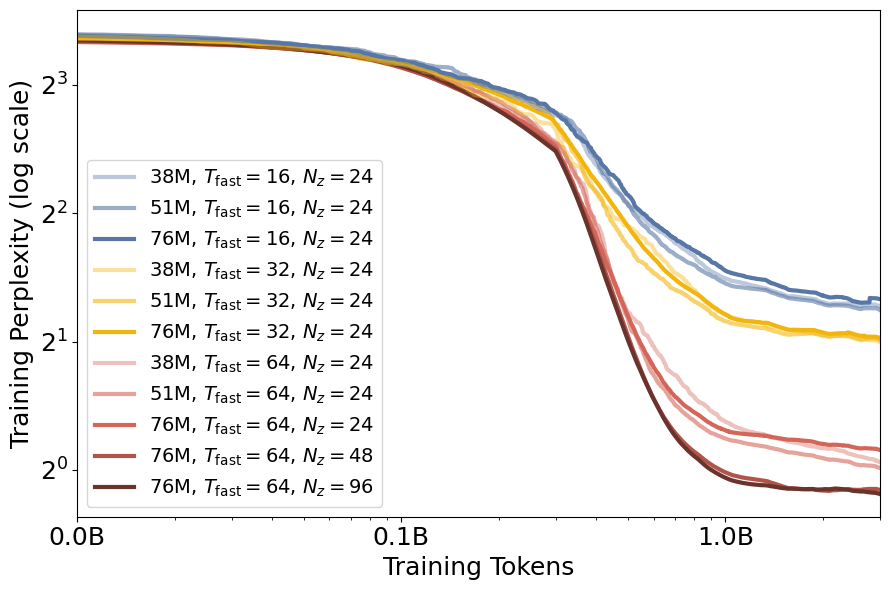
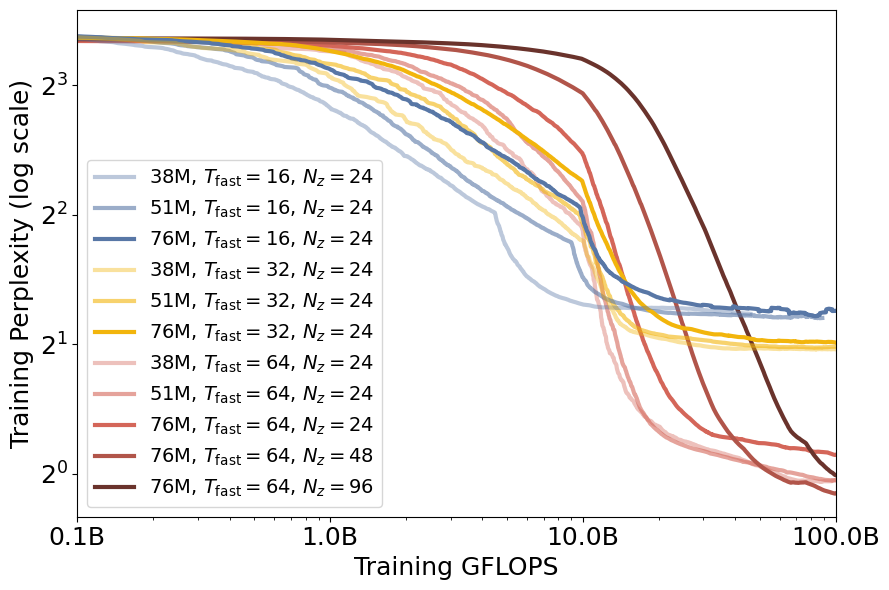
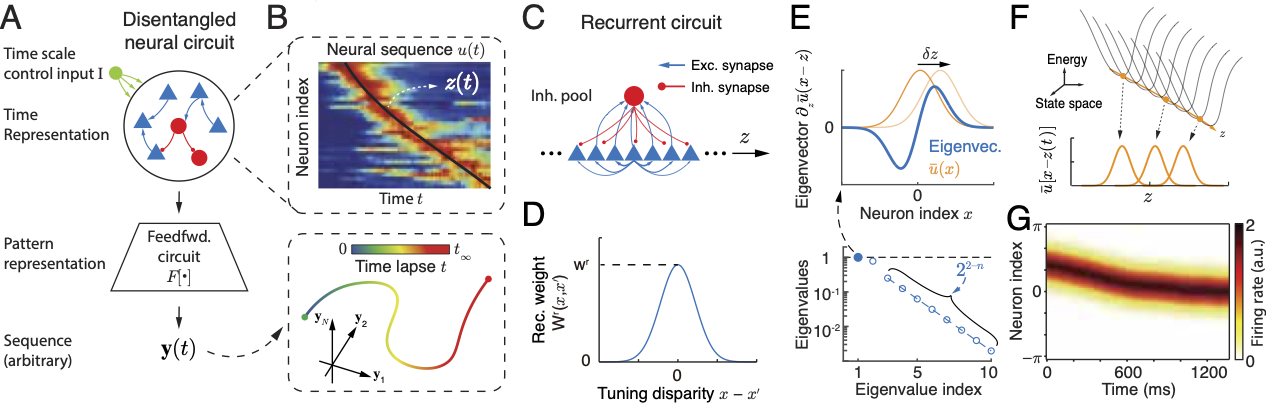
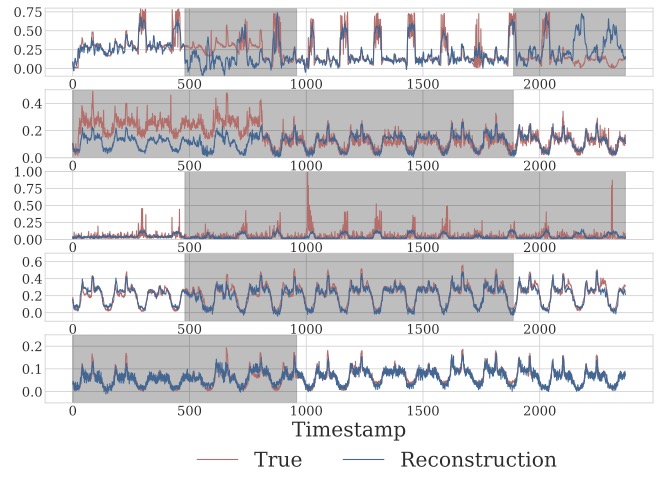
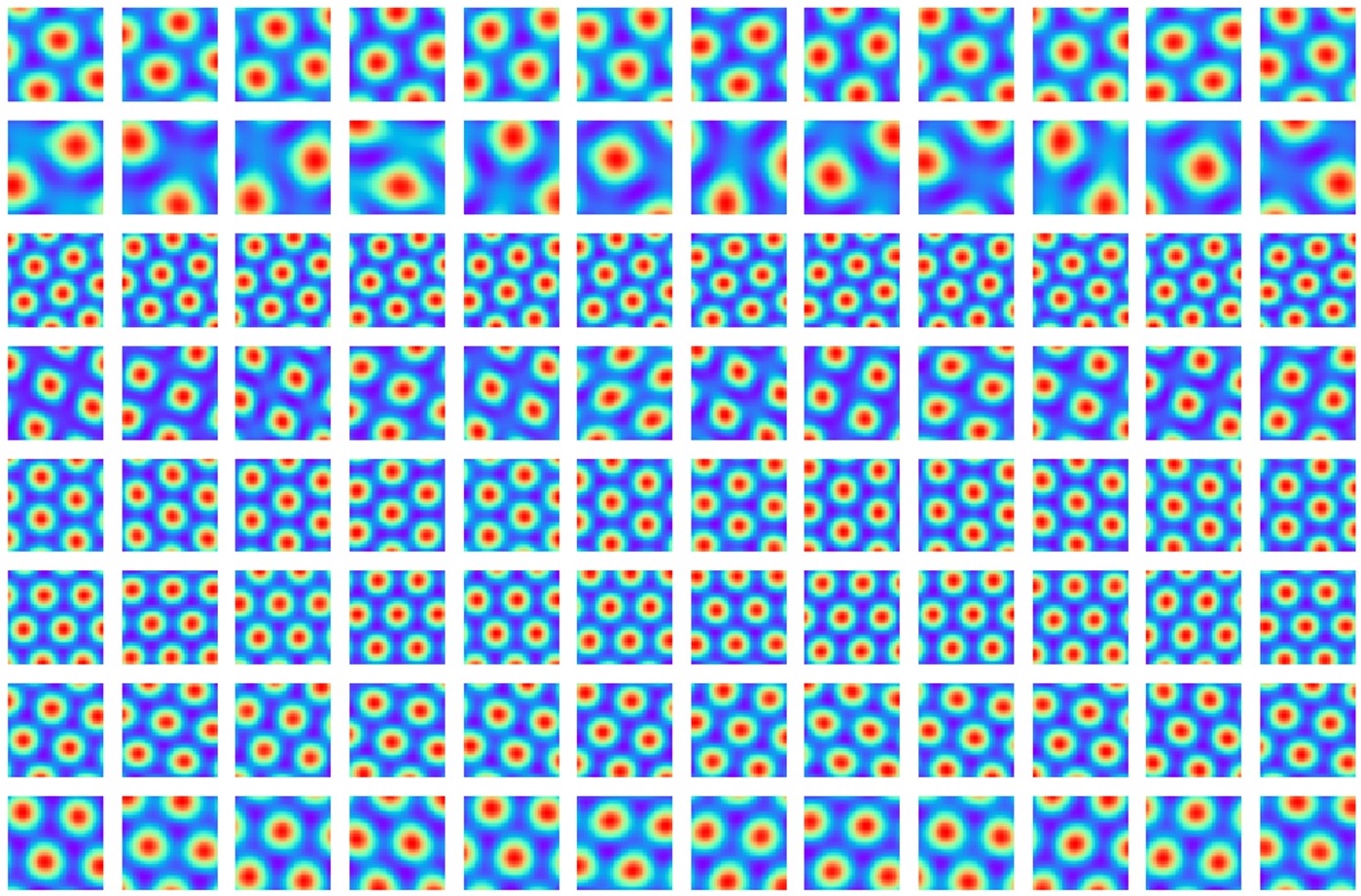
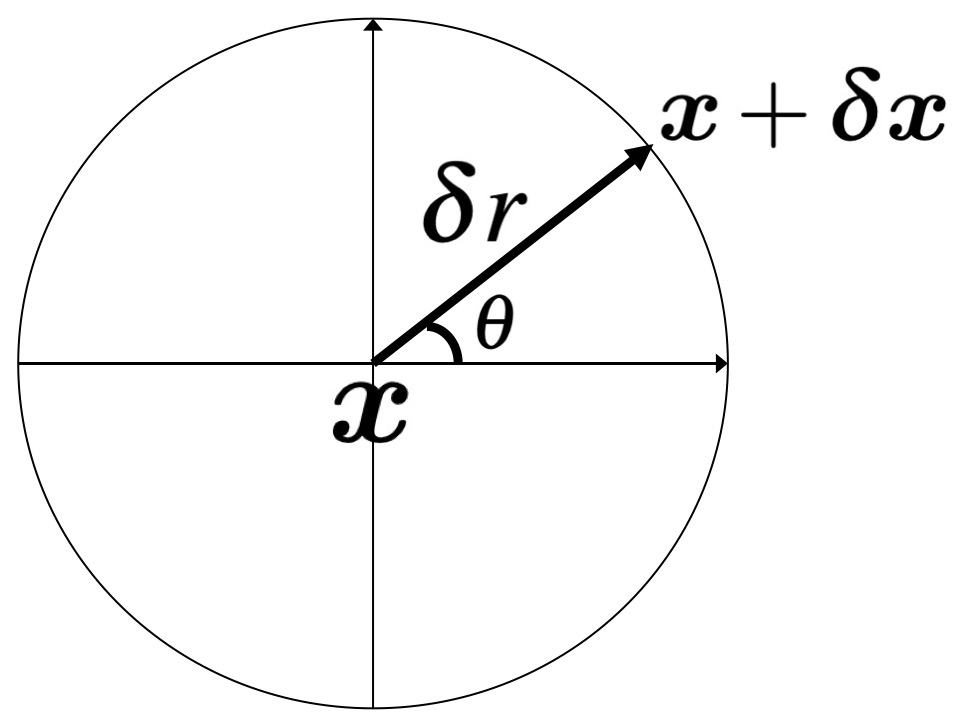
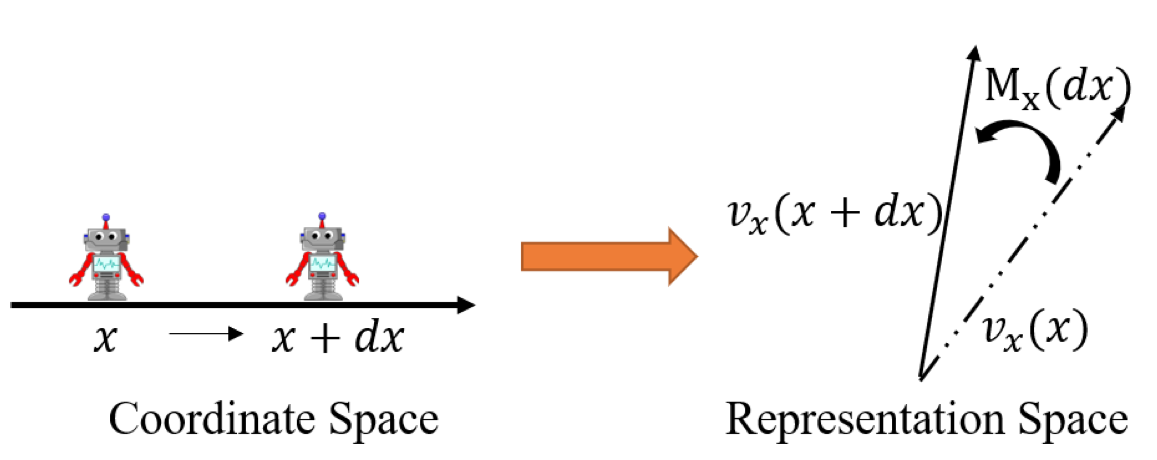
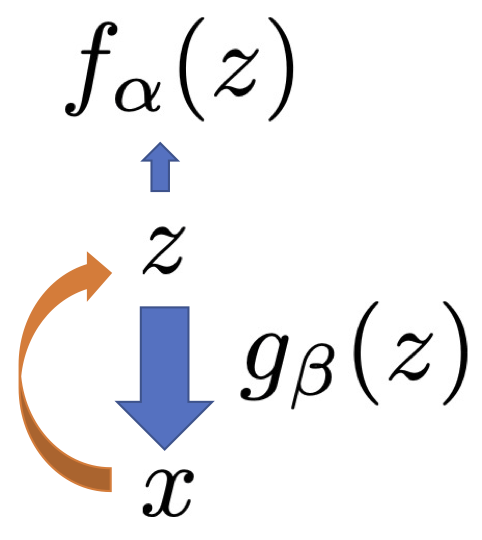
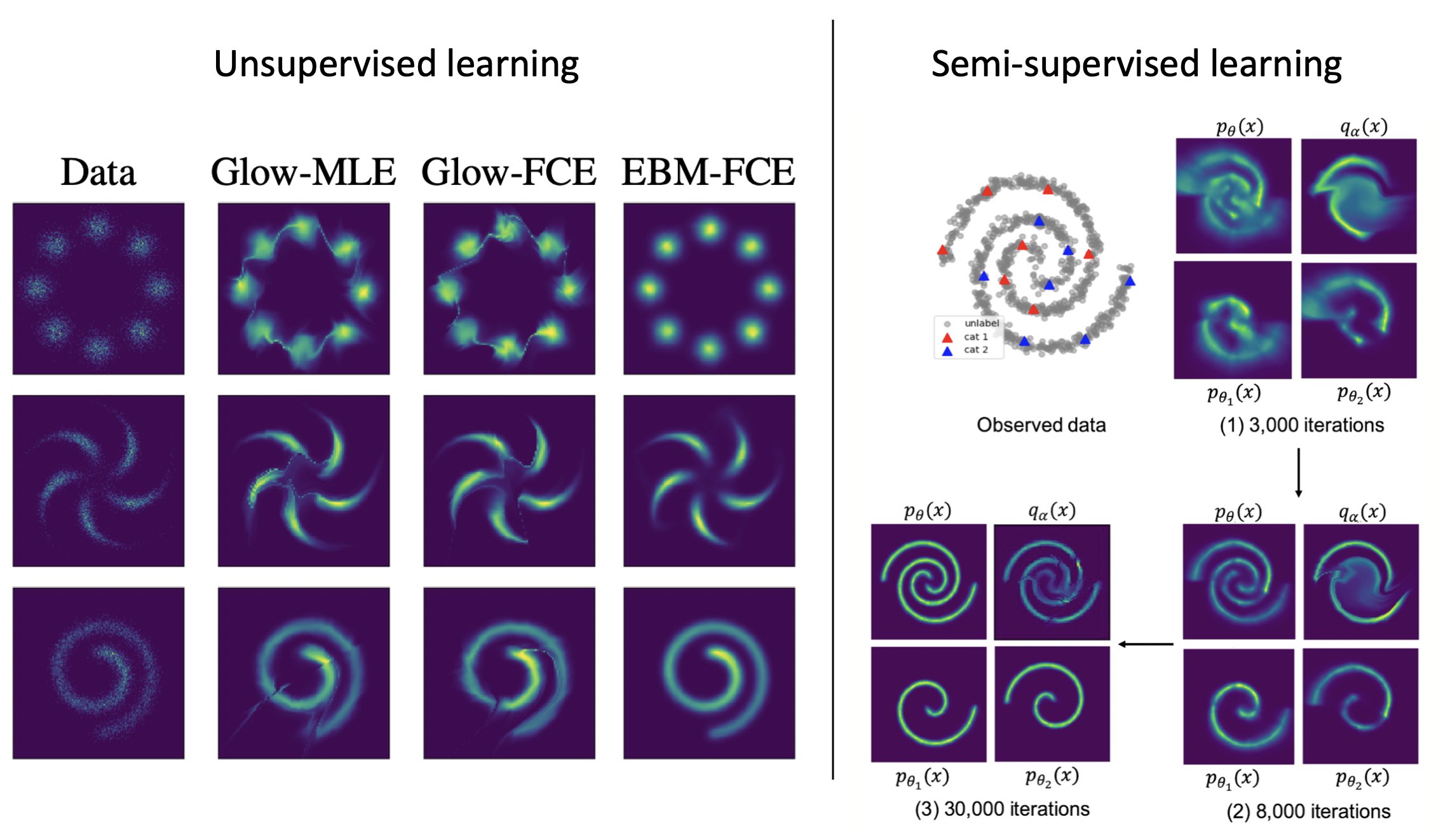
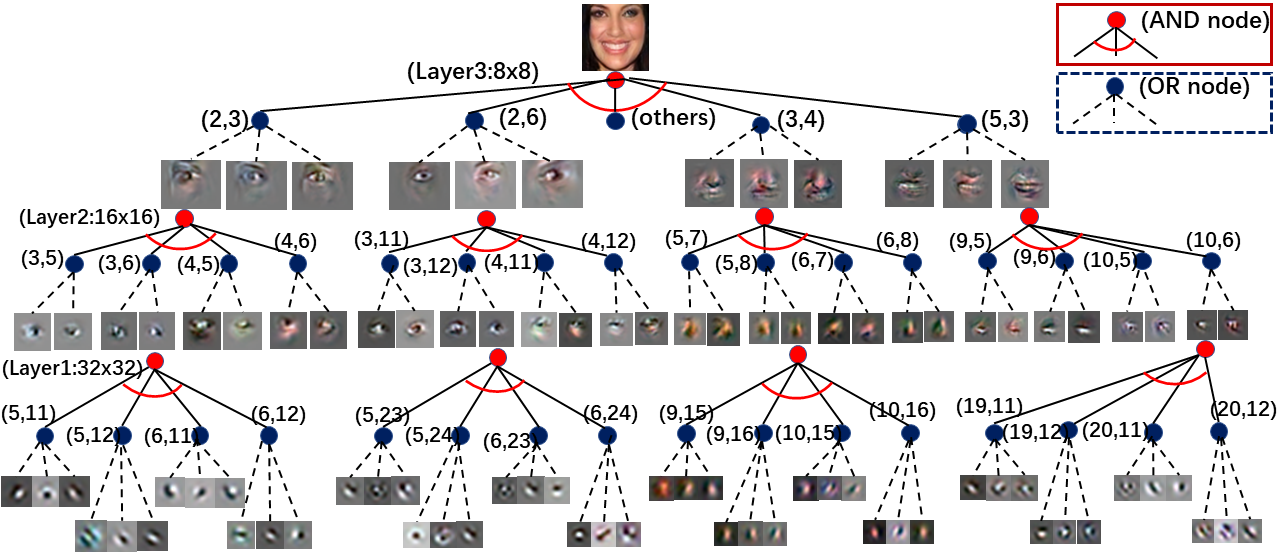
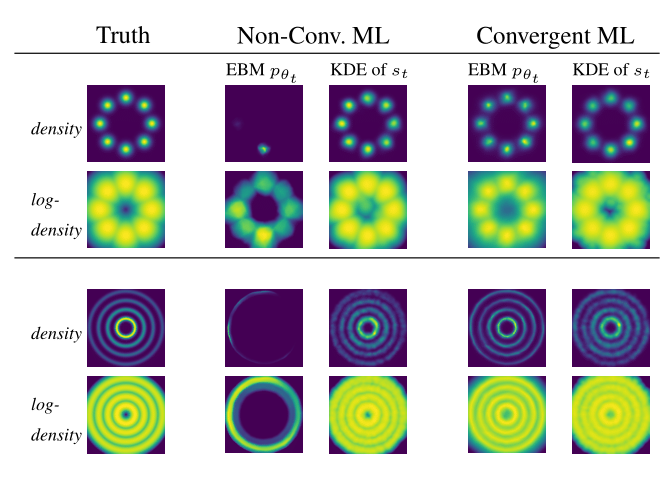
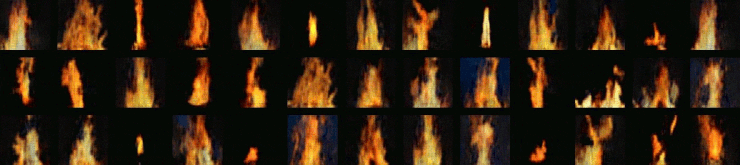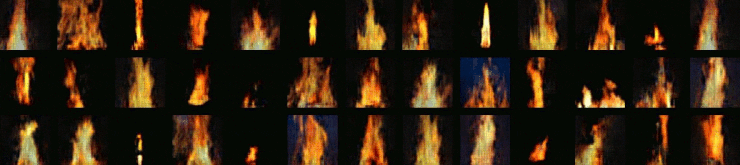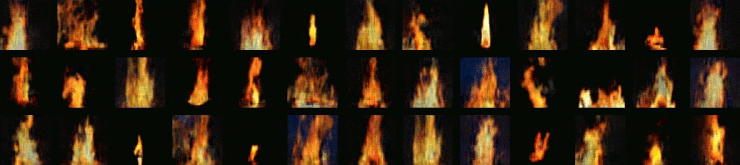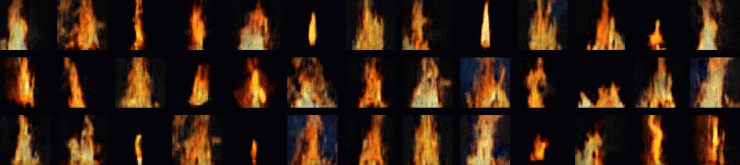
