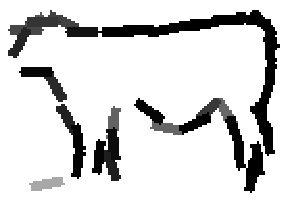



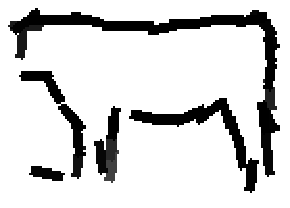











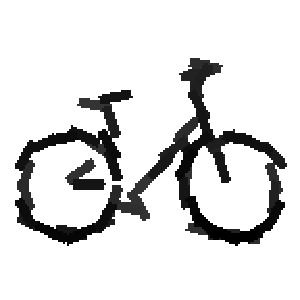








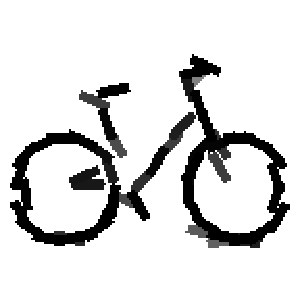

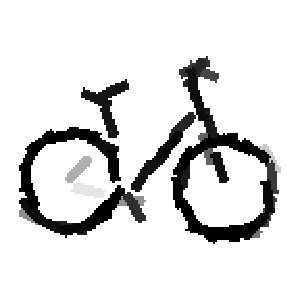

















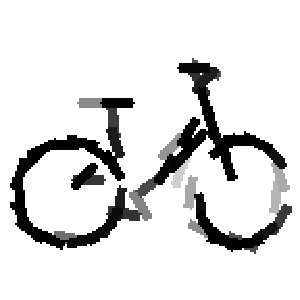









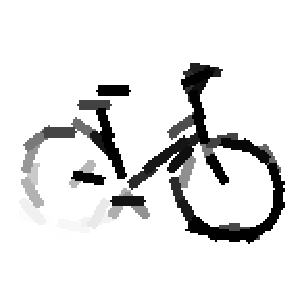

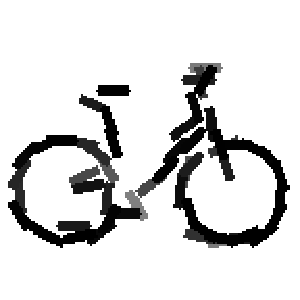





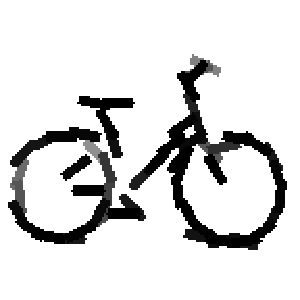








Flatness features by local average of filter responses after local
normalization and sigmoid transformation.
code for flatness features



The window for local average is 1x1, 9x9, 17x17, 25x25 respectively.
eps0
4
8
12






































































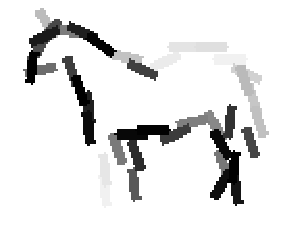
































































































































































































































































































































































































































































































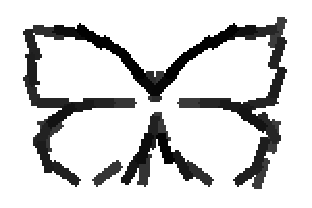




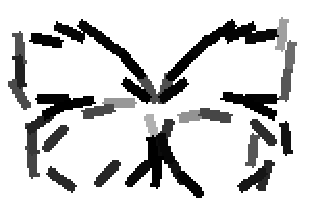

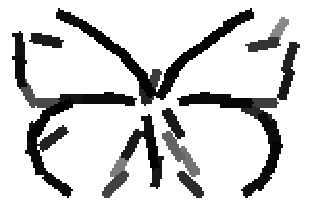





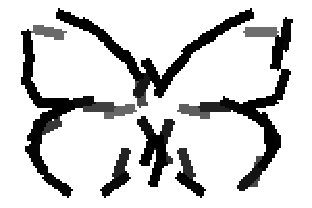

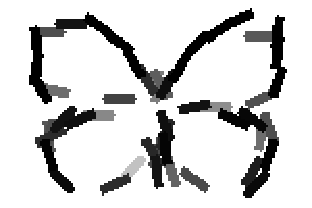





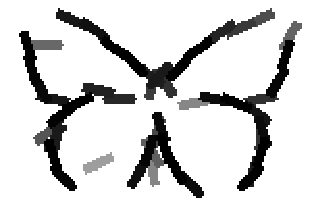

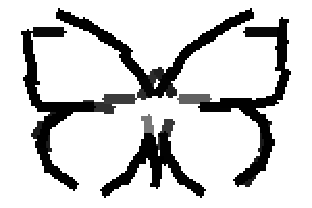

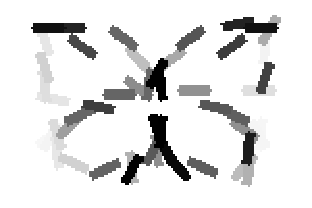