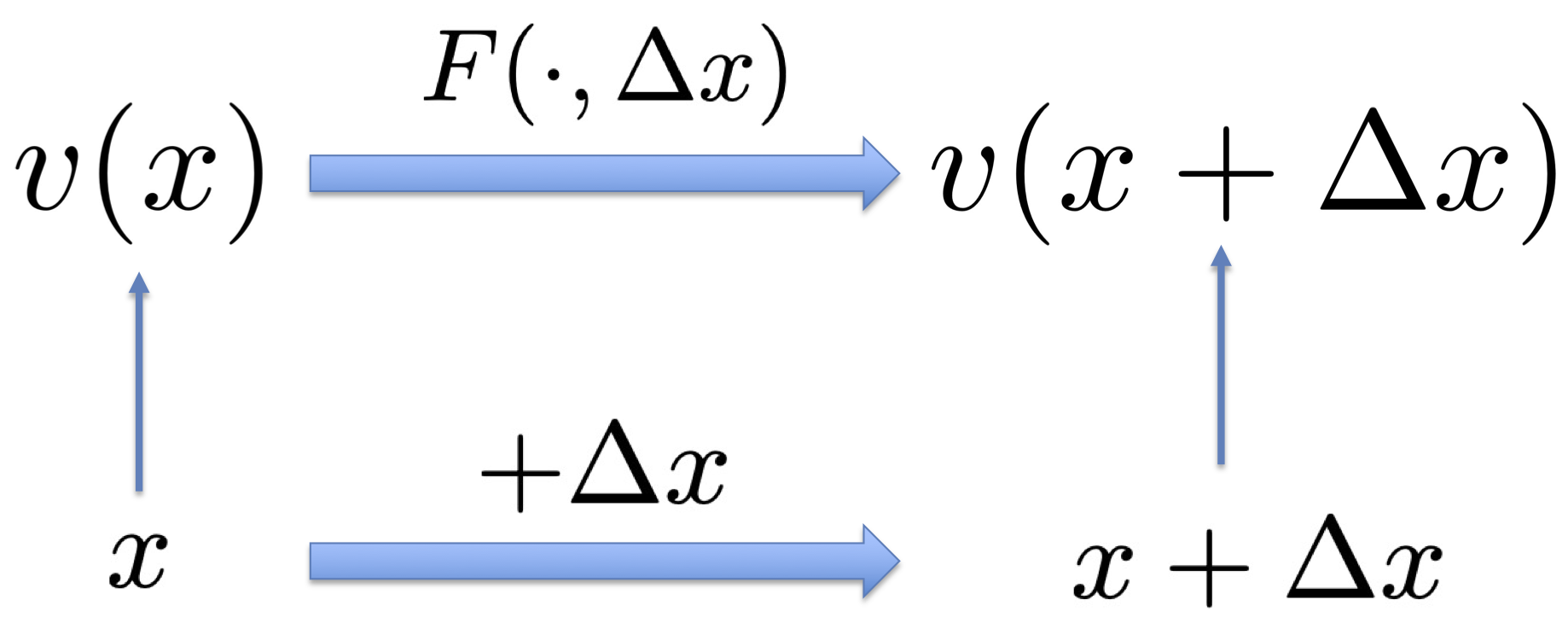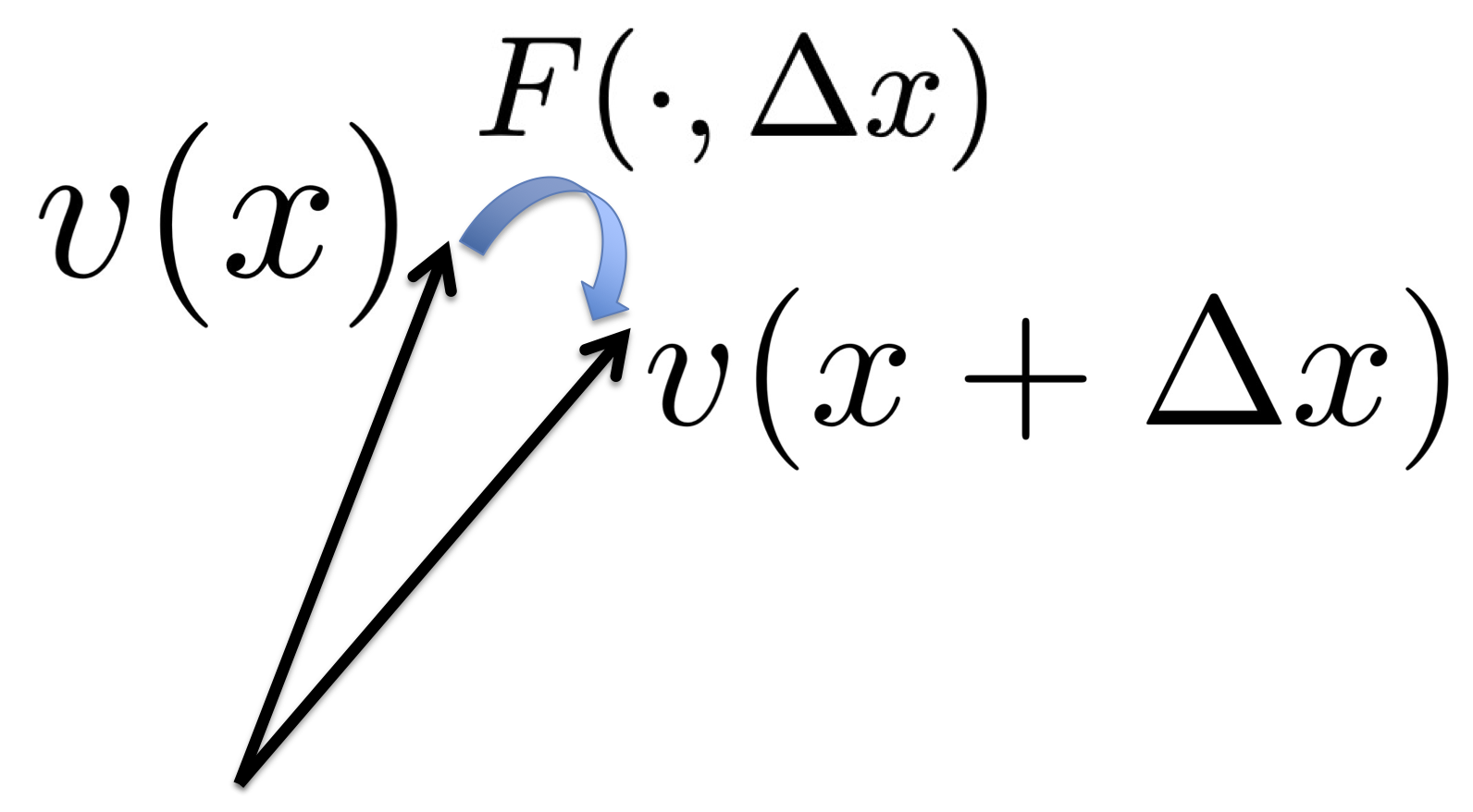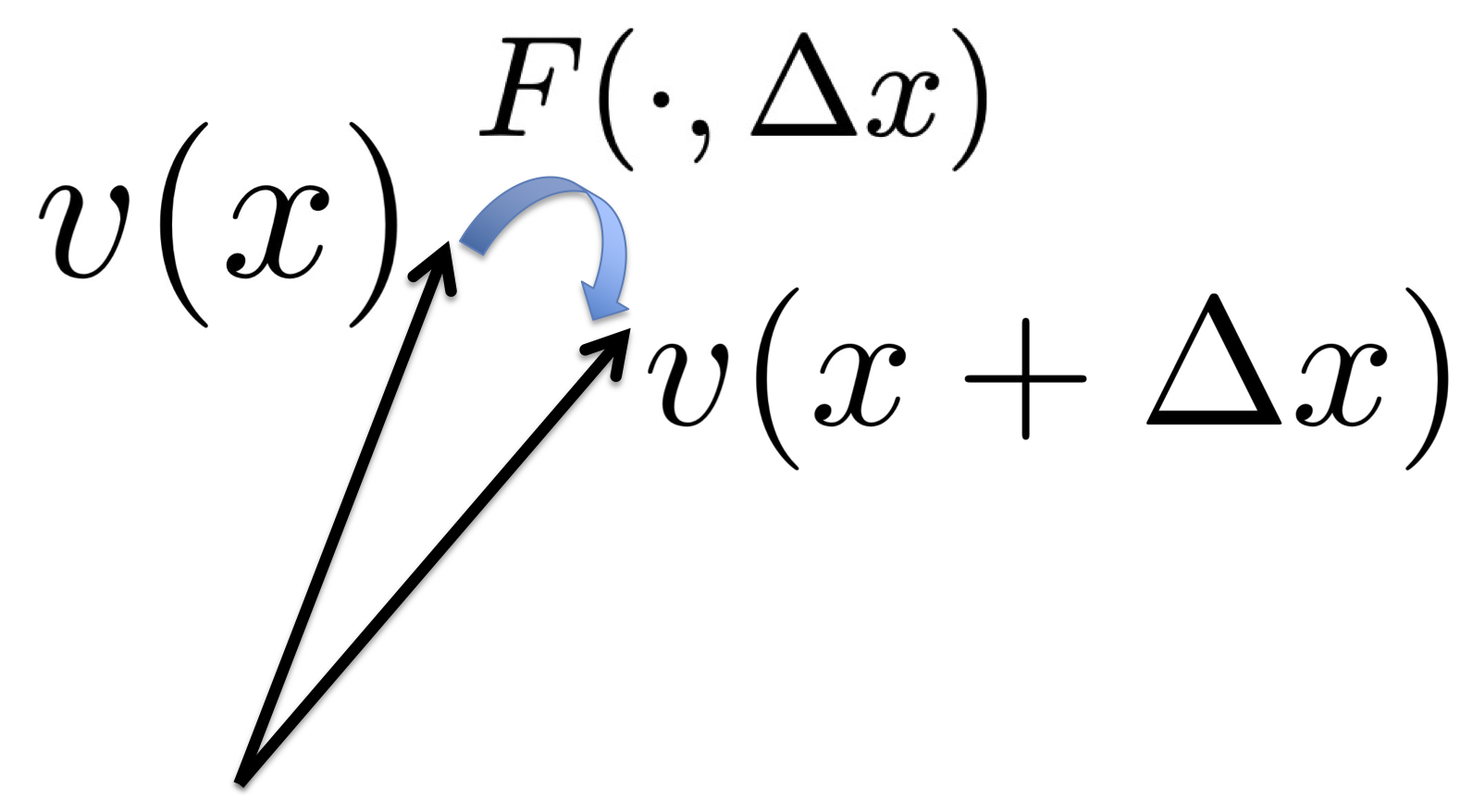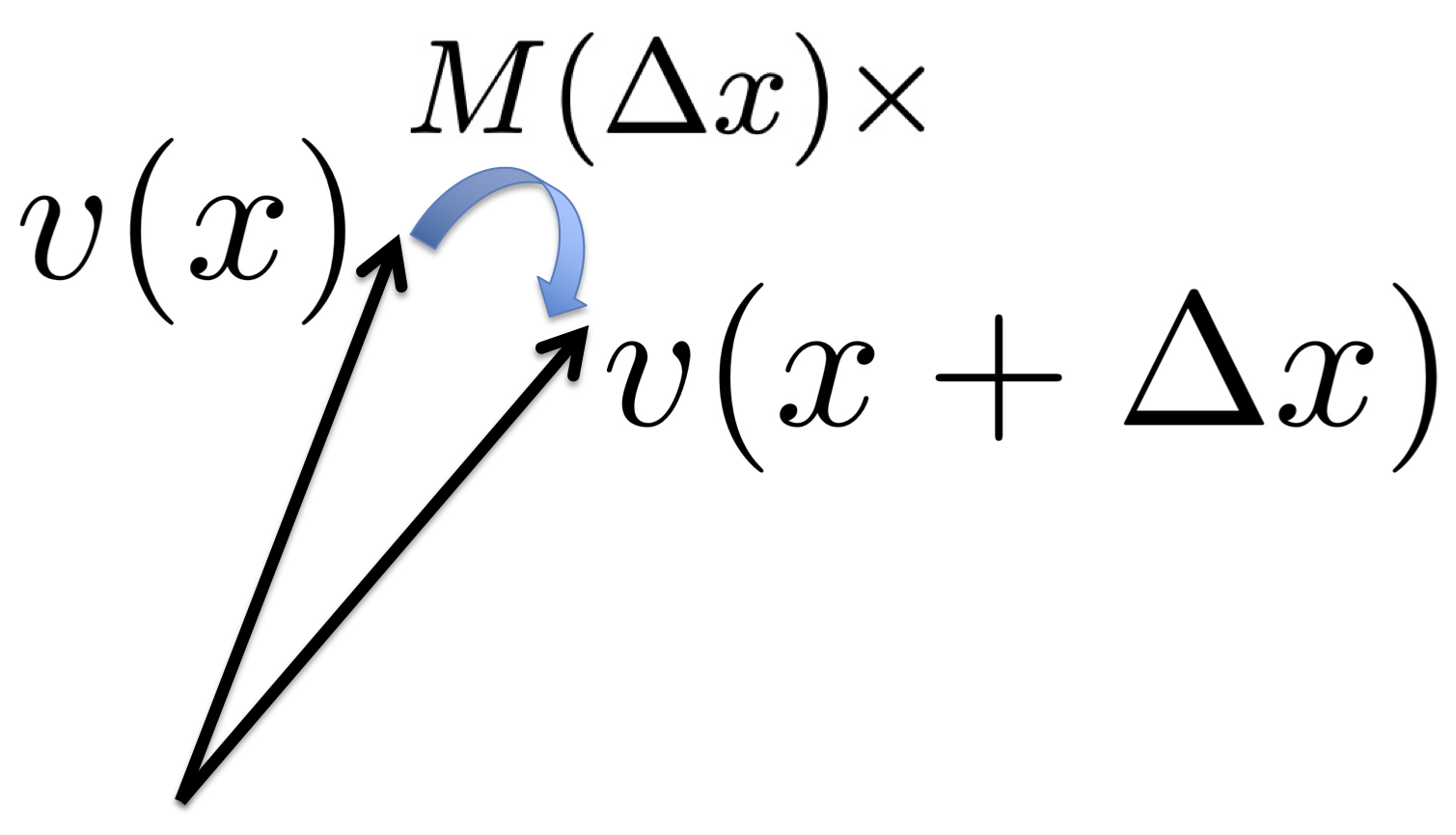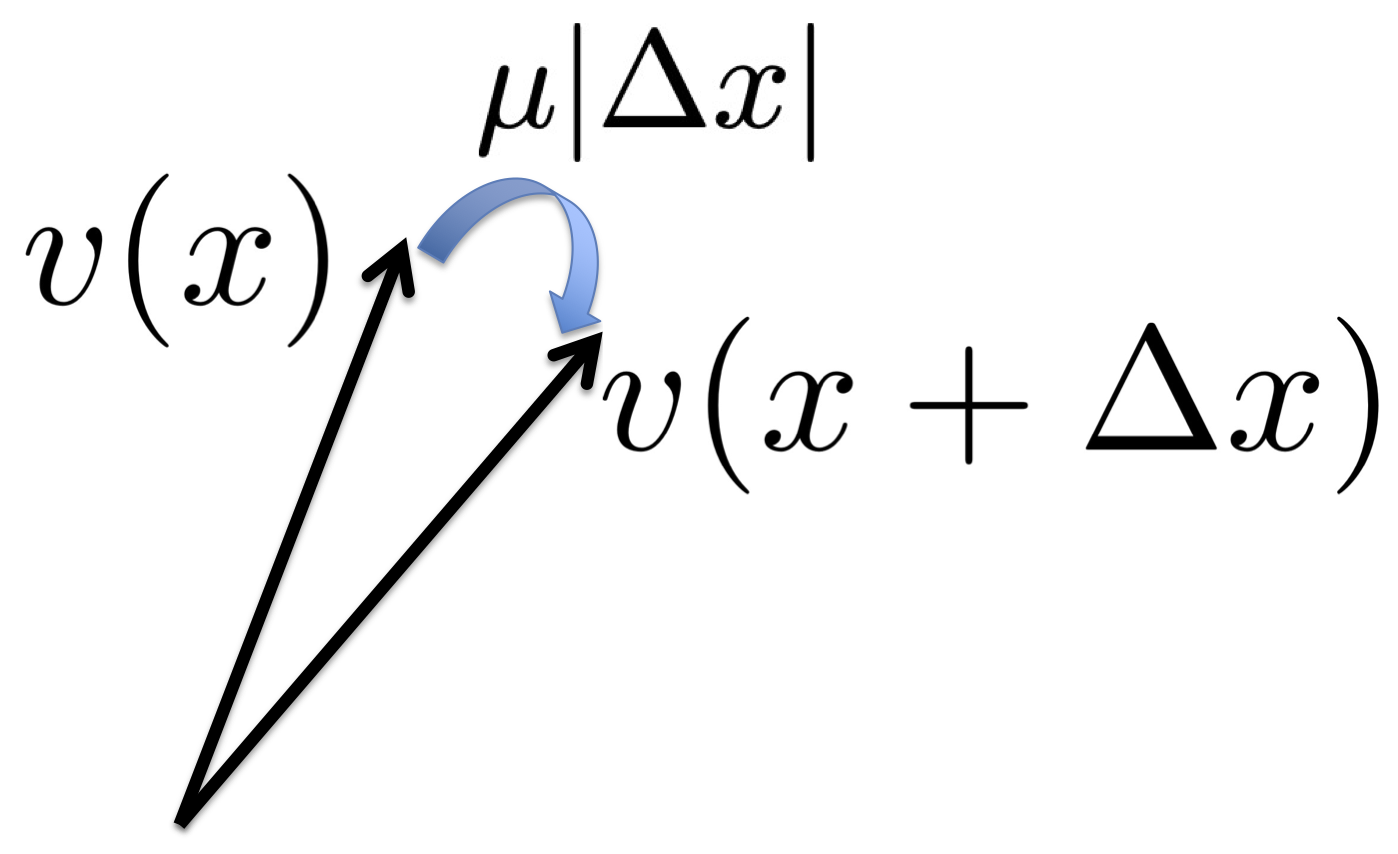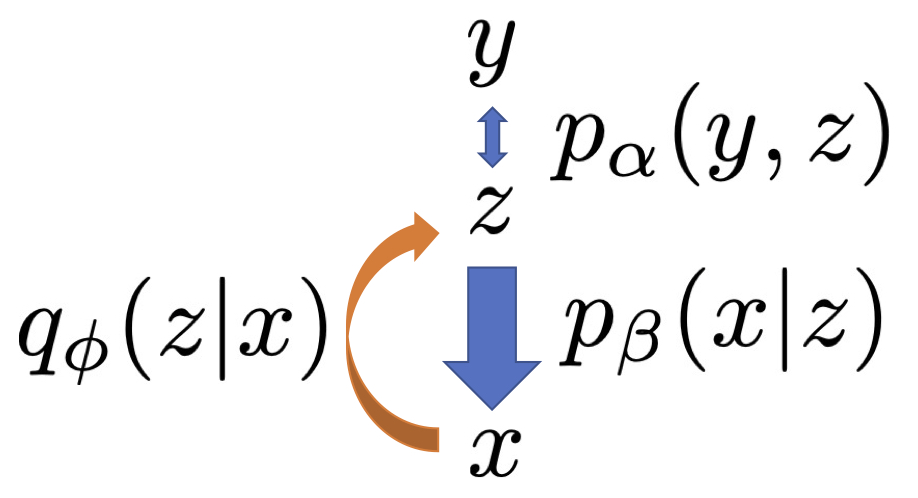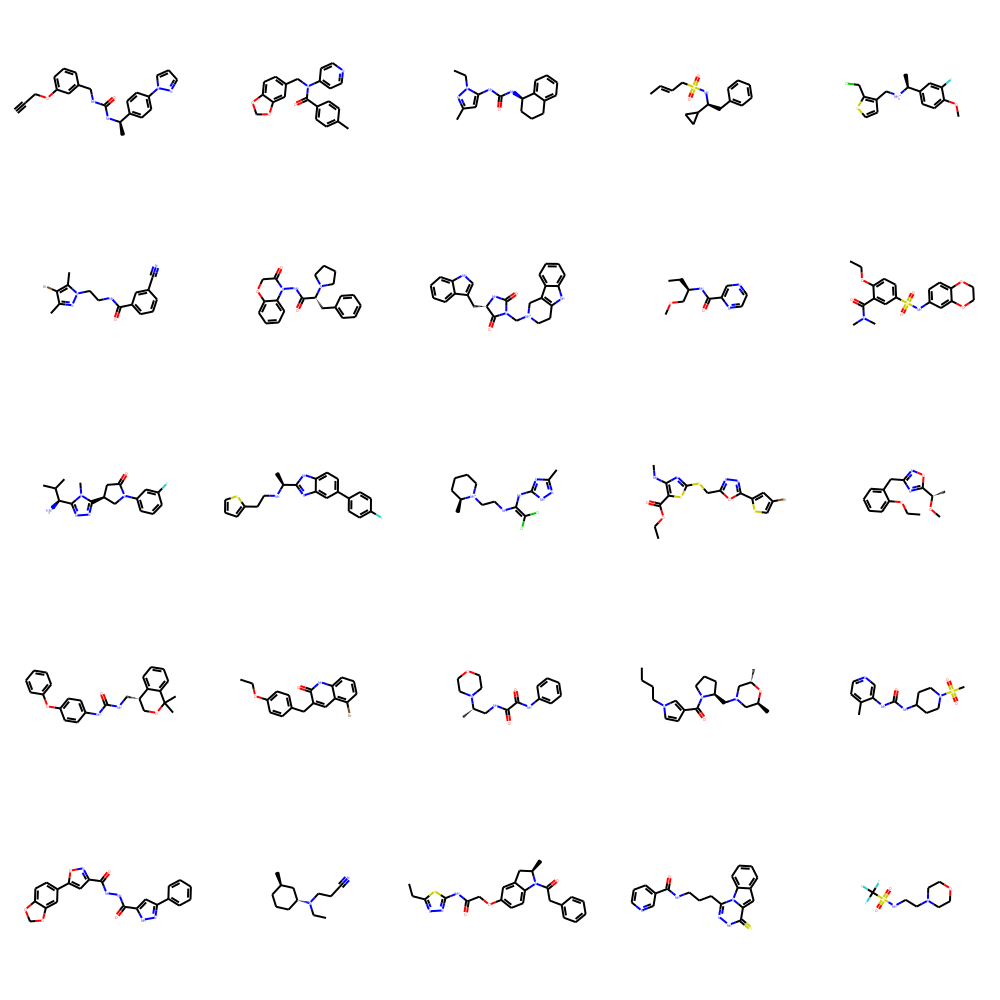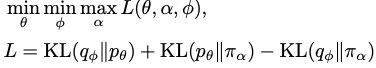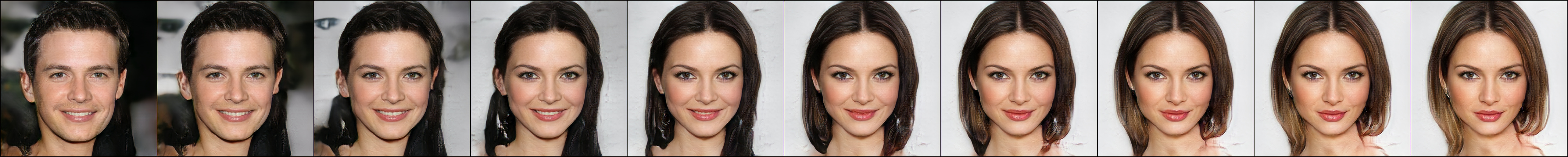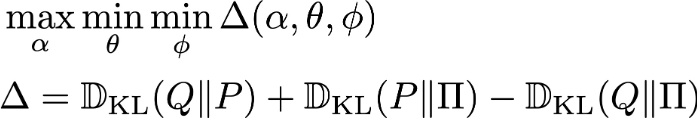Research interests: Generative AI and Computational neuroscience. I am particularly interested in brain-like models. I am also interested in quantum field theory as generative models.
Most of my work was done by my Ph.D. students whom I have had the good fortune to advise, mentor or collaborate. Some recent ones include (in no particular order, some co-mentored with colleagues):
For more recent papers, please check my google scholar page. I have stopped keeping track of them on this page.
Wu, Y N (2026) Information Processing by Scalar Fields of Numerical Relativity: A Spin 0 Emergence Theory of Quantum Gravity and Beyond. pdf DOI 10.5281/zenodo.15830710 (The numerical sections are co-authored with Chenheng Xu and Yixin Zhu from Peking University)
Wu, Y N (2026) Quantum Field Theory as Generative Models and Emergent Gravity as Latent Variables: A Tutorial for Statisticians and Machine Learning Researchers. pdf
Comment: This paper is based on two lines of my past work. (1) My past work with D. Mumford and S. C. Zhu on maximum entropy energy-based models (or exponential family models) of random fields where the energy function is defined in terms of local filters or operators. In the QFT Lagrangian of the above work, we introduce squares of Noether currents (such as pre-geometric tensor term). The current-current interactions serve as generative seeds. (2) My past work on data augmentation with D. Rubin, C. Liu, and J. S. Liu and latent variable models that I have been working on, where for a data distribution p(x), we augment it with latent or auxiliary variables z, to have a joint p(x, z). Integrating out x, we get the marginal p(z), as the model for the emergent collective patterns. The Hubbard-Stratonovich transformation (HST) is one example of such a scheme, analogous to the data augmentation idea of W. H. Wong and the restricted Boltzmann machine (RBM) in machine learning. Heat kernel expansion after HST is analogous to asymptotic expansion in statistics. Yet a third related line of my work is on modeling grid cells, which form a Dirac ket of position that undergoes rotation as the agent moves. The unitary evolution of the Dirac ket and the energy-based model are linked by the Wick rotation that makes time an imaginary number.
About AI use, I mainly used Gemini 3 and ChatGPT 5 in 2025, and Claude 4.6 in 2026. AI helped me with calculations and writing, as well as literature review. I drive the idea formation, technical framing and narrative arc of each of the 100+ subsections, and focus on pattern recognition and structural understanding throughout the whole project.
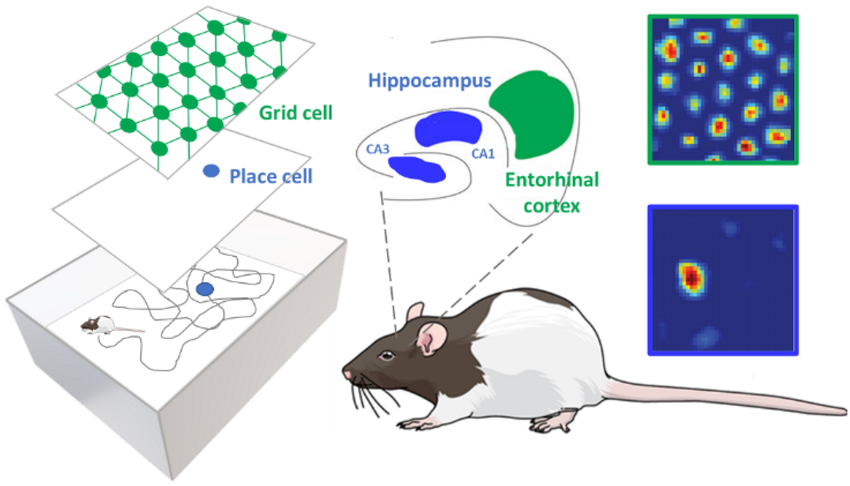
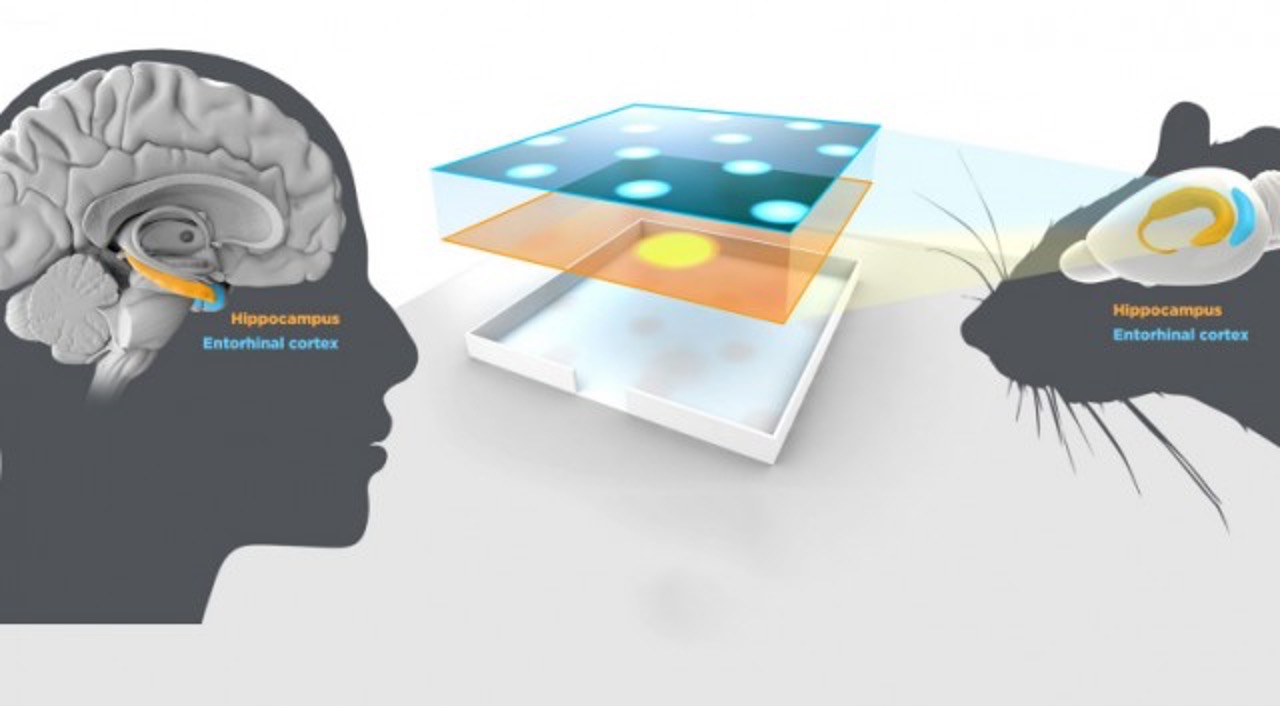
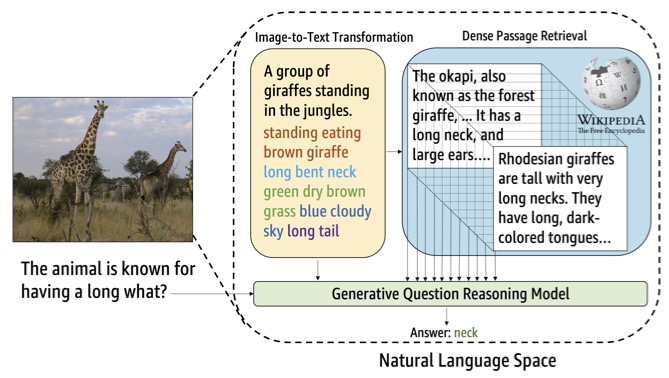
The first illustration is taken from internet. Copyright and my gratitude go to the original authors.
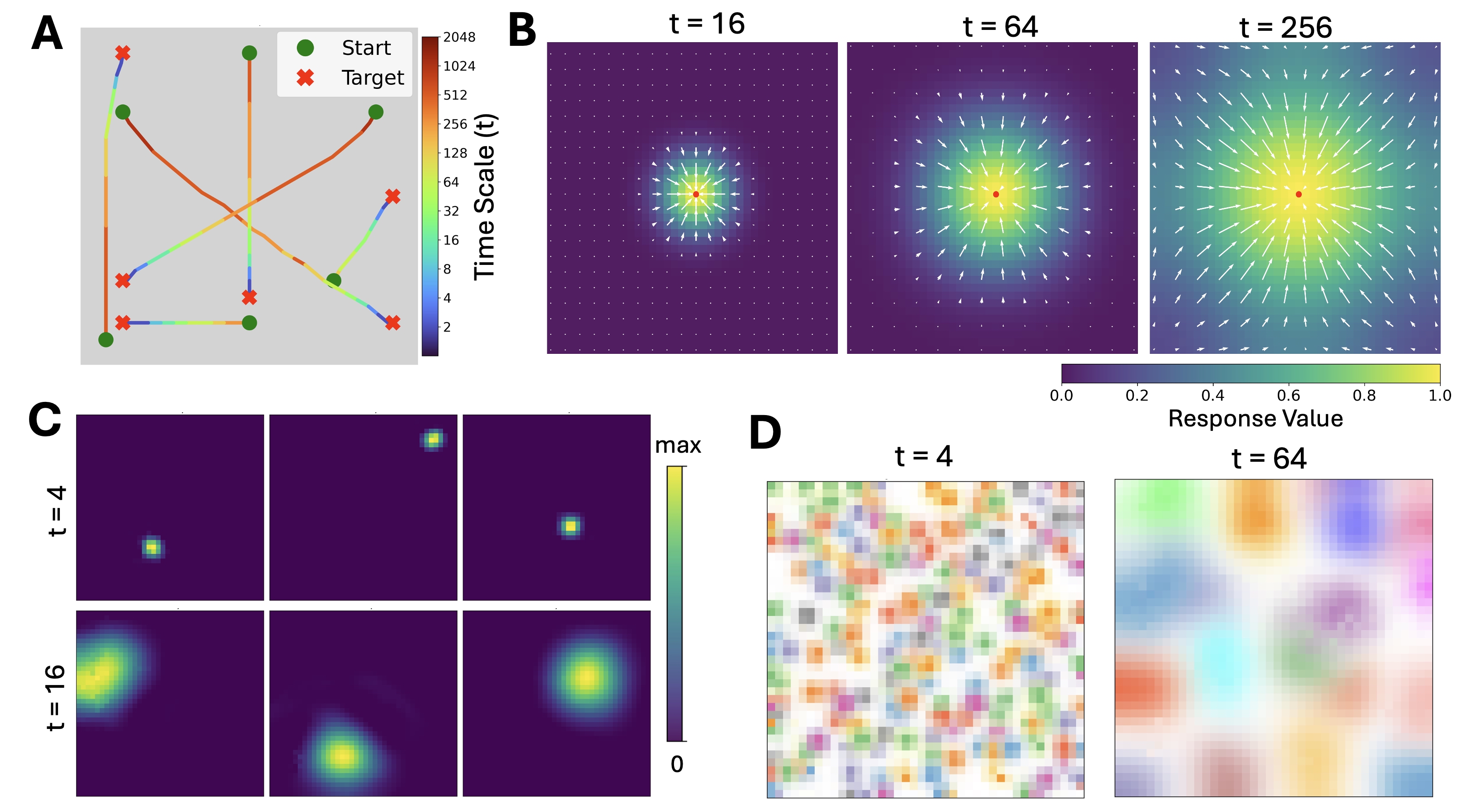
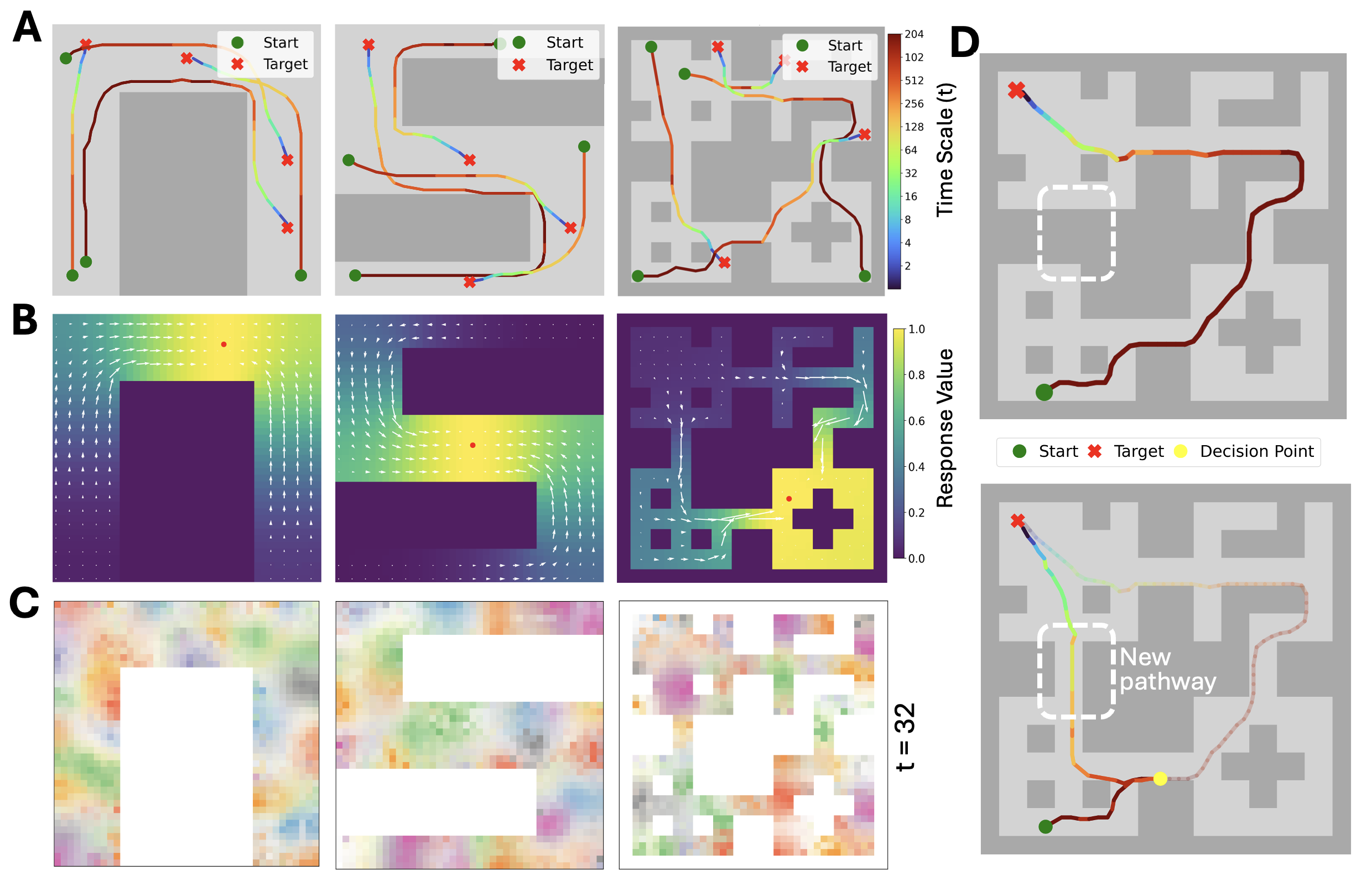
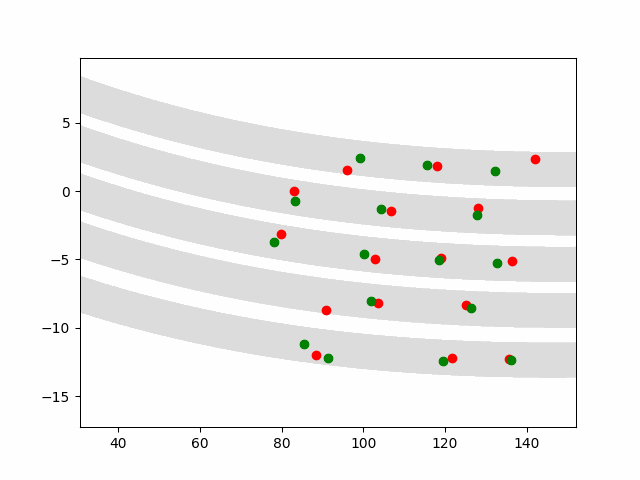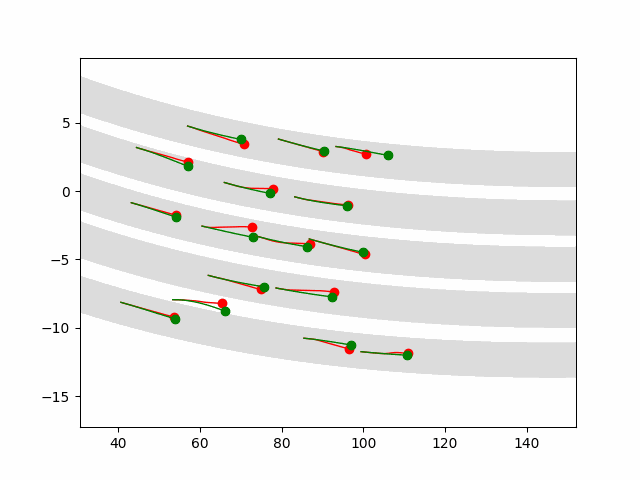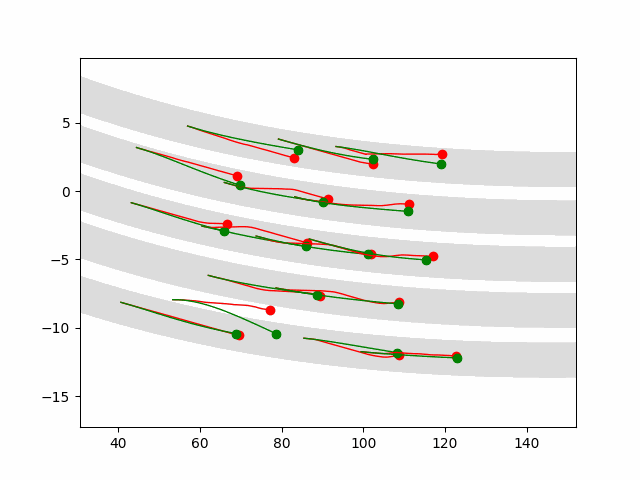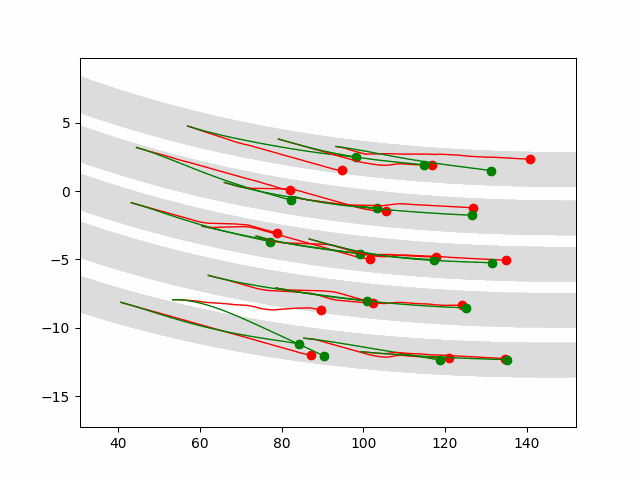
Zhao, M*; Xu, D*; Kong, D*; Zhang, W-H; Wu, Y N (2025) Place Cells as Multi-Scale Position Embeddings: Random Walk Transition Kernels for Path Planning.pdf Comment:Place cells in hippocampus fire during spatial navigation, where each cell fires at a particular place, thus the name of place cells. Instead of studying individual place cells, we consider the activities of the population of place cells as forming a vector or position embedding, and we assume the inner product (h(x, t), h(y, t)) = q(y|x, t) where h(x, t) is the vector formed by the place cells at scale sqrt(t), and q(y|x, t) is the normalized transition probability of time t (normalized so that q(x|x, t) = 1 for each x, and |h(x, t)| = 1). The scale of sqrt(t) mirrors hippocampal dorsoventral axis. With non-negative constraint on the elements of h(x, t), we can learn localized place fields of the place cells, and they together tile the space. h(x, t) forms a cognitive map at scale sqrt(t). The angles or Euclidean distance between h(x, t) and h(y, t) encodes proximity q(y|x, t).