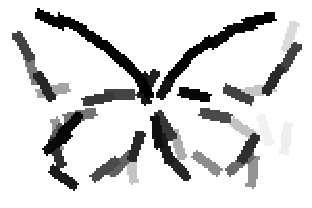







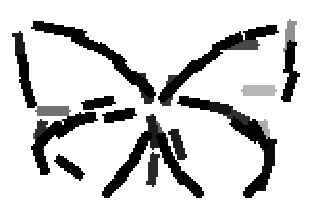



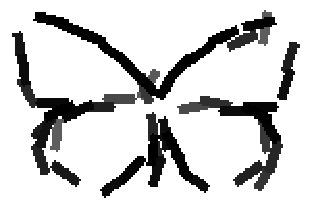

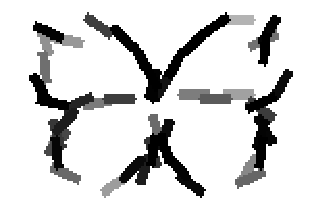

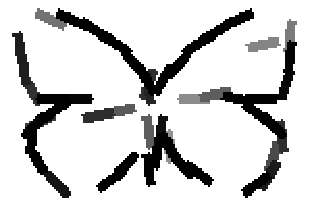

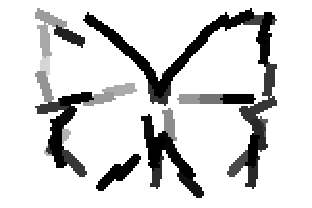



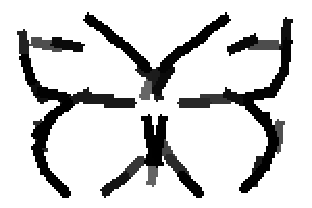

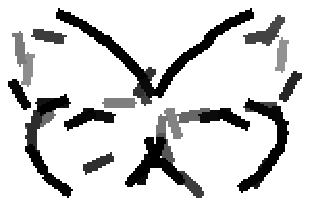

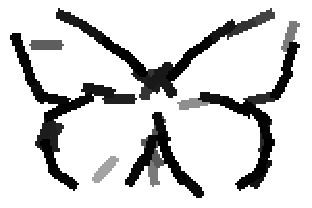

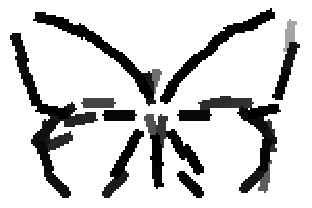

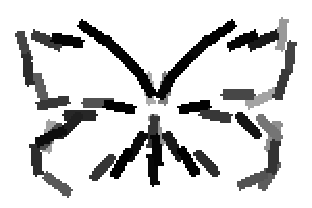

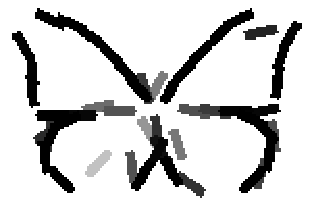

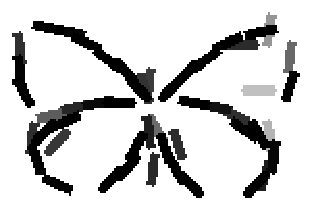



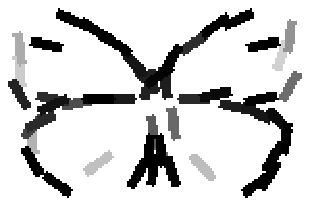

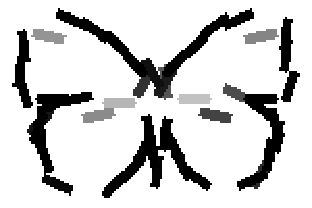

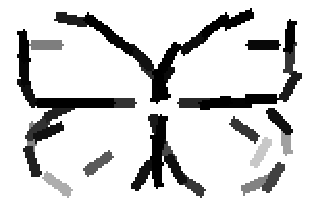

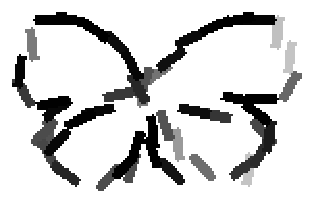







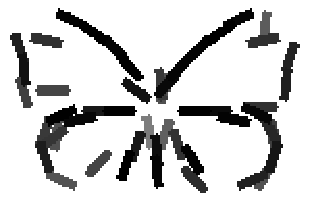

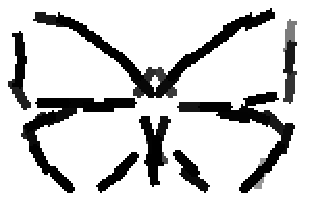

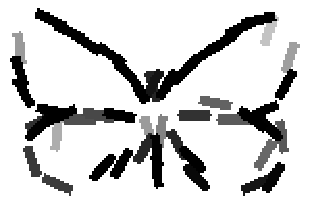

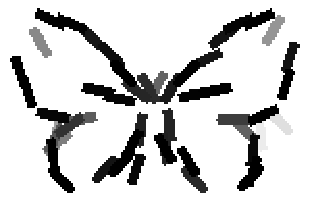







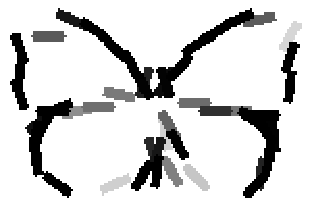



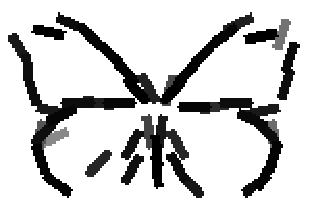

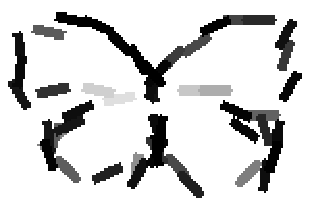