Path planning at current position x towards goal y is based on following gradient ascent of q(y|x, t) over x, i.e., gradient descent on |h(x, t) - h(y, t)|^2, where t is chosen for maximal magnitude of gradient. This reveals a profound point: in the embedding space, planning follows the straight path!
This method is capable of path planning in complex mazes. It is also capable of remapping with change of the environment. Our scheme P_2t = P_t^2 encodes recursions in dynamic programming and enables hippocampal preplay or systematic extrapolation without the need to learn from successful trajectories.
We also propose a simple and compelling model for theta phase precession, where theta phase is actually the angle.
The 2D coordinate x is represented by the vector g(x) formed by the activities of the population of grid cells, where g(x) has conformal isometry with x in that g(x) preserves the distance in x with different metric units. In other words, g plays the role of x, and a nonlinear function f(x) can be modeled by a linear W g. While grid cells preserve local geometric distance in x, place cells preserve global topological adjacency in x.
Noh, D*; Kong, D*; Zhao, M; Lizarraga, A; Xie, J; Wu, Y N^; Hong, D^ (2025) Latent Adaptive Planner for Dynamic Manipulation. pdfvideo Comment: We learn a latent plan transformer model from human demonstrations and transfer it to real robots with variational re-planning.
Fang, H; Han, B; Erickson, N; Zhang, X; Zhou, S; Dagar, A; Zhang, J; Turkmen, AC; Hu, C; Rangwala, H; Wu, YN; Wang, B; Karypis, G (2025) MLZero: A Multi-Agent System for End-to-end Machine Learning Automation. pdf Comment: Collaboration inside Amazon on agentic AI for machine learning tasks.
Li, H*; Li, C*; Wu, T; Zhu, X; Wang, Y; Yu, Z; Jiang, EH; Zhu, SC; Jia, Z; Wu, YN^; Zheng, Z^ (2025) Seek in the Dark: Reasoning via Test-Time Instance-Level Policy Gradient in Latent Space. pdf Comment: Test-time instance-level policy gradient in latent space = planning or search.
Li, J; Yang Y; Yang S; Zhang L; Wu, YN (2025) Value-Spectrum: Quantifying Preferences of Vision-Language Models via Value Decomposition in Social Media Contexts. ACL 2025 pdf
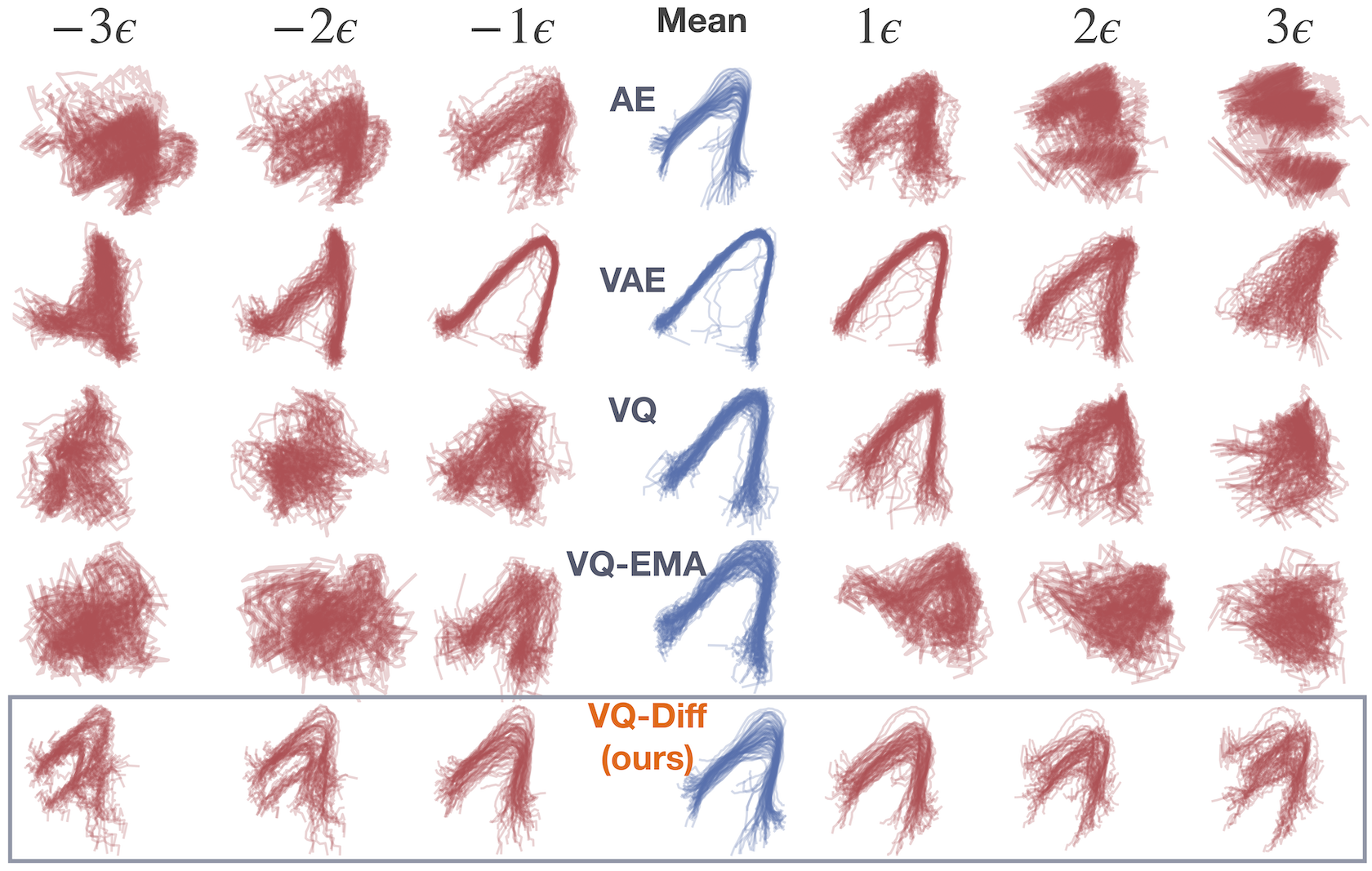
Kong, D*; Zhao, M*; Xu, D*; Pang, B; Wang, S; Honig, E; Si, Z; Li, C; Xie, J^; Xie, S^; Wu, Y N^ (2025) Latent Thought Models with Variational Bayes Inference Time Computation. International Conference on Machine Learning (ICML)pdfblog Comment: A structured prior model in a lifted latent space supports knowledge representation with abstraction and composition, and enables reasoning and planning in a compact abstract space if guided by a reward-verifier model. Posterior inference is based on fast learning of local parameters with classical variational Bayes framework, which complements slow learning of global parameters. The work was inspired by declarative-procedural memory model and language of thought hypothesis in cognitive science.
Liu, C; Wu, C; Song, R; Li, A; Wu, YN; Geng, T (2025) An Expressive and Self-Adaptive Dynamical System for Efficient Equation Learning, International Conference on Machine Learning (ICML). pdf
Zhao, M; Xu, D; Kong, D; Zhang, W-H; Wu, Y N (2025) A minimalistic representation model for head direction system. CogSci 2025.pdf
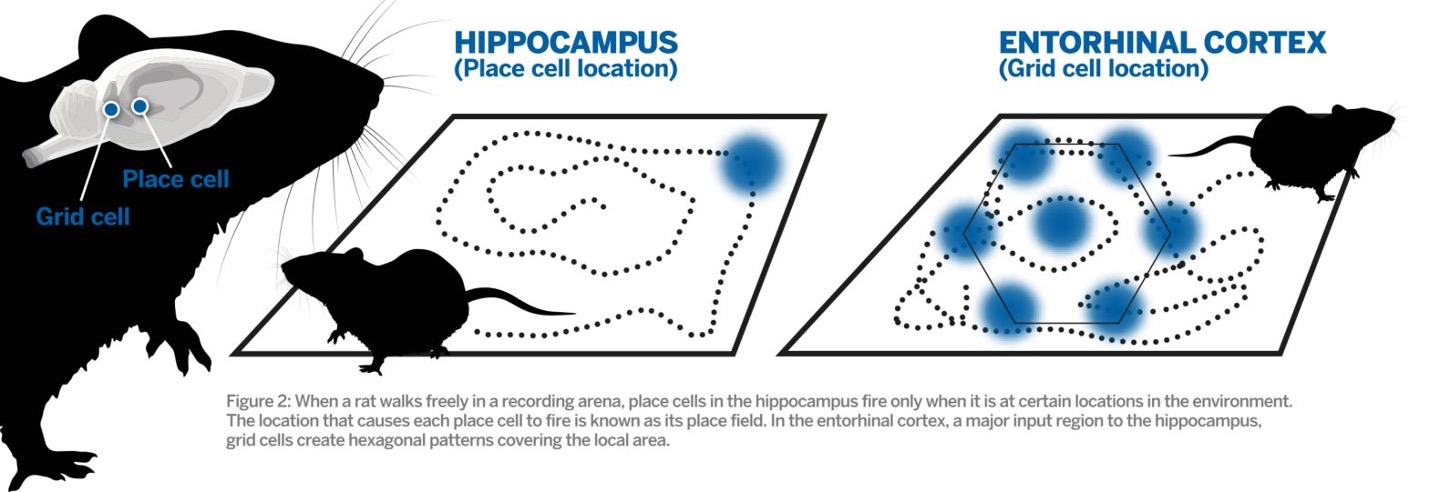
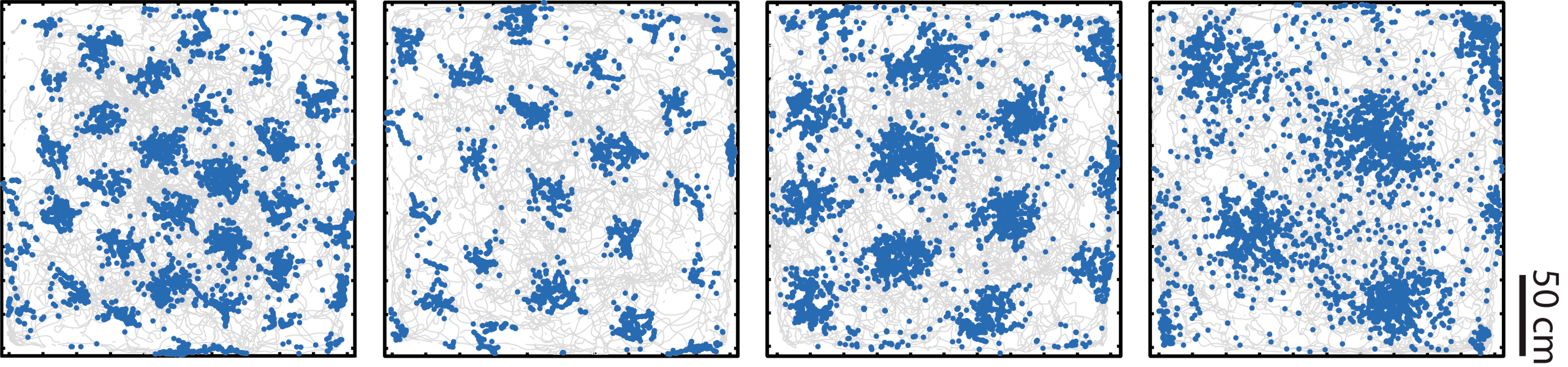
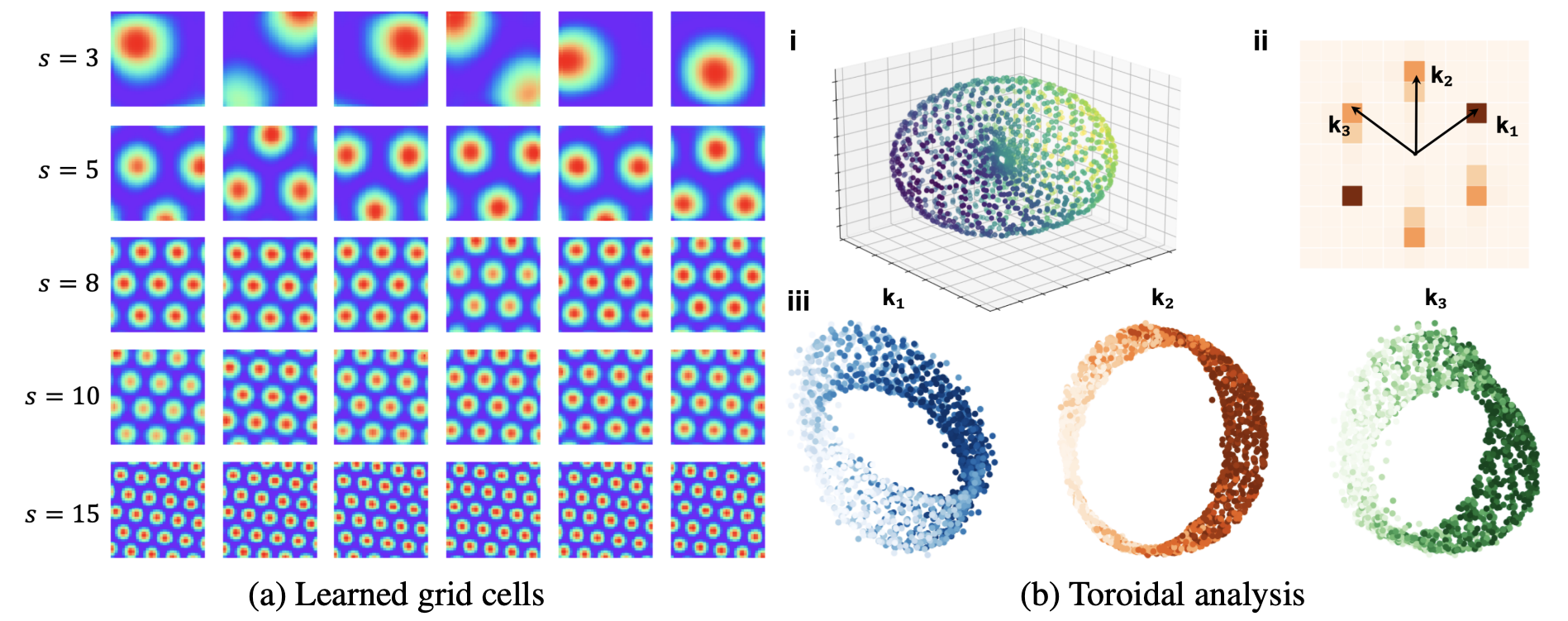
The first three illustrations are taken from internet. Copyrights and my gratitude go to the original authors.
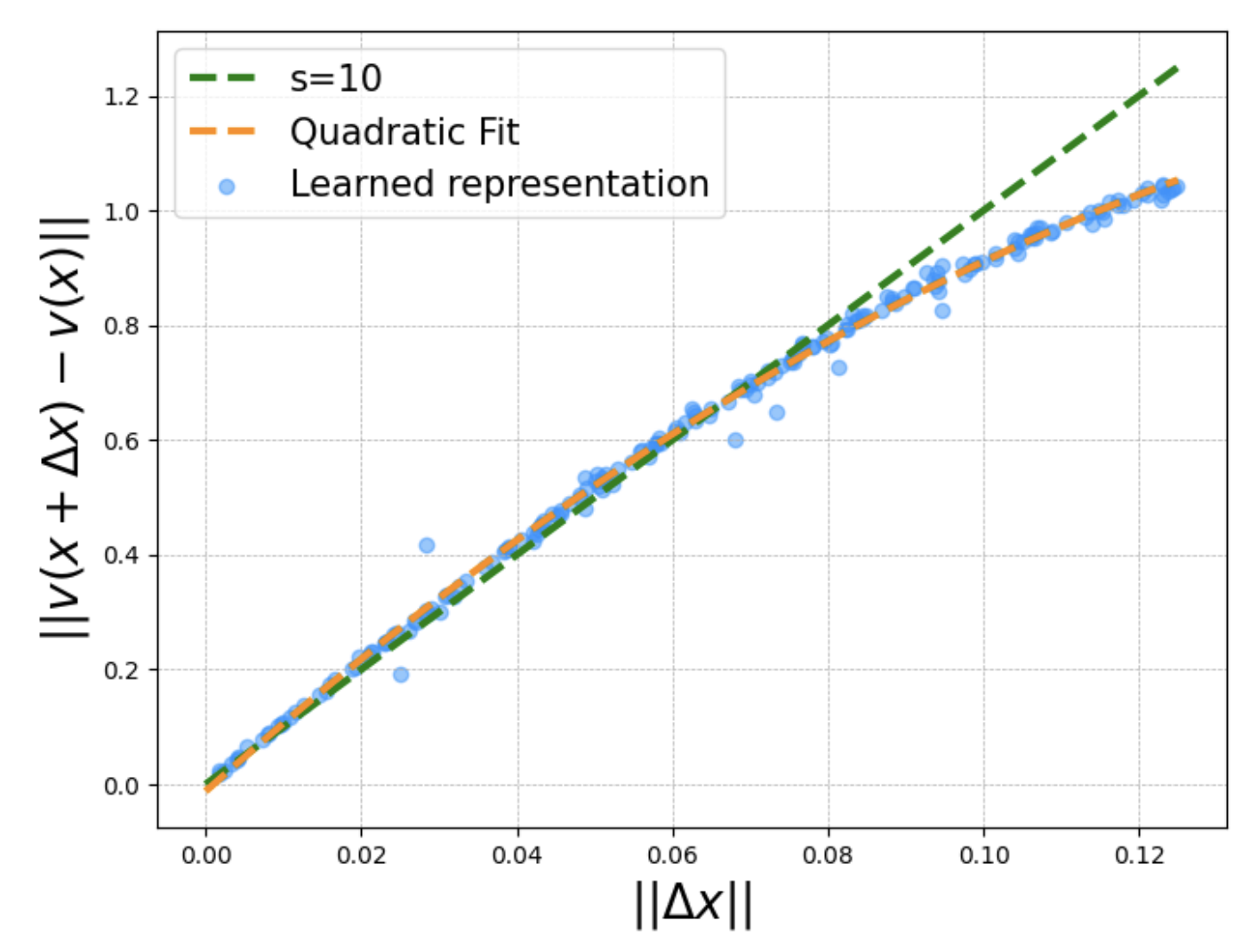
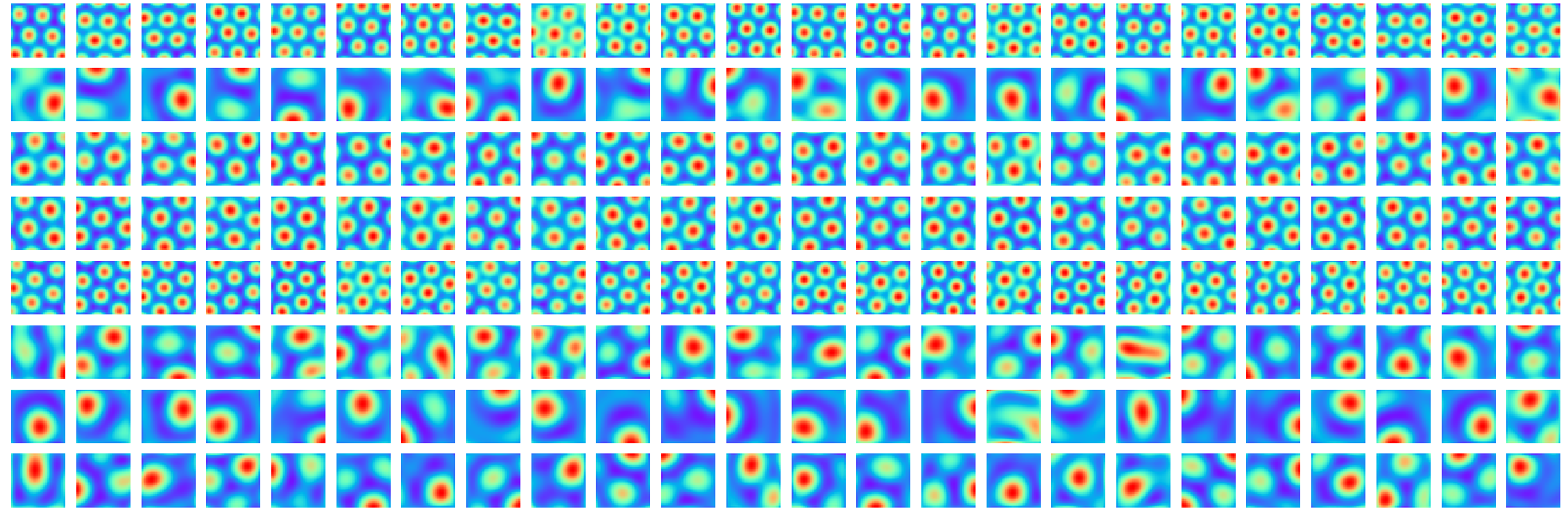
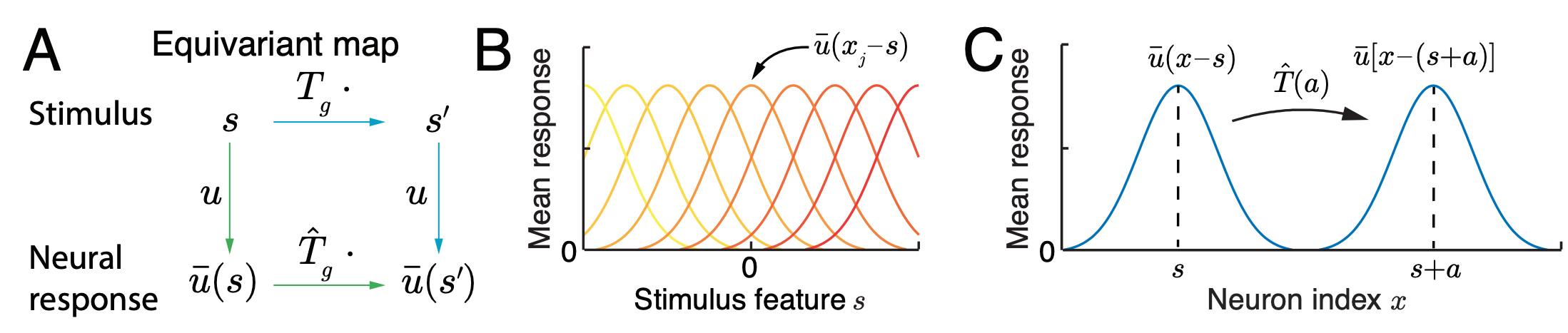
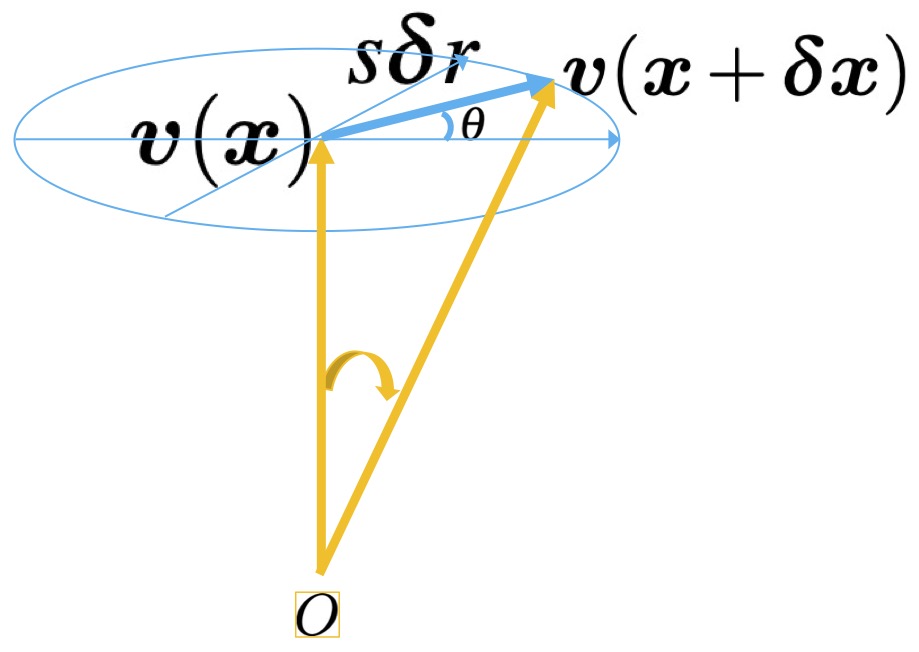
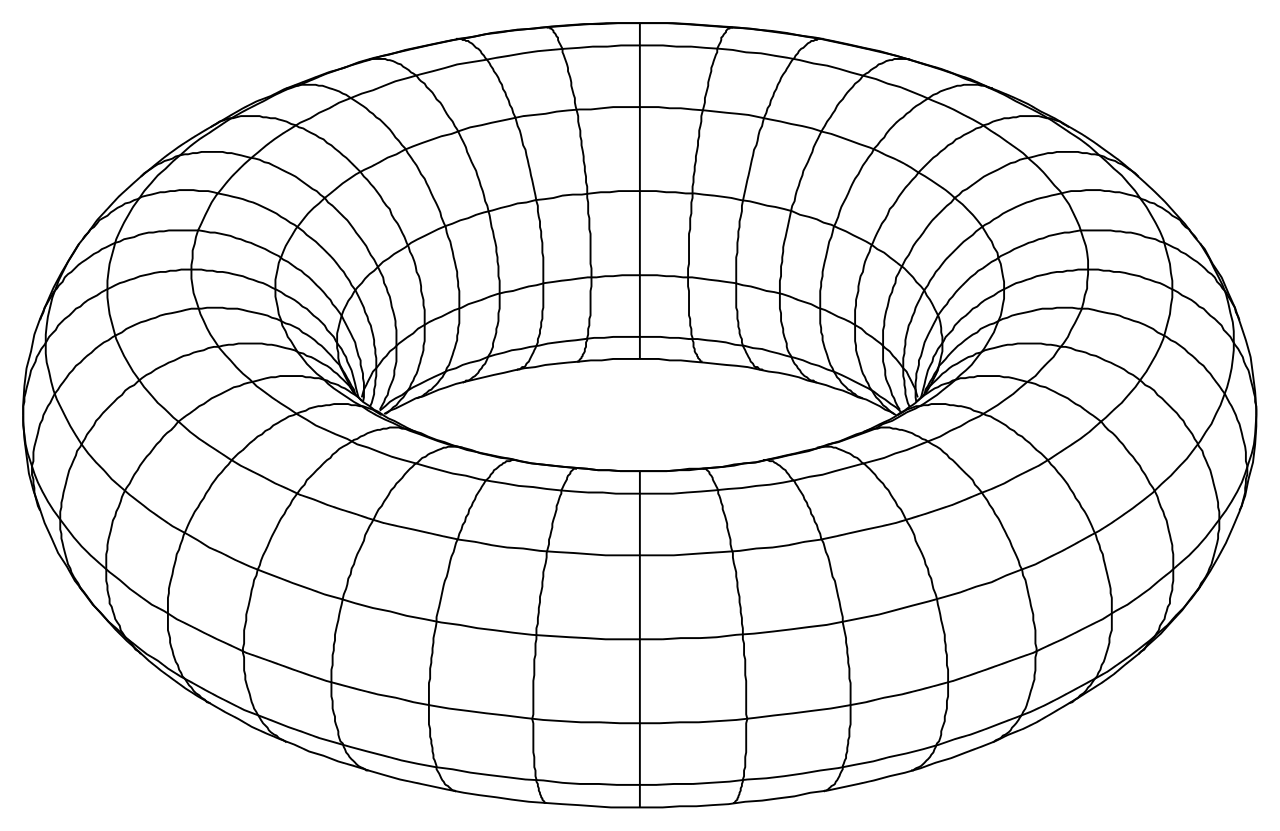
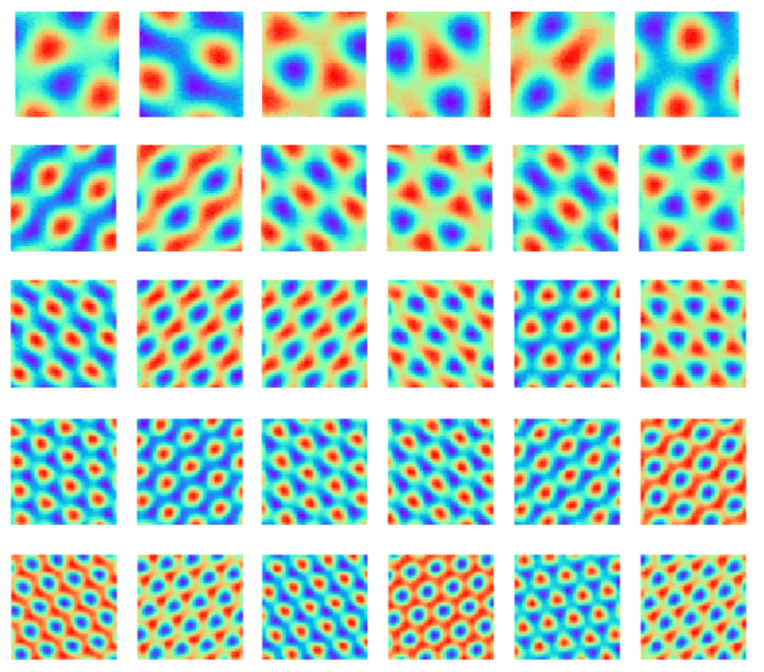
Xu, D; Gao, R; Zhang, W-H; Wei, X-X; Wu, Y N (2025) On Conformal Isometry of Grid Cells: Learning Distance-Preserving Position Embedding. International Conference on Learning Representations (ICLR oral).pdf | slides | project page Comment: Grid cells are so-named because their response maps exhibit striking hexagonal periodic grid patterns as the agent (a rat or a human) navigates in the environment. We have elucidated a simple and compelling mathematical principle called conformal isometry that underlies the hexagonal grid patterns, by showing that the hexagonal flat torus is maximally distance preserving because it distributes the extrinsic curvature uniformly over directions.
Specifically, the activities of each sub-population (or module) of grid cells form a vector representation of the position of the agent in 2D physical space, i.e., the vector is a position embedding, and the 2D physical space is embedded as a 2D manifold in the high dimensional neural space. Conformal isometry means this 2D manifold preserves the local geometry such as distance and angle of the 2D physical space, where for different sub-populations, the distance is measured in different metrics (e.g., meter or centimeter), leading to different scaling factors. Essentially each sub-population of grid cells serves as a coordinate map of a certain metric that is overlaid on the 2D physical space. As such, it is imperative for the coordinate map to be conformal to the 2D physical space so that the agent has correct sense of distance and angle for navigation.
The high dimensional vector formed by the activities of the whole population of grid cells also serves as a set of linear basis functions for representing place cell activities, forming a cognitive map of the environment that can be learned by a fast learning mechanism.
To summarize, let v(x) be the embedding of position x, where v(x) is the vector of activities of grid cells at x. Essentially v plays the role of x, and a nonlinear f(x) can be modeled by a linear W v.
Hong, Y; Liu, B; Wu, M; Zhai, Y; Chang, K-W; Li, L; Lin, K; Lin, C-C; Wang, J; Yang, Z^; Wu, Y. N.^; Wang, L^ (2025) SlowFast-VGen: Slow-Fast Learning for Action-Driven Long Video Generation. International Conference on Learning Representations (ICLR).pdf | project page | talk Comment: The work is inspired by the complementary learning framework with fast learning of episodic memory in hippocampus and slow learning of semantic memory in neocortex.
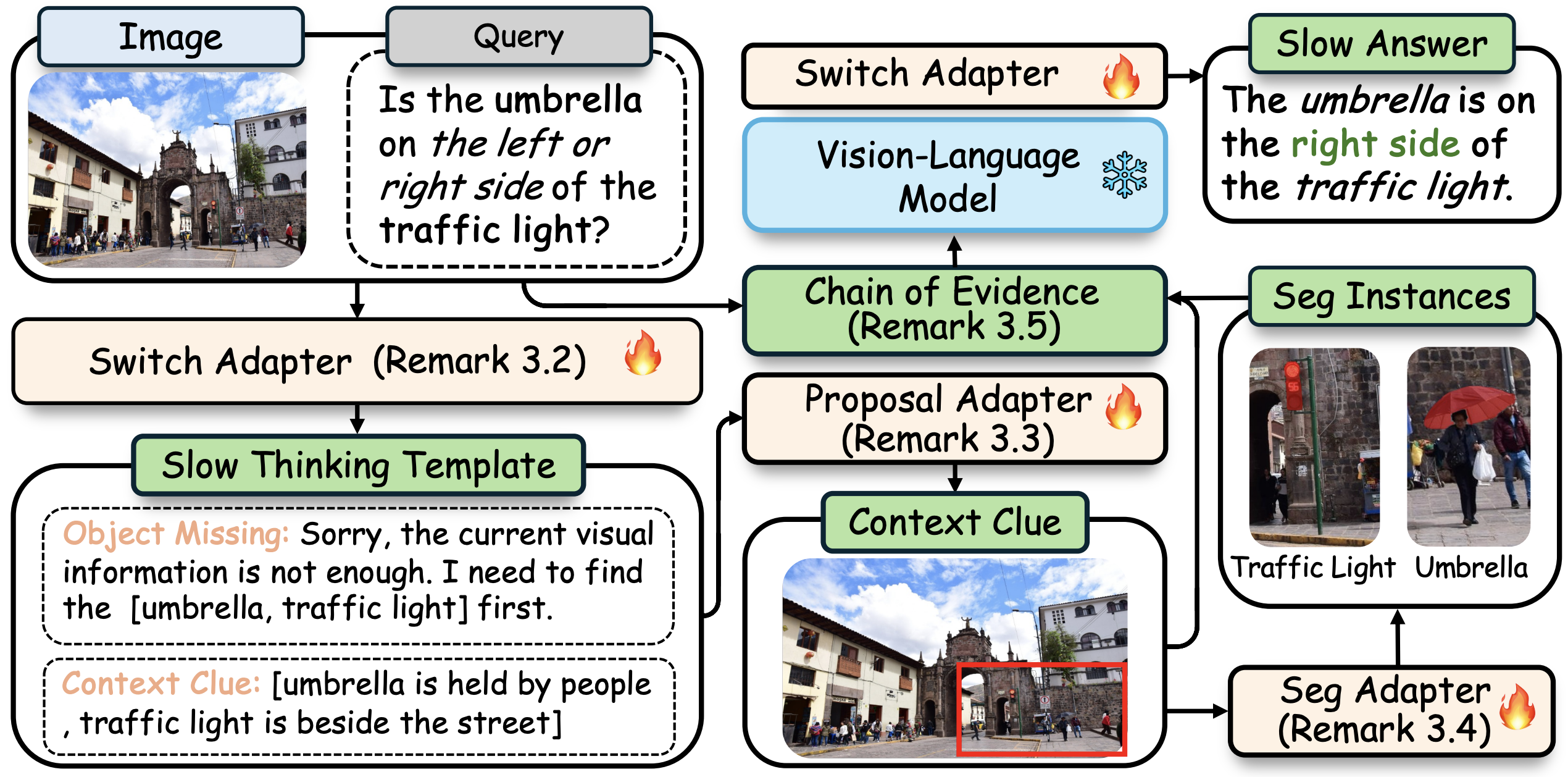
Sun, G; Jin, M; Wang, Z; Wang, C L; Ma, S; Wang, Q; Geng, T; Wu, Y N; Zhang, Y; Liu, D (2025) Visual Agents as Fast and Slow Thinkers. International Conference on Learning Representations (ICLR). pdf
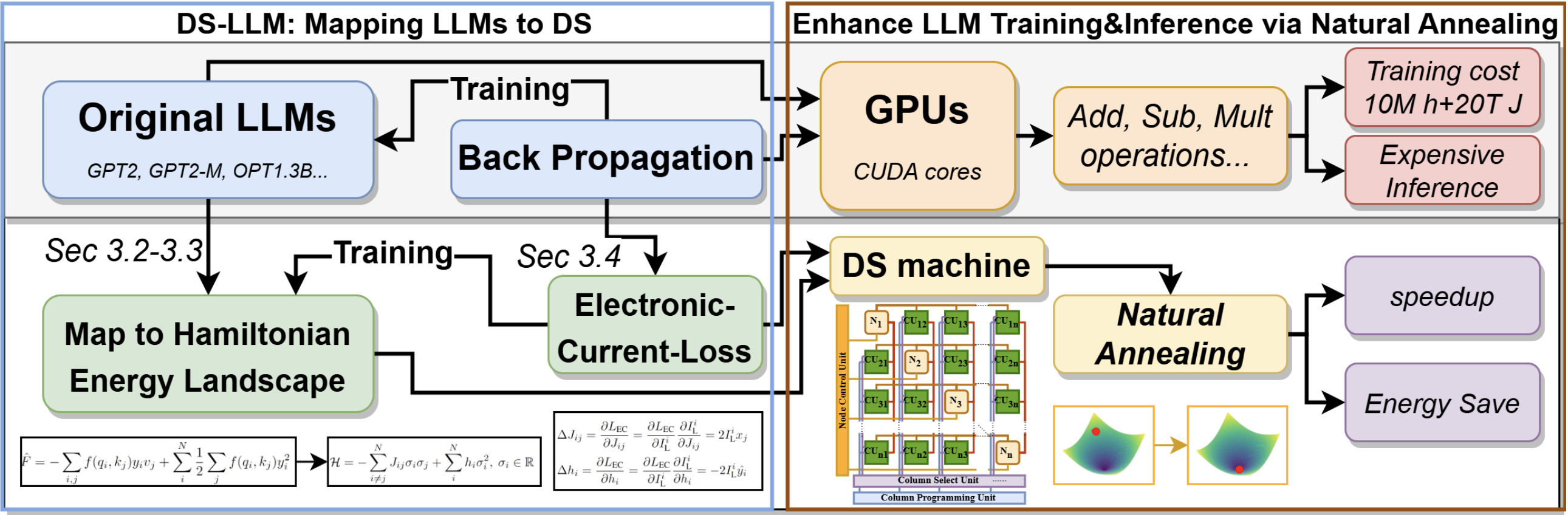