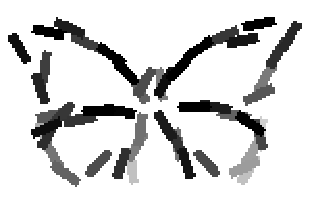

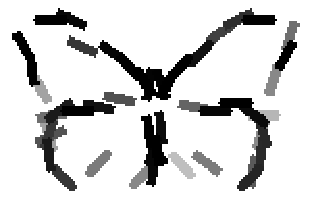

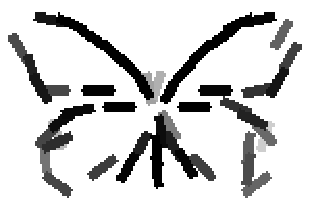

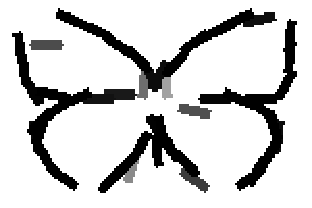





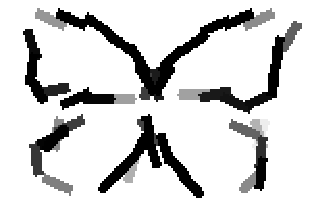





























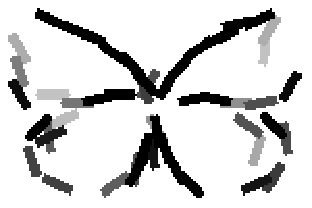

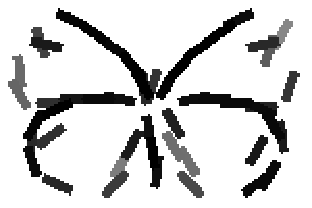

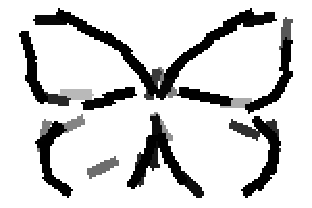

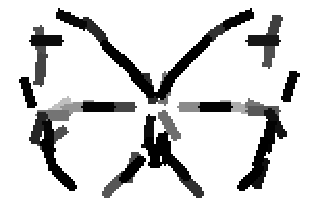























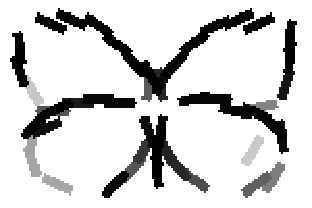



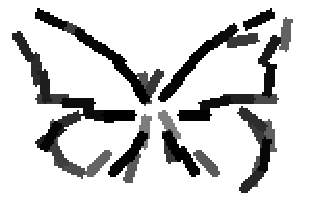

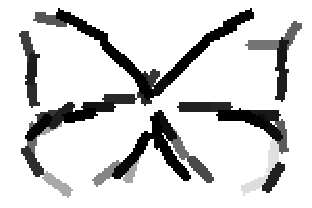

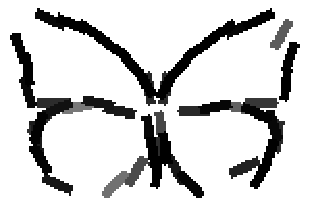















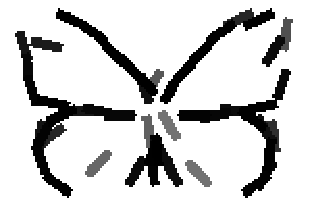

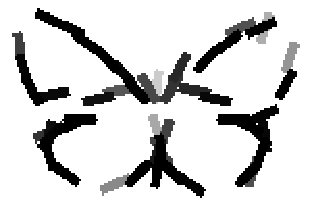



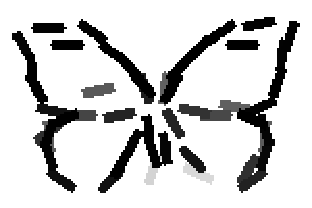



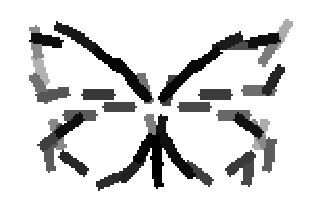


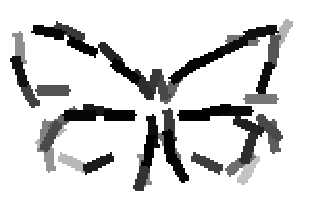




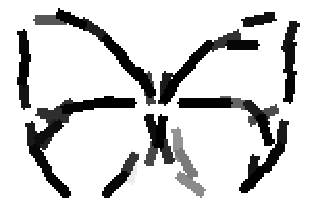

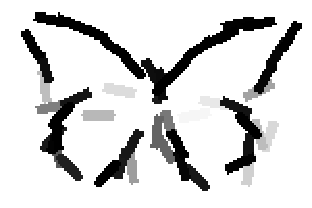

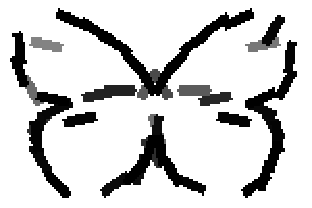

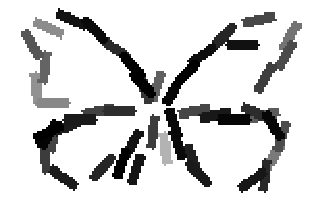