Song, R; Liu, C; Wu, C; Li, A; Liu, D; Wu, Y N; Geng, T (2025) DS-LLM: Leveraging Dynamical Systems to Enhance Both Training and Inference of Large Language Models. International Conference on Learning Representations (ICLR). pdf
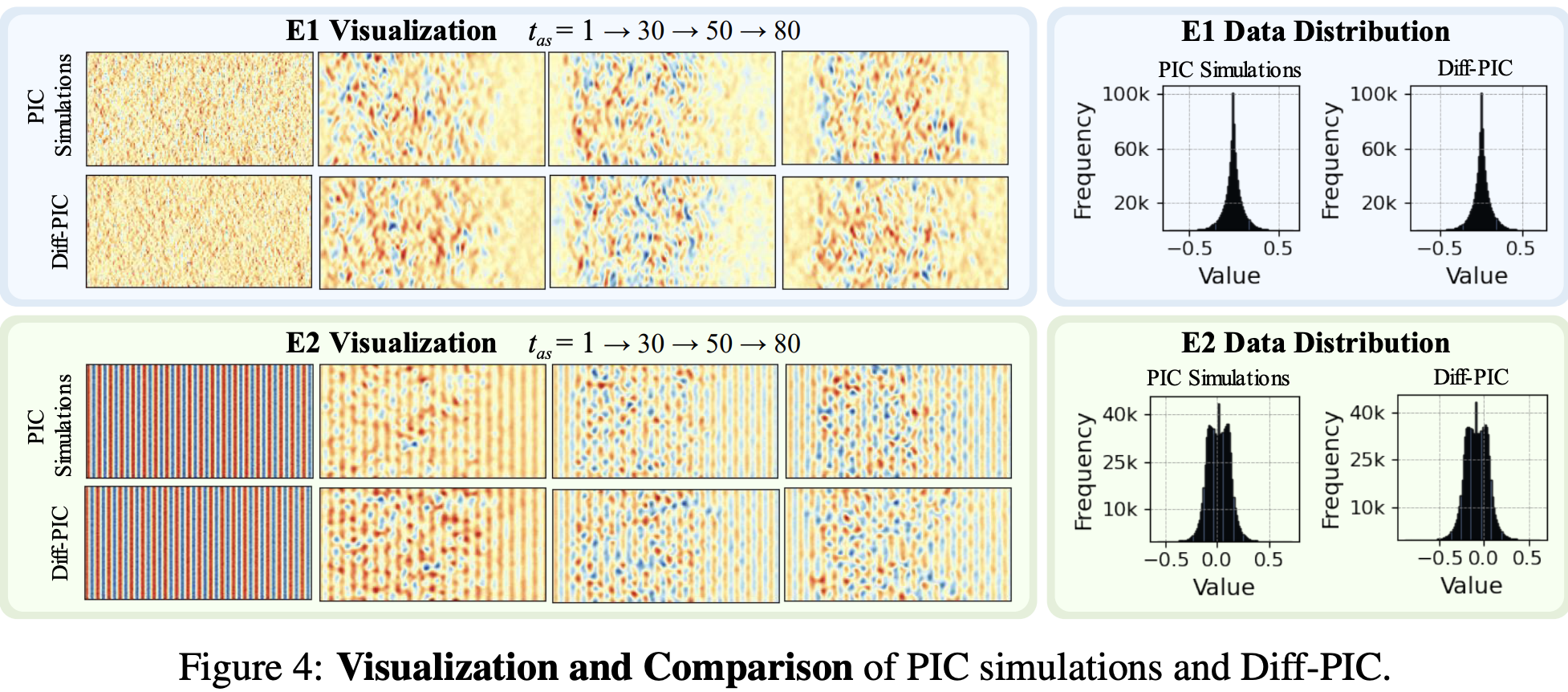
Liu, C; Wu, C; Cao, S; Chen, M; Liang, J C; Li, A; Huang, M; Ren, C; Wu, Y N; Liu, D; Geng, T (2025) Diff-PIC: Revolutionizing Particle-In-Cell Nuclear Fusion Simulation with Diffusion Models. International Conference on Learning Representations (ICLR). pdf
Wang, S; Ji, L; Wang, R; Zhao, W; Liu, H; Hou, Y; Wu, Y N (2025) Explore the Reasoning Capability of LLMs in the Chess Testbed. Annual Conference of the Nations of the Americas Chapter of the ACL (NAACL). pdf Zhao, T; Singh, K Y; Appalaraju, S; Tang, P; Wu, Y N; Li, L E (2025) On the Analysis and Distillation of Emergent Outlier Properties in Pre-trained Language Models. Annual Conference of the Nations of the Americas Chapter of the ACL (NAACL). pdf Ren, J; Zheng, X; Liu, J; Lizarraga, A; Wu, Y N; Lin, L; Zhang, Q (2025) Monitoring Primitive Interactions During the Training of DNNs. AAAI. pdf
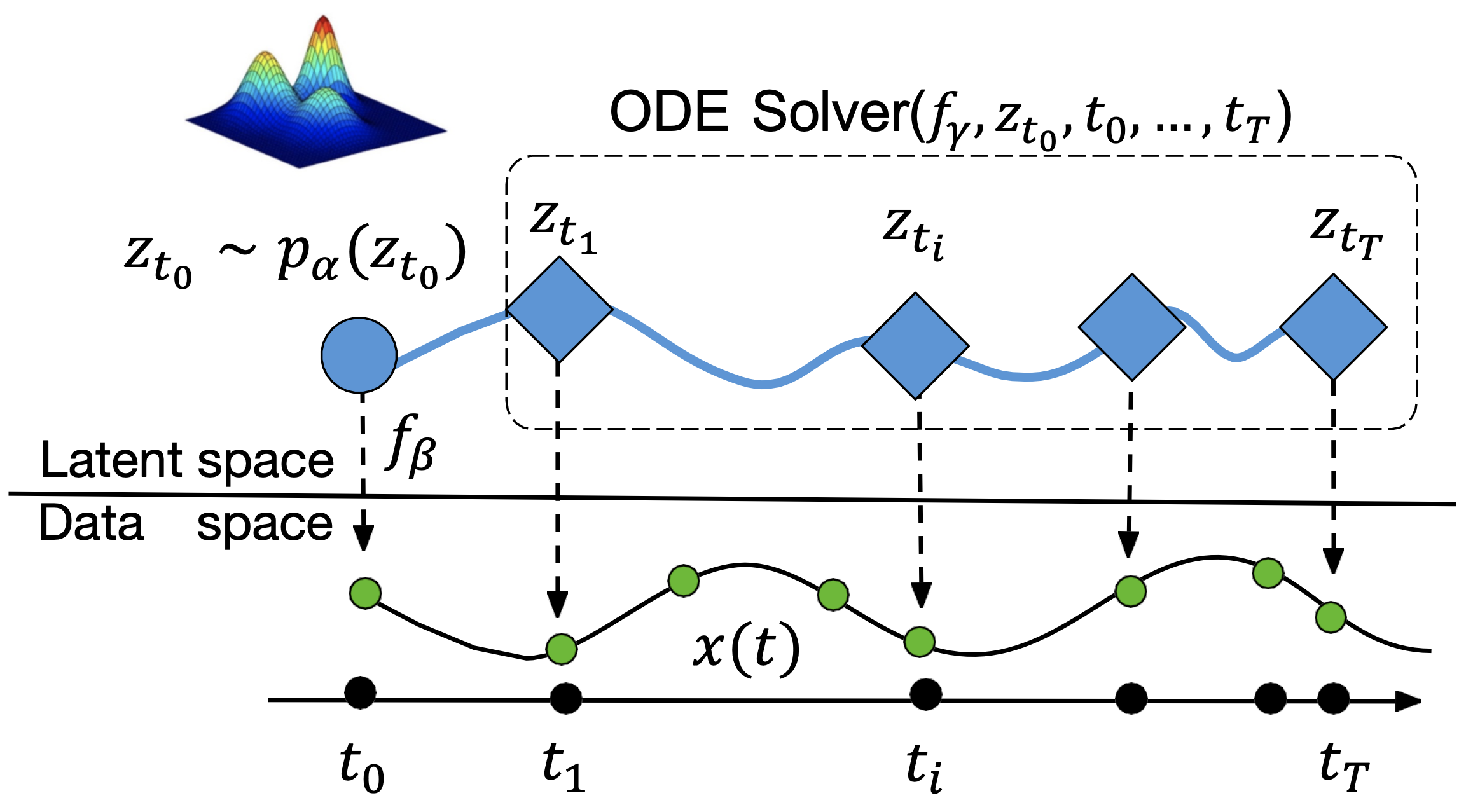
Cheng, S*; Kong, D*; Xie, J; Lee, K; Wu, Y N^; Yang, Y^ (2025) Latent Space Energy-based Neural ODEs. Transactions on Machine Learning Research (TMLR). pdf Wu, C; Song, R; Liu, C; Wang, Y; Chen, Y; Li, A; Liu, D; Wu, Y N; Huang, M; Geng, T (2024) NP-NDS: A Nature-Powered Nonlinear Dynamical System for Power Grid Forecasting. The Third Learning on Graphs Conference (LoG). pdf
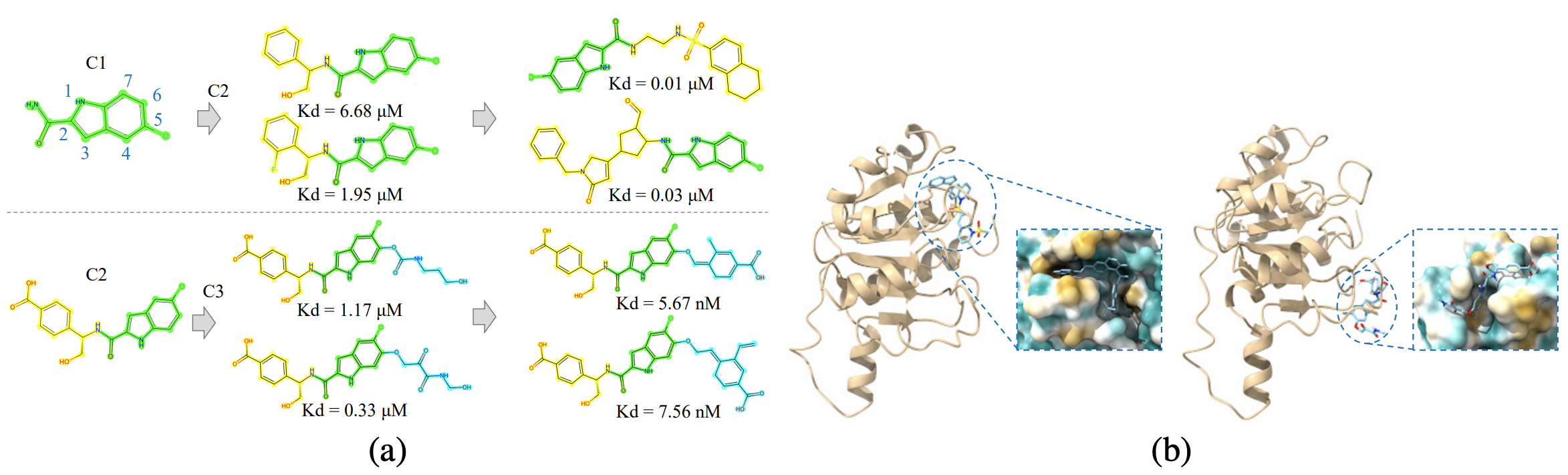
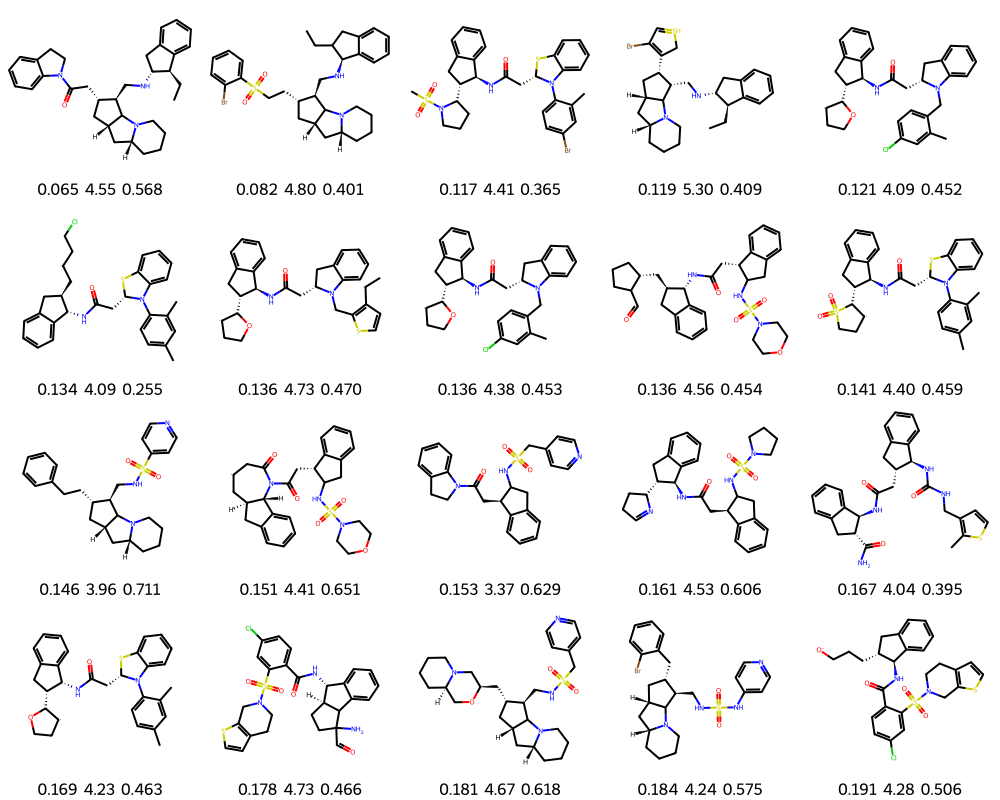
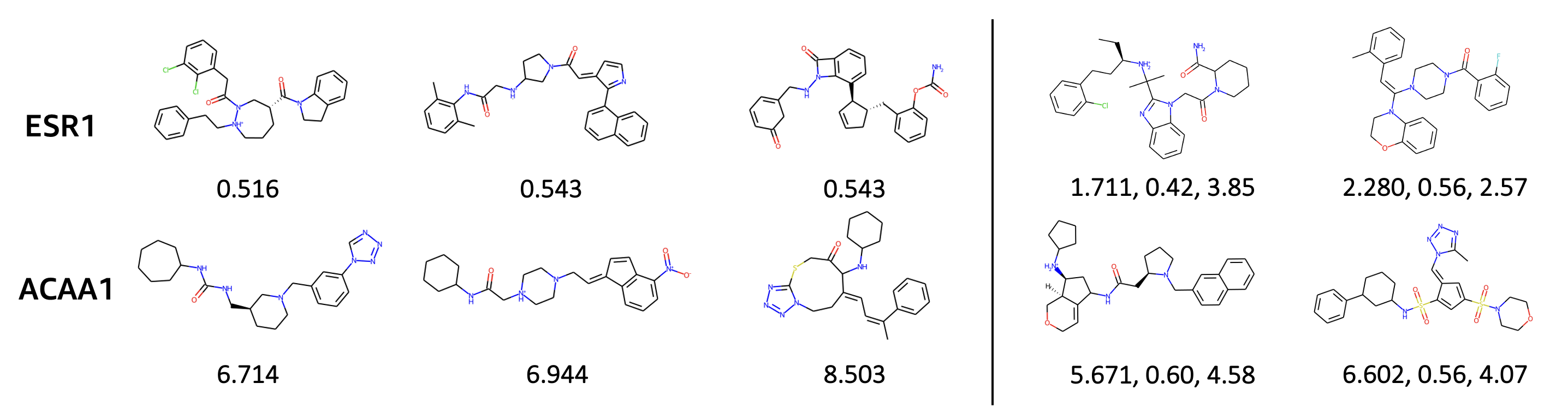
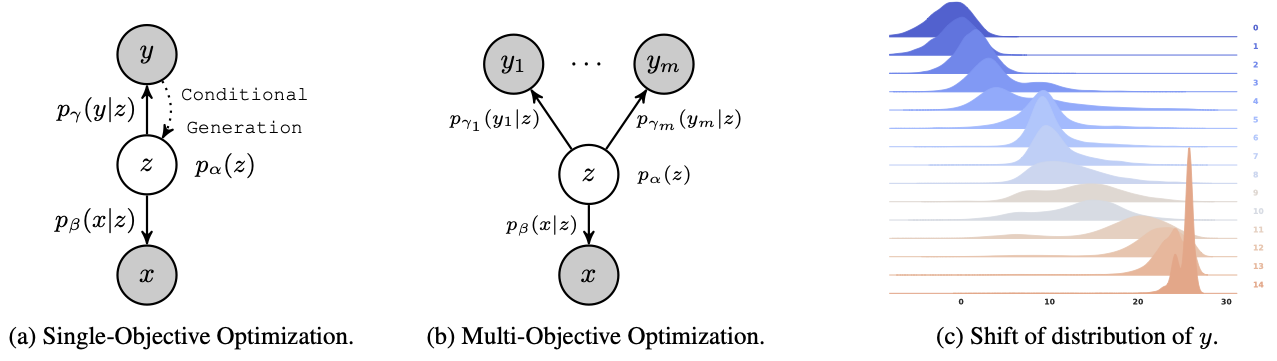
Kong, D*; Huang, Y*; Xie, J*; Honig, E*; Xu, M; Xue, S; Lin, P; Zhou, S; Zhong, S; Zheng, N; Wu, Y N (2024) Molecule Design by Latent Prompt Transformer. Advances in Neural Information Processing Systems (NeurIPS).pdfproject page Comment: The latent vector z serves as an abstract latent design for the molecule. Gradient-based optimization of the continuous latent design is more convenient than searching in the discrete molecule space. Our online optimization algorithm maintains and updates a replay buffer of good molecules together with a learned generative model, so that novel and potentially better molecules can be generated.
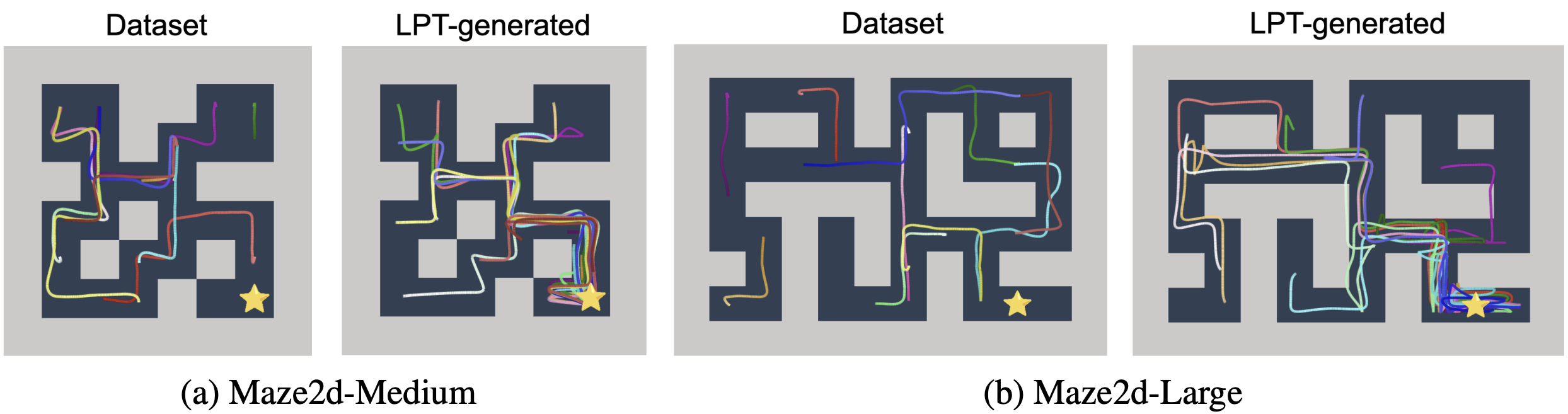
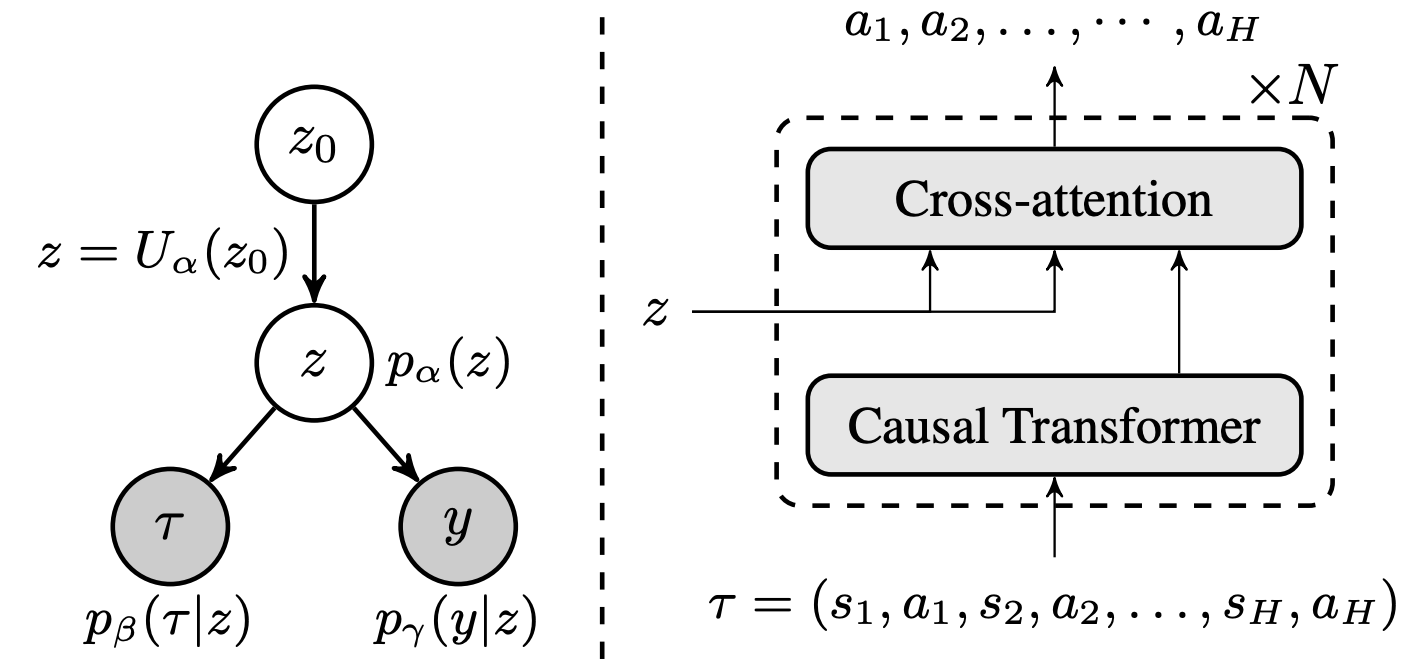
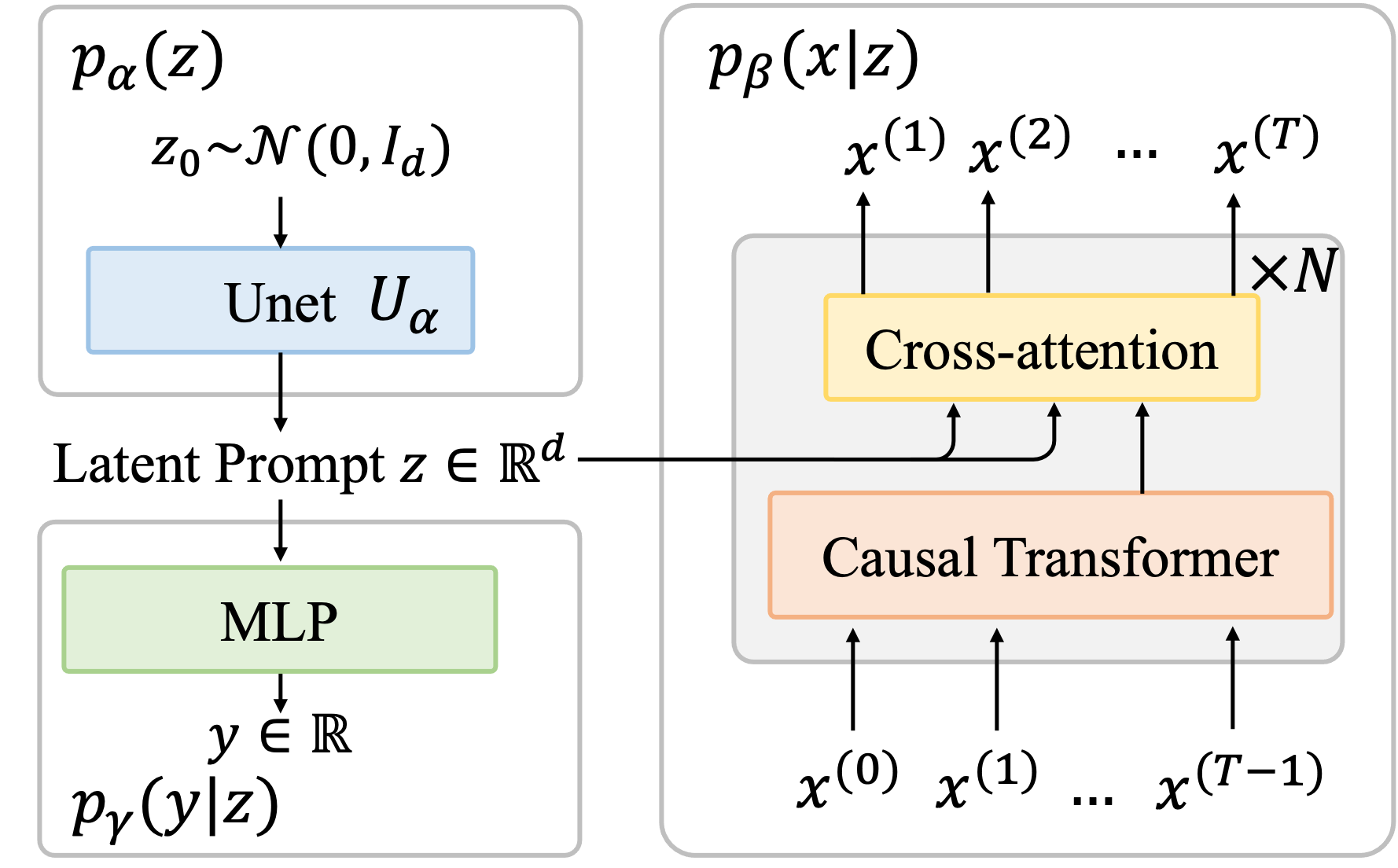
Kong, D*; Xu, D*; Zhao, M*; Pang, B; Xie, J; Lizarraga, A; Huang, Y; Xie, S*; Wu, Y N (2024) Latent Plan Transformer for Trajectory Abstraction: Planning as Latent Space Inference. Advances in Neural Information Processing Systems (NeurIPS).pdfproject page Comment: The latent vector z serves as an abstract latent plan that controls the generation of action in each timestep. We only need to evaluate the whole plan without stepwise rewards, thus avoiding the difficult credit assignment problem. The latent plan can be updated during execution with re-planning, similar to model predictive control.
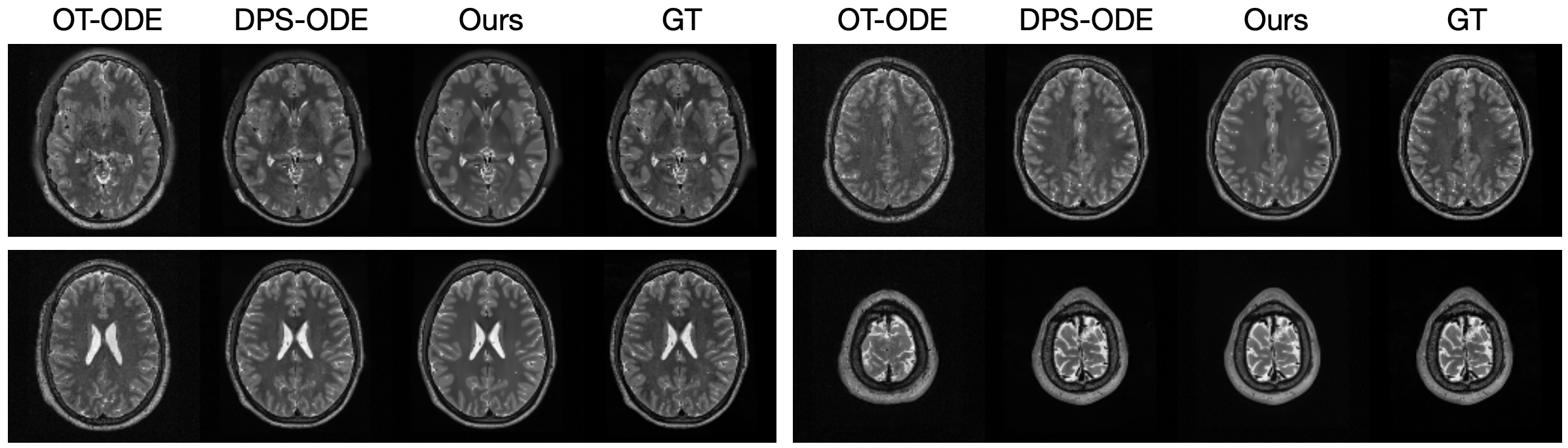
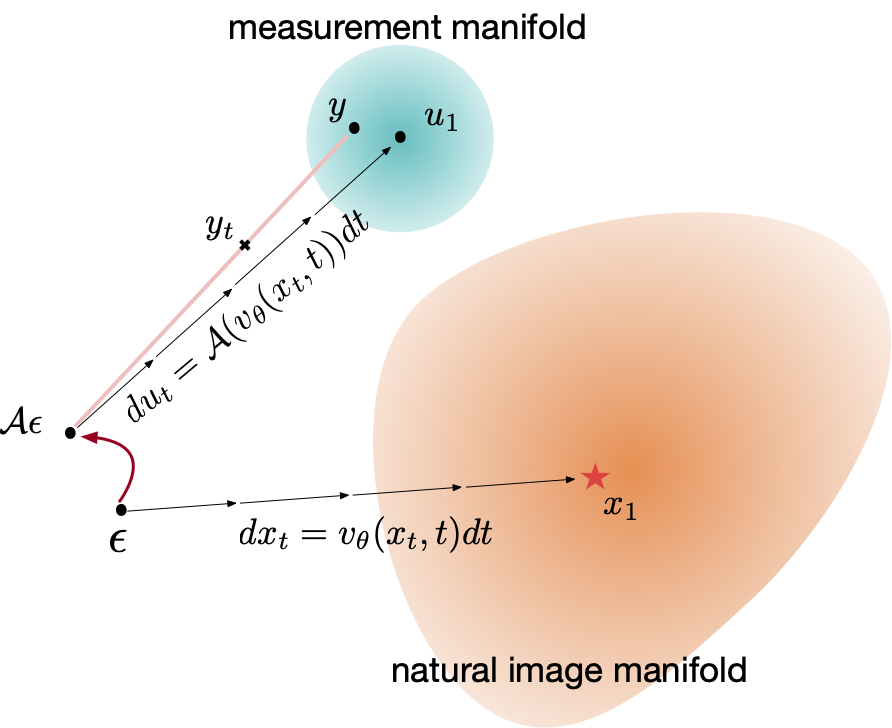
Zhang, Y; Yu, P; Zhu, Y; Chang, Y; Gao, F; Wu, Y N; Leong, O (2024) Flow Priors for Linear Inverse Problems via Iterative Corrupted Trajectory Matching. Advances in Neural Information Processing Systems (NeurIPS).pdf
Xie, S; Xiao, Z; Kingma, D; Hou, T; Wu, Y N; Murphy, K; Salimans, T; Poole, B; Gao, R (2024) EM Distillation for One-step Diffusion Models. Advances in Neural Information Processing Systems (NeurIPS).pdf
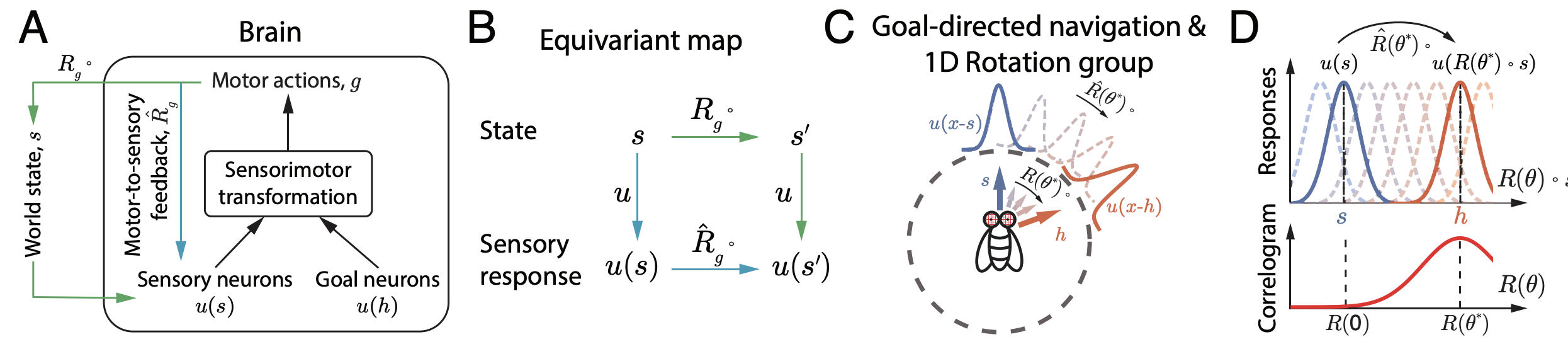
Zuo, J; Wu, Y N; Wu, S; Zhang, W (2024) The motion planning neural circuit in goal-directed navigation as Lie group operator search. Advances in Neural Information Processing Systems (NeurIPS).pdf Zeng, R; Han, C; Wang, Q; Wu, C; Geng, T; Huang, L; Wu, Y N; Liu, D (2024) Visual Fourier Prompt Tuning. Advances in Neural Information Processing Systems (NeurIPS).pdf
Chen, Y; Xie, T; Zong, Z; Li, X; Gao, F; Yang, Y; Wu, Y N; Jiang, C (2024) Atlas3D: Physically Constrained Self-Supporting Text-to-3D for Simulation and Fabrication. Advances in Neural Information Processing Systems (NeurIPS).pdf
Lizarraga, A; Jiang, E H; Nowack, J; Li, Y Q; Wu, Y N; Boscoe, B; Do, T (2024) Learning the Evolution of Physical Structure of Galaxies via Diffusion Models. Machine Learning and the Physical Sciences Workshop at Advances in Neural Information Processing Systems (NeurIPS).pdfproject page Zhao, M; Xu, D; Kong, D; Zhang, W-H; Wu, Y N (2024) A minimalistic representation model for head direction system. Workshop on Symmetry and Geometry in Neural Representations (NeurReps) at Advances in Neural Information Processing Systems (NeurIPS).pdf Zeng, Y; Zhao, Y; Wu, Y N (2024) Triple Regression for Camera Agnostic Sim2Real Robot Grasping and Manipulation Tasks. CoRoboLearn Workshop at Conference on Robot Learning (CoRL).pdf Qian, Y; Yu, P; Wu, Y N; Su, Y; Wang, W; Fan, L (2024) Learning Concept-Based Causal Transition and Symbolic Reasoning for Visual Planning. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).pdf
Wang, S; Han, M; Jiao, Z; Zhang, Z; Wu, Y N; Zhu, S-C; Liu, H (2024) LLM3: Large Language Model-based Task and Motion Planning with Motion Failure Reasoning. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).pdf
Han, M; Zhu, Y; Zhu, S-C; Wu, Y N; Zhu, Y (2024) INTERPRET: Interactive Predicate Learning from Language Feedback for Generalizable Task Planning. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).pdf
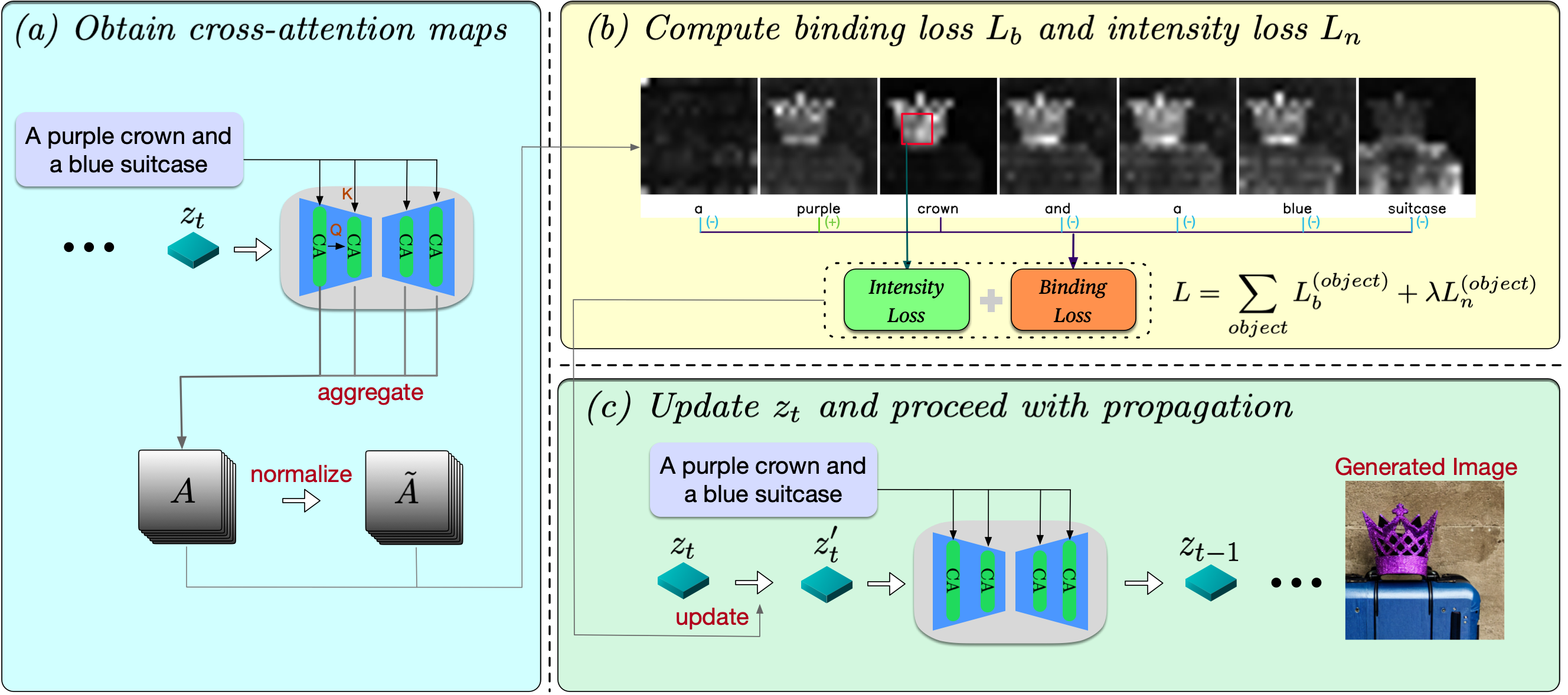
Zhang, Y; Yu, P; Wu, Y N (2024) Object-Conditioned Energy-Based Attention Map Alignment in Text-to-Image Diffusion Models. European Conference on Computer Vision (ECCV).pdf Chang, Y; Zhang, Y; Fang, Z; Wu, Y N; Bisk, Y; Gao, F (2024) Generalization in Text-to-Image Generation. European Conference on Computer Vision (ECCV).pdf Kong, D; Khan, F; Zhang, X; Singhal, P; Wu, Y N (2024) Long-Term Social Interaction Context: The Key to Egocentric Addressee Detection. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).pdf Zhang, Q; An, D; Xiao, T; He, T; Tang, Q; Wu, Y N; Tighe, J; Xing, Y (2024) Learning for Transductive Threshold Calibration in Open-World Recognition. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).pdf
Han, C; Liang, J C; Wang, Q; Rabbani, M; Dianat, S; Rao, R; Wu, Y N; Liu, D (2024) Image Translation as Diffusion Visual Programmers. International Conference on Learning Representations (ICLR).pdf Zhu, Y; Xie, J; Wu, Y N; Gao, R (2024) Learning Energy-Based Models by Cooperative Diffusion Recovery Likelihood. International Conference on Learning Representations (ICLR).pdf Zhang, Q; Xu, L; Tang, Q; Fang, J; Wu, Y N; Tighe, J; Xing, Y (2024) Threshold-Consistent Margin Loss for Open-World Deep Metric Learning. International Conference on Learning Representations (ICLR).pdf
Li, Q; Zhu, Y; Liang, Y; Wu, Y N; Zhu, S-C; Huang, S (2024) Neural-Symbolic Recursive Machine for Systematic Generalization. International Conference on Learning Representations (ICLR).pdf
Zhao, T; Singh, K Y; Appalaraju, S; Tang, P; Mahadevan, V; Manmatha, R; Wu, Y N (2024) No Head Left Behind - Multi-Head Alignment Distillation for Transformers. AAAI Conference on Artificial Intelligence (AAAI).pdf
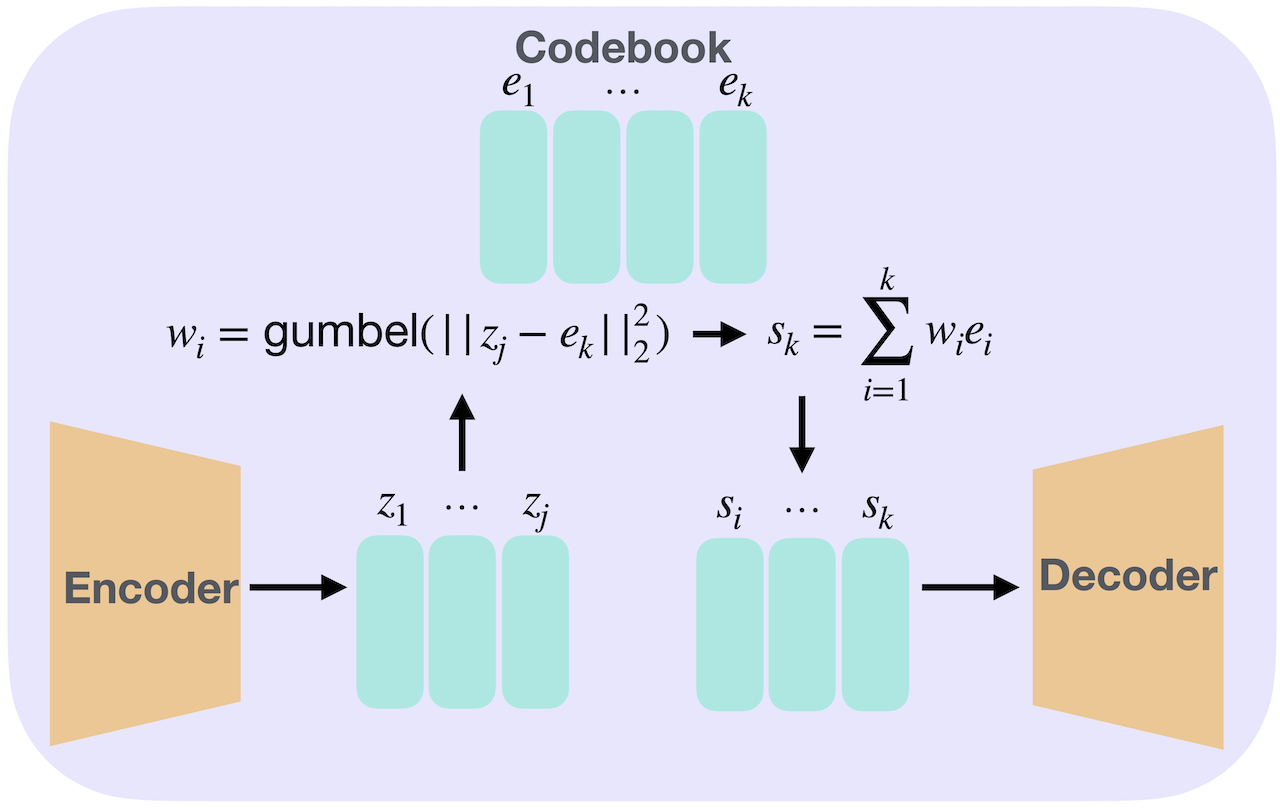
Lizarraga, A; Taraku, B; Honig, E; Wu, Y N; Joshi, S H (2024) Differentiable VQ-VAE's for Robust White Matter Streamline Encodings. IEEE International Symposium on Biomedical Imaging (ISBI).pdf D Kong, Y Huang, J Xie, YN Wu (2023) Molecule design by latent prompt transformer. NeurIPS 2023 AI for Science Workshop.
pdf Comment: The latent prompt transformer model assumes a latent vector z that follows a learnable prior model, and z serves as the prompts for a GPT-like generation model. z can also predict the property y by a prediction model. Our optimization method integrates Bayesian optimization and generative modeling.