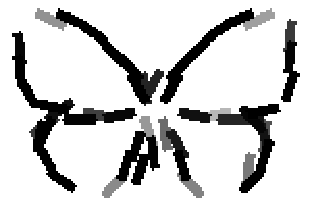

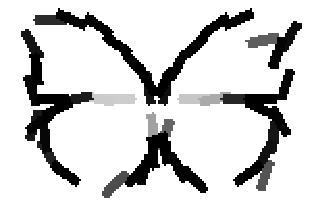

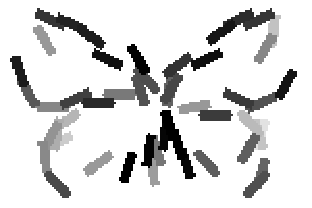

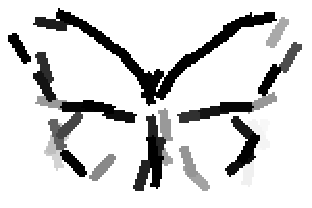

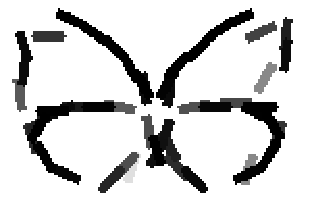









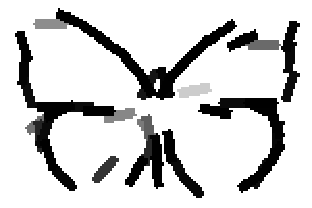



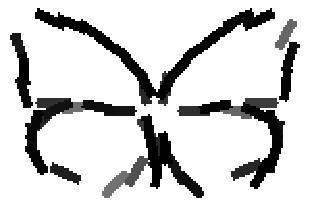



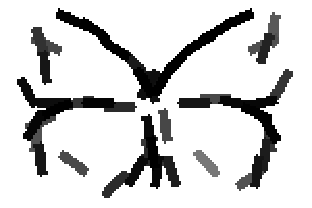

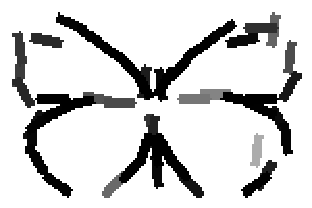

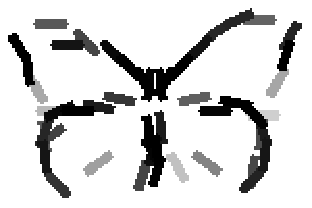

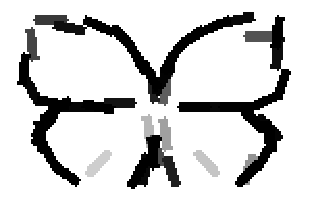

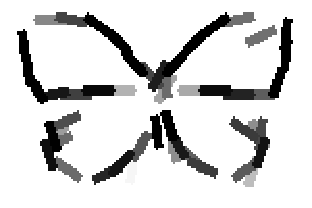

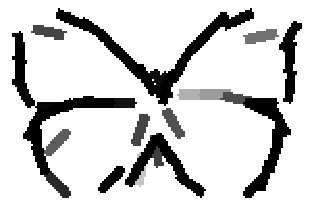



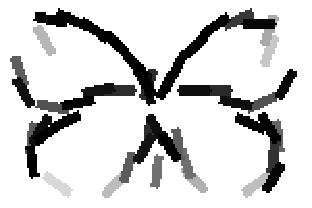


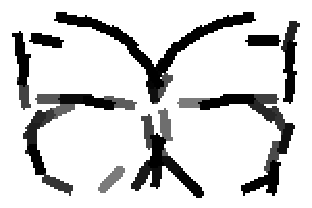

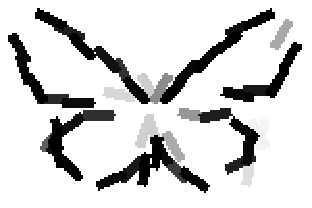



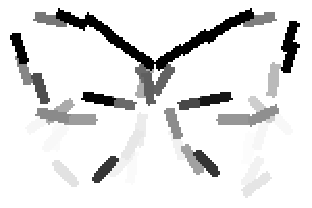

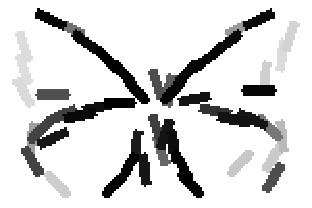













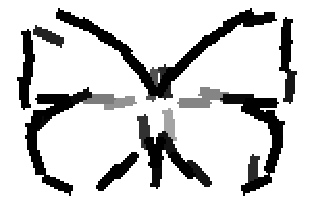

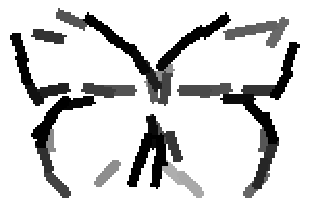

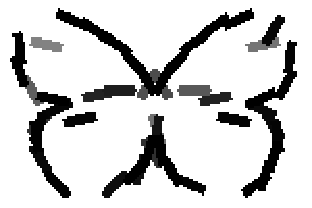

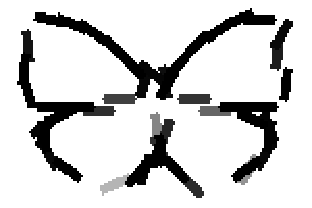




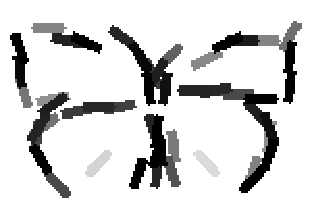





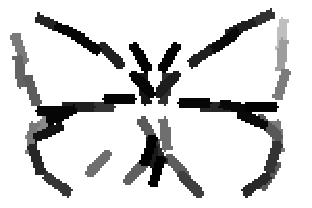

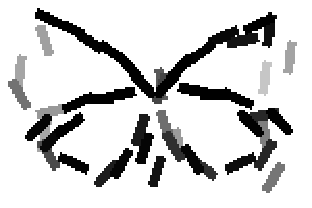











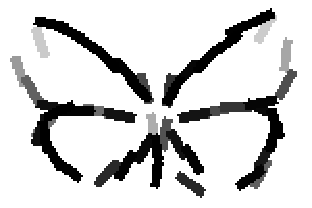



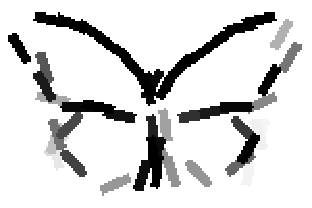

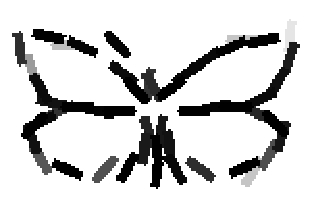

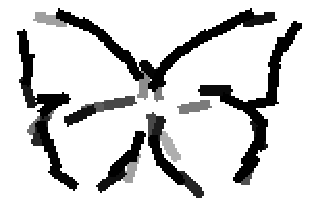

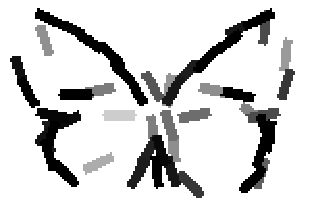



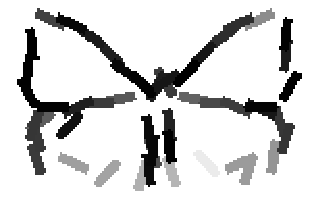



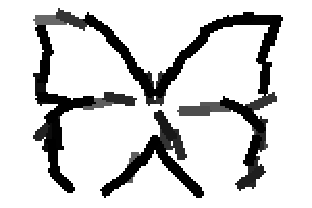


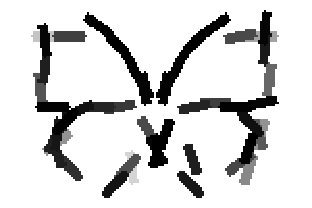




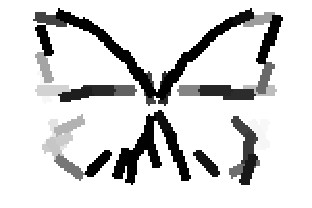


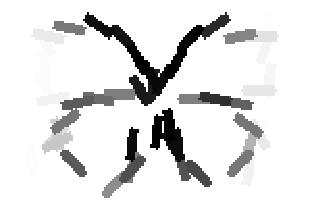

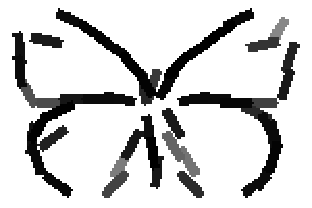



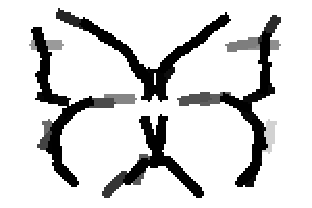

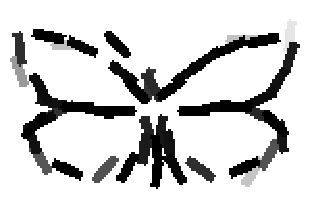



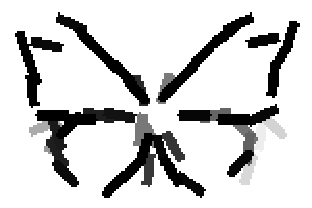

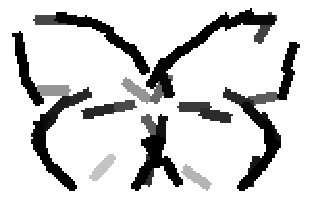





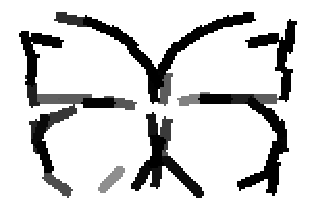

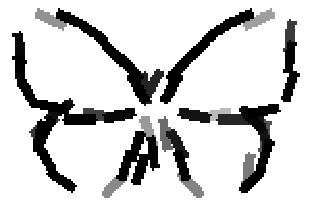

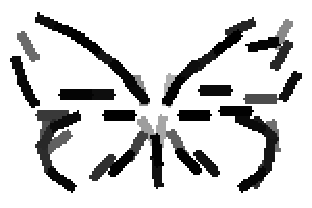

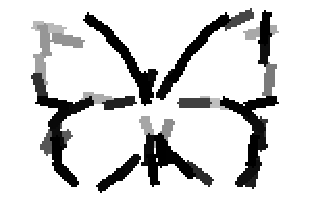

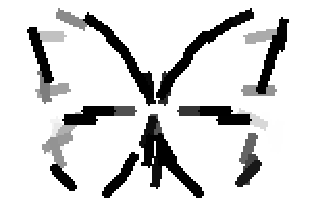

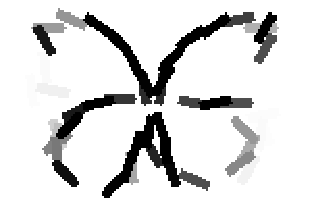









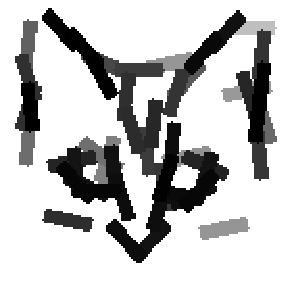



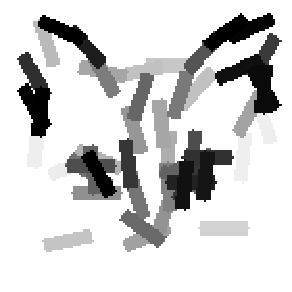

















































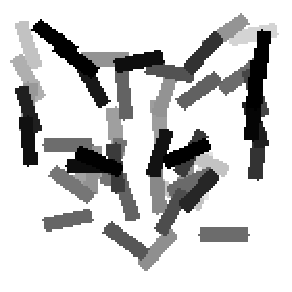

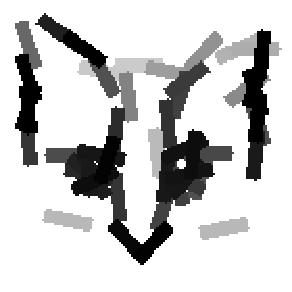

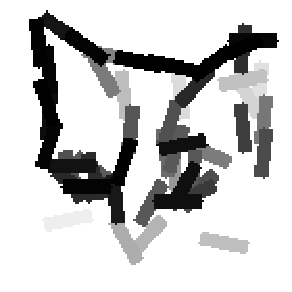

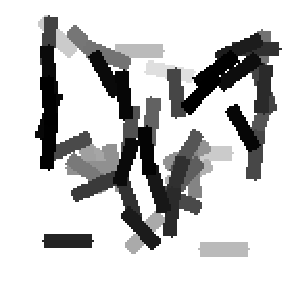











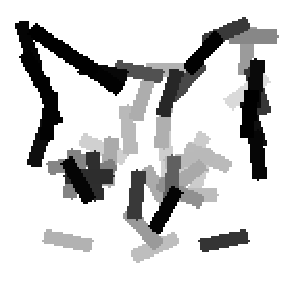

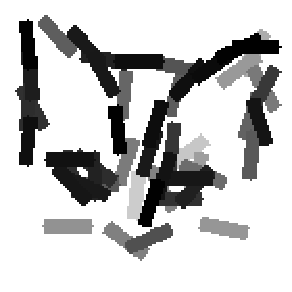





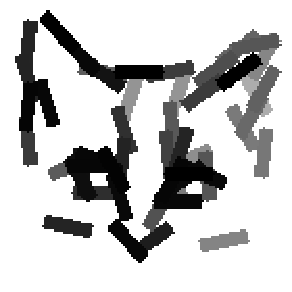



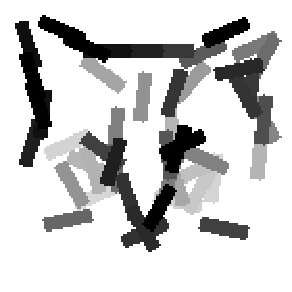























































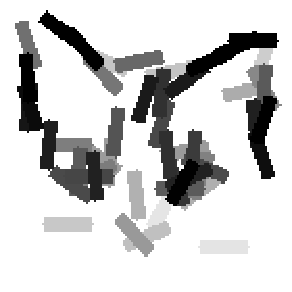





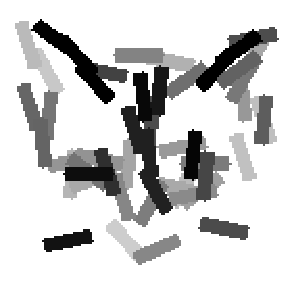

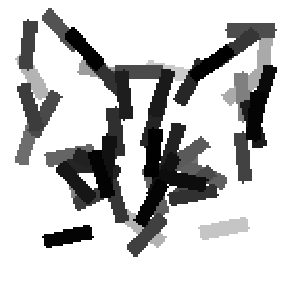











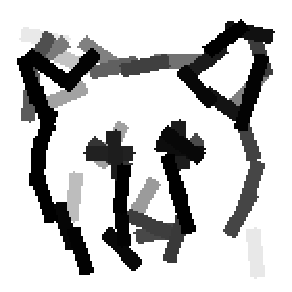





















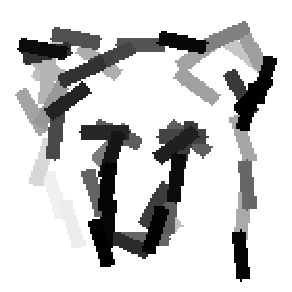









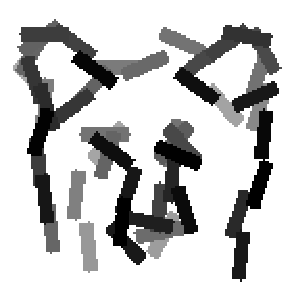

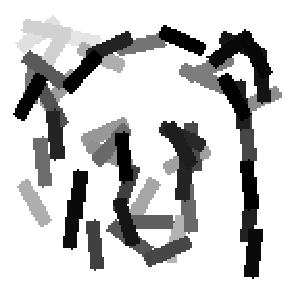





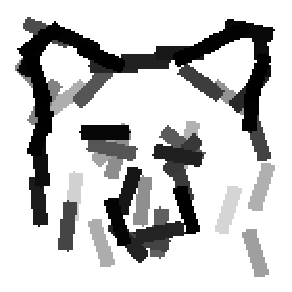

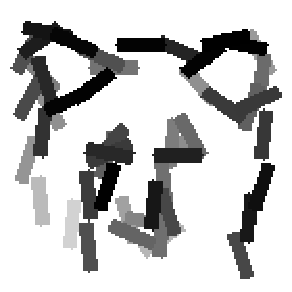

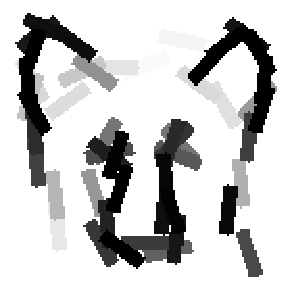

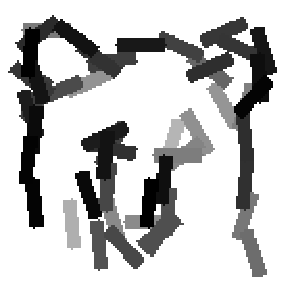

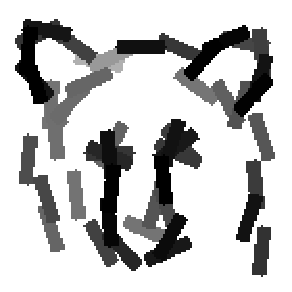



















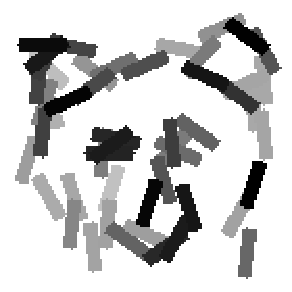







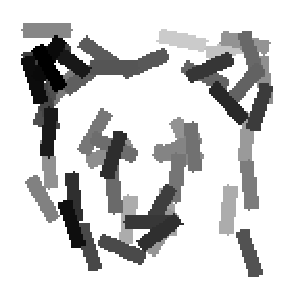

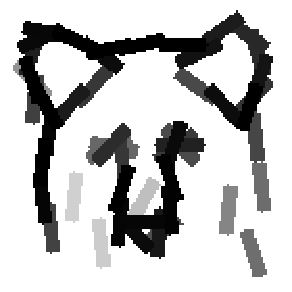

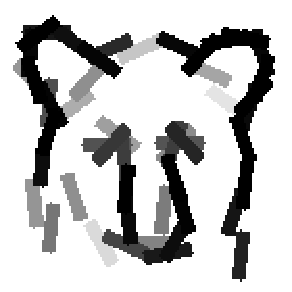

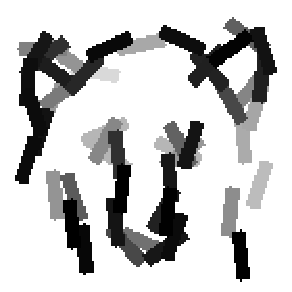

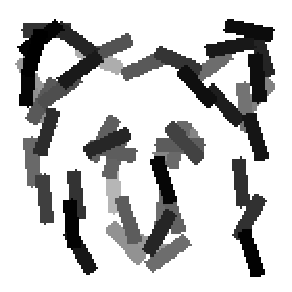



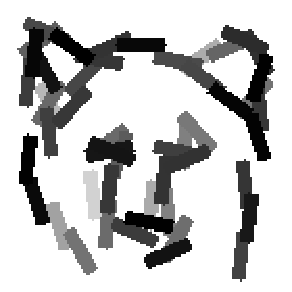







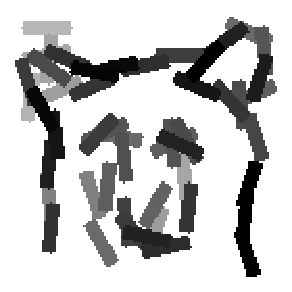





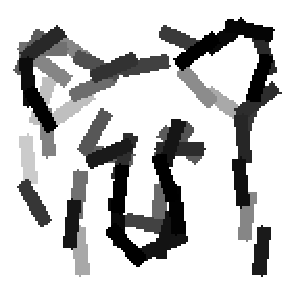



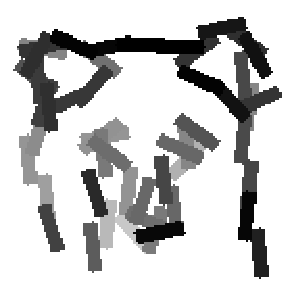



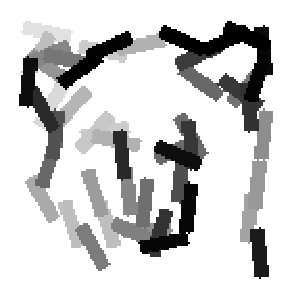







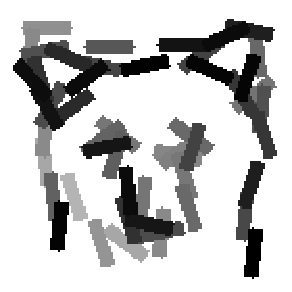
















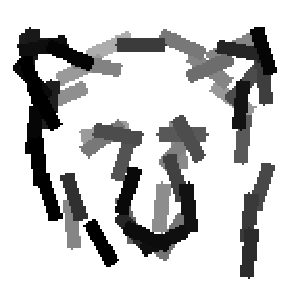



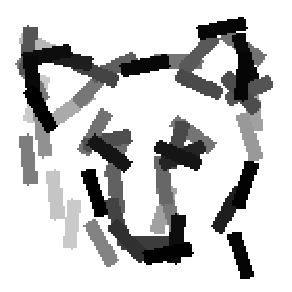





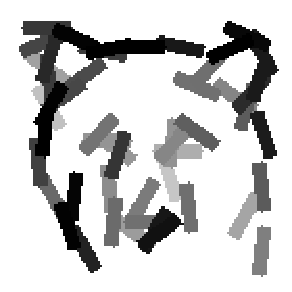





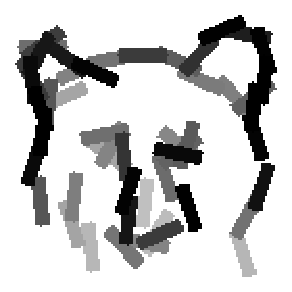





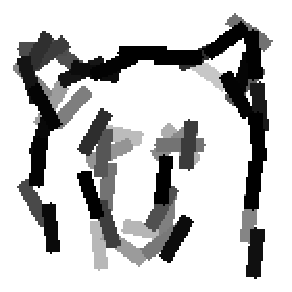



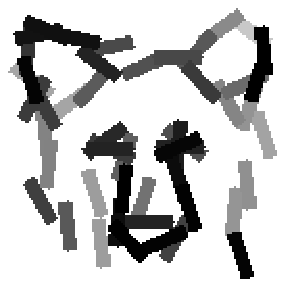

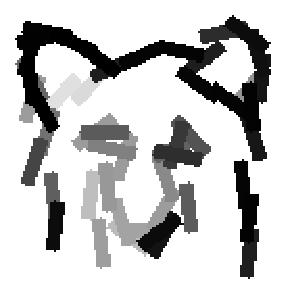





















Old code for reproducing results in paper:
deer
Back to active basis homepage