D Xu, R Gao, WH Zhang, XX Wei, and YN Wu (2023) Conformal normalization in recurrent network of grid cells.
pdf Comment: We propose a simple and general normalization scheme that makes the RNN model conformal, in that the displacement of the position embedding is proportion to the displacement of the agent in the environment. We also provide mathematical understanding that connects the conformal normalization to the emergence of hexagon grid patterns observed in biological grid cells.
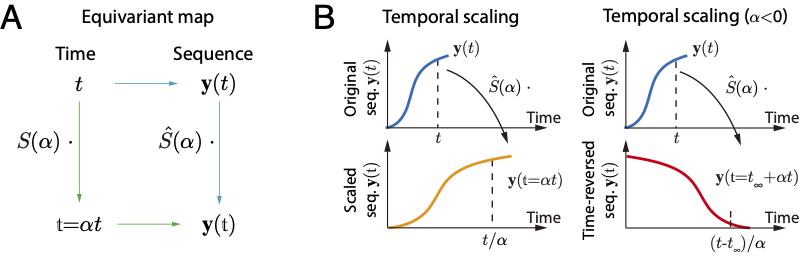
P Yu, Y Zhu, S Xie, X Ma, R Gao, SC Zhu, YN Wu (2023) Learning energy-based prior model with diffusion-amortized MCMC. Advances in Neural Information Processing Systems (NeurIPS, 2023). pdf J Zuo, X Liu, YN Wu, S Wu, WH Zhang (2023) A recurrent neural circuit mechanism of temporal-scaling equivariant representation. Advances in Neural Information Processing Systems (NeurIPS, 2023).
pdf P Lu, B Peng, H Cheng, M Galley, KW Chang, YN Wu, SC Zhu, J Gao (2023) Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models. Advances in Neural Information Processing Systems (NeurIPS, 2023).
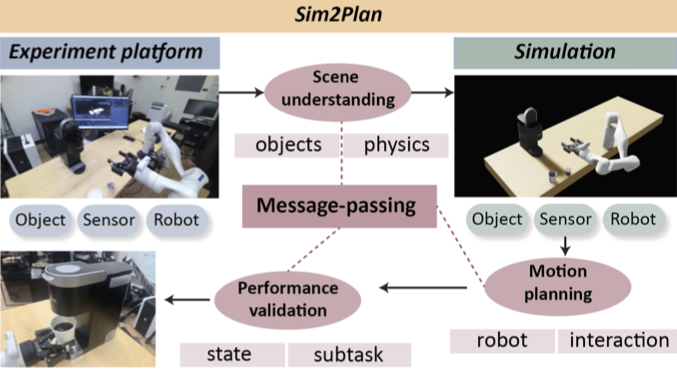
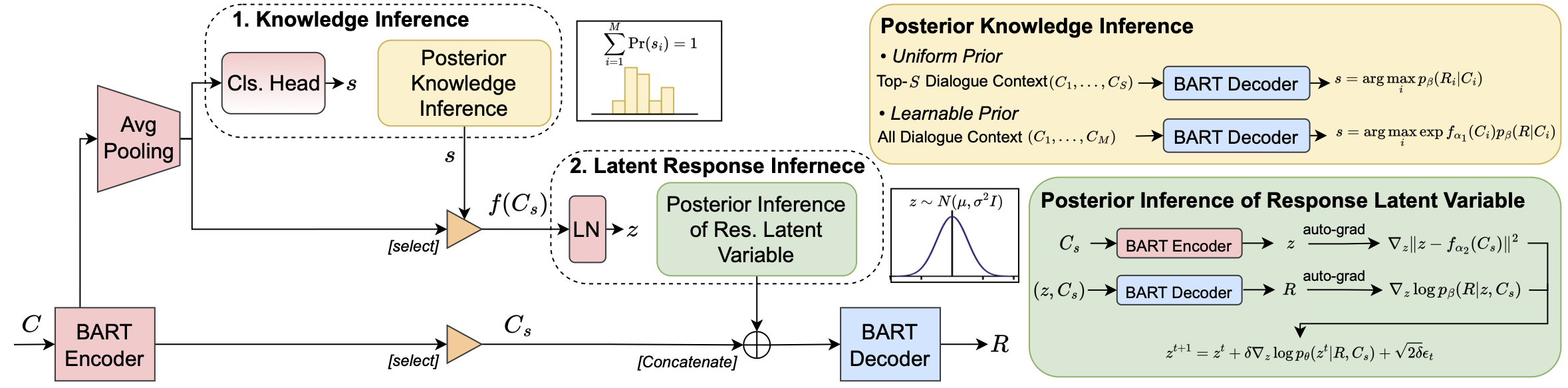
pdf D Kong, B Pang, T Han, and YN Wu (2023) Molecule design by latent space energy-based modeling and gradual distribution shifting. Uncertainty in Artificial Intelligence (UAI, 2023). pdf Y Zhao, Y Zeng, Q Long, YN Wu, SC Zhu (2023) Sim2Plan: robot motion planning via message passing between simulation and reality. The Future Technologies Conference, 2023. pdf Y Xu*, D Kong*, D Xu, Z Ji, B Pang, P Fung*, YN Wu* (2023) Diverse and faithful knowledge-grounded dialogue generation via sequential posterior inference. International Conference on Machine Learning (ICML 2023). pdf YZ Shi, M Xu, JE Hopcroft, K He, JB. Tenenbaum, SC Zhu, YN Wu, W Han, Y Zhu (2023) On the complexity of Bayesian generalization. International Conference on Machine Learning (ICML 2023).
pdf J Cui, YN Wu, and T Han (2023) Learning hierarchical features with joint latent space energy-based prior. IEEE International Conference on Computer Vision (ICCV, 2023).
pdf J Cui, YN Wu, and T Han (2023) Learning joint latent space EBM prior model for multi-layer generator. Conference on Computer Vision and Pattern Recognition (CVPR, 2023).
pdf P Lu, L Qiu, KW Chang, YN Wu, SC Zhu, T Rajpurohit, P Clark, A Kalyan (2023) Dynamic prompt learning via policy gradient for semi-structured mathematical reasoning. International Conference on Learning Representations (ICLR, 2023).
pdf Q Li, S Huang, Y Hong, Y Zhu, YN Wu, SC Zhu (2023) A minimalist dataset for systematic generalization of perception, syntax, and semantics. International Conference on Learning Representations (ICLR, 2023).
pdf C Challu, P Jiang, YN Wu, L Callot (2023) SpectraNet: multivariate forecasting and imputation under distribution shifts and missing data. Workshop on Machine Learning for IoT: Datasets, Perception, and Understanding, International Conference on Learning Representations (ICLR, 2023).
pdf
D Xu*, R Gao*, WH Zhang, XX Wei, and YN Wu (2022). Conformal isometry of Lie group representation in recurrent network of grid cells. Symmetry and Geometry in Neural Representations (NeurReps Workshop), Neural Information Processing Systems (NeurIPS, 2022).
pdf | slides | project page Comment: Algebraically, the recurrent network of grid cells must be a Lie group representation in order to perform path integration. The Peter-Weyl theory connects the two roles of grid cells, namely path integration and basis expansion. Geometrically, the conformal isometry condition seems the simplest condition for the emergence of hexagon grid patterns. Topologically, a compact and connected abelian Lie group is automatically a torus.
WH Zhang, YN Wu, and S Wu (2022). Translation-equivariant representation in recurrent networks with a continuous manifold of attractors. Advances in Neural Information Processing Systems (NeurIPS, 2022). pdf P Yu, S Xie, X Ma, B Jia, B Pang, R Gao, Y Zhu, SC Zhu, and YN Wu (2022). Latent diffusion energy-based model for interpretable text modeling. International Conference on Machine Learning (ICML 2022). pdf | project page Comment: In latent space, the prior distribution of the latent vector is close to Gaussian. The latent space energy-based model modifies the Gaussian with a simple energy function. For ease of sampling, we learn energy functions at different noise levels of the latent vector, together with variational inference model.
L Yuan, X Gao, Z Zheng, M Edmonds, YN Wu, F Rossano, H Lu, Y Zhu, and SC Zhu (2022). In situ bidirectional human-robot value alignment. Science Robotics. pdf Y Xu, J Xie, T Zhao, C Baker, Y Zhao, and YN Wu (2022). Energy-based continuous inverse optimal control. IEEE transactions on neural networks and learning systems. pdfproject page Comment: The energy function learned from human drivers serves as the cost function for optimal control in autonomous driving.
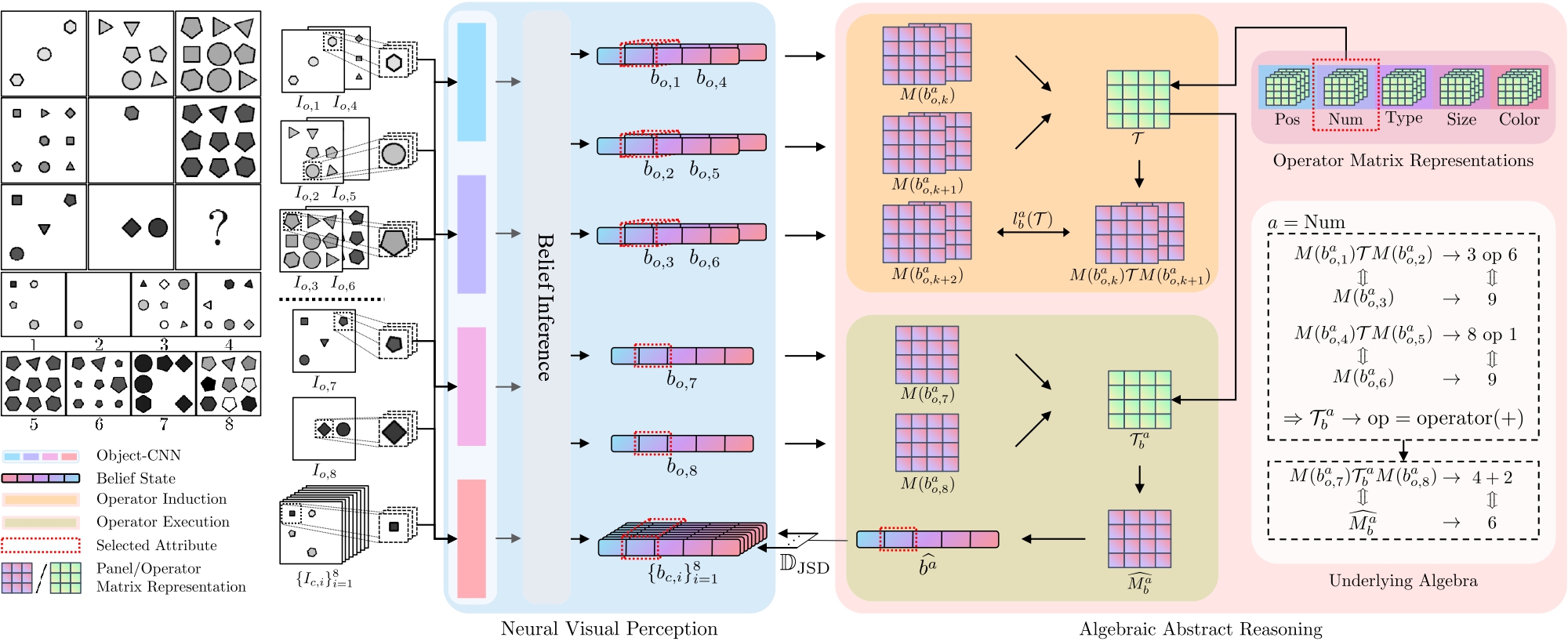
C Zhang, S Xie, B Jia, YN Wu, SC Zhu, and Y Zhu (2022). Learning algebraic representation for systematic generalization in abstract reasoning. European Conference on Computer Vision (ECCV 2022). pdf | project page F Gao, Q Ping, G Thattai, A Reganti, YN Wu, and P Natarajan (2022). Transform-retrieve-generate: natural language-centric outside-knowledge visual question answering. IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2022). pdf
(mode traversing HMC chains) E Nijkamp, R Gao, P Sountsov, S Vasudevan, B Pang, SC Zhu, and YN Wu (2022). MCMC should mix: learning energy-based model with neural transport latent space MCMC. International Conference on Learning Representations (ICLR 2022). pdf C Challu, P Jiang, YN Wu, and L Callot (2022). Deep generative model with hierarchical latent factors for time series anomaly detection. International Conference on Artificial Intelligence and Statistics (AISTAT 2022). pdf | project page
(learned V1 cells) R Gao, J Xie, S Huang, Y Ren, SC Zhu, and YN Wu (2022) Learning V1 simple cells with vector representations of local contents and matrix representations of local motions. The Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI) 2022.
pdfproject page Comment: Simple cells in the primary visual cortex are modeled by Gabor wavelets, and adjacent simple cells exhibit quadrature phase relations (e.g., sine and cosine pair). The local image contents are represented by vectors, and the local motions are represented by rotations of the vectors. This explains the aforementioned neuroscience observations. Y Xu, J Zhang, R He, L Ge, C Yang, C Yang, and YN Wu (2022) SAS: self-augmented strategy for language model pre-training. The Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI) 2022. pdf D Kong, B Pang, and YN Wu (2021)
Unsupervised meta-learning via latent space energy-based model of symbol vector coupling.
Fifth Workshop on Meta-Learning at Conference on Neural Information Processing Systems. pdf
(learned grid cells | conformal embedding | torus topology) R Gao, J Xie, X Wei, SC Zhu, and YN Wu (2021) On path integration of grid cells: group representation and isotropic scaling. Neural Information Processing Systems (NeurIPS 2021).
pdf | slides | project page Comment: The brain represents self-position by a vector. When the agent moves, the vector is transformed (or rotated) by a recurrent network. Locally the self-motion is represented by the directional derivative of the recurrent network. The isotropy of the norm of the derivative underlies the hexagon grid patterns, and leads to locally conformal embedding and controlled error translation. The group representation condition and isotropic scaling condition are satisfied by attractor network defined on a 2D torus topographic organization in the cortex. Our theory is on general recurrent model. The special case of linear model is based on matrix Lie group and matrix Lie algebra of rotation. Unitary matrix representation leads to basis functions for representing place cells.
P Yu, S Xie, Y Ma, Y Zhu, YN Wu, and SC Zhu (2021) Unsupervised foreground extraction via deep region competition. Neural Information Processing Systems (NeurIPS 2021). pdfproject page L Yuan, D Zhou, J Shen, J Gao, JL Chen, Q Gu, YN Wu, and SC Zhu (2021) Iterative teacher-aware learning. Neural Information Processing Systems (NeurIPS 2021). pdfproject page
B Pang and YN Wu (2021) Latent space energy-based model of symbol-vector coupling for text generation and classification. International Conference on Machine Learning (ICML 2021). pdfproject page W Han, B Pang, and YN Wu (2021) Robust transfer learning with pretrained language models through adapters. The Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2021). pdf L Qiu, Y Liang, Y Zhao, P Lu, B Peng, Z Yu, YN Wu, and SC Zhu (2021) SocAoG: incremental graph parsing for social relation inference in dialogues. The Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2021).
pdfproject page B Pang, E Nijkamp, T Han, and YN Wu (2021) Generative text modeling through short run inference. The 16th Conference of the European Chapter of the Association for Computational Linguistics (EACL).
pdfproject page E Nijkamp, B Pang, YN Wu, and C Xiong (2021) SCRIPT: Self-Critic Pre-Training of Transformers. The 2021 Conference of the North American Chapter of the Association for Computational Linguistics - Human Language Technologies (NAACL-HLT 2021).
pdf
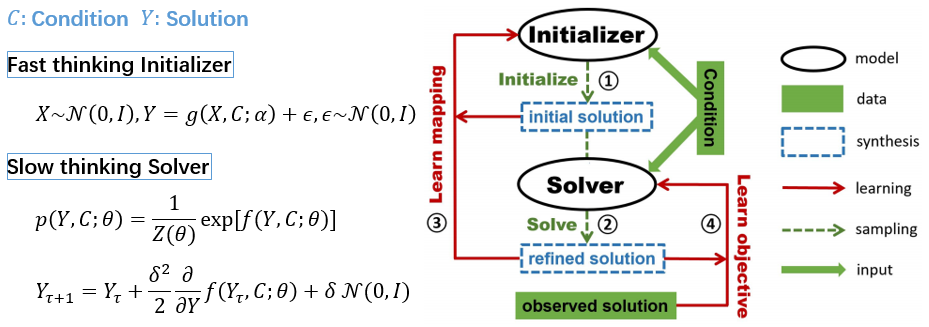
(Initializer is like a policy model, whose solution is refined by a value model) J Xie*, Z Zheng*, X Fang, SC Zhu, and YN Wu (2021) Cooperative training of fast thinking initializer and slow thinking solver for conditional learning. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI). Accepted.
pdfproject page Comment: Compared to GAN-type methods, our method is equipped with an iterative refining process (slow thinking) guided by a learned objective function.
Y Guo, Z Tan, K Chen, S Lu, YN Wu (2021) A model obfuscation approach to IoT security. The 9th IEEE Conference on Communications and Network Security (CNS 2021).
(Predicting trajectory) B Pang, T Zhao, X Xie, and YN Wu (2021) Trajectory prediction with latent belief energy-based model.
Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
pdfproject page Comment: We treat trajectory prediction as an inverse planning problem by learning an energy function (or a cost function, or a value function) defined on a latent belief vector that generates the whole trajectory. Our work goes beyond the Markov decision process (MDP) framework where we do not assume Markovian dynamics or stepwise rewards.
(Change of pose in physical space = rotation of vector in neural space) Y Zhu, R Gao, S Huang, SC Zhu, YN Wu (2021) Learning neural representation of camera pose with matrix representation of pose shift via view synthesis.
Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
pdfproject page Comment: This paper applies the idea in our paper on grid cells to learn vector representation of camera pose, where the change of camera pose is represented by a matrix that rotates the vector. The scheme can also be applied to representing poses of objects in the scene.
J Xie*, Y Xu*, Z Zheng, SC Zhu, and YN Wu (2021) Generative PointNet: deep energy-based learning on unordered point sets for 3D generation, reconstruction and classification.
Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
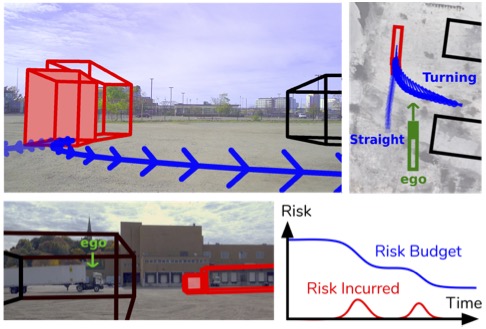
pdfproject page HJ Huang, KC Huang, M Cap, Y Zhao, YN Wu, and C Baker (2021) Planning on a (risk) budget: safe non-conservative planning in probabilistic dynamic environments.
2021 IEEE International Conference on Robotics and Automation (ICRA).
pdf X Xie, C Zhang, Y Zhu, YN Wu, and SC Zhu (2021) Congestion-aware multi-agent trajectory prediction for collision avoidance.
2021 IEEE International Conference on Robotics and Automation (ICRA).
pdfproject page
(Synthesized images) R Gao, Y Song, B Poole, YN Wu, and DP Kingma (2021) Learning energy-based models by diffusion recovery likelihood. International Conference on Learning Representations (ICLR). pdfproject page Q Li, S Huang, Y Hong, Y Zhu, YN Wu, SC Zhu (2021), A HINT from arithmetic: on systematic generalization of perception, syntax, and semantics. The Role of Mathematical Reasoning in General Artificial Intelligence Workshop at ICLR (International Conference on Learning Representations) 2021. pdf S Xie, X Ma, P Yu, Y Zhu, YN Wu, SC Zhu (2021), HALMA: Humanlike Abstraction Learning Meets Affordance in rapid problem solving. Generalization Workshop at ICLR (International Conference on Learning Representations) 2021.
pdfproject page J Xie*, Z Zheng*, X Fang, SC Zhu, and YN Wu (2021) Learning cycle-consistent cooperative networks via alternating MCMC teaching for unsupervised cross-domain translation. The Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI) 2021.
pdfproject page
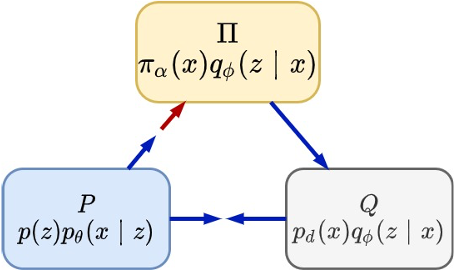
(Left: latent space EBM stands on generator. Right: Short-run MCMC in latent space) B Pang*, T Han*, E Nijkamp*, SC Zhu, and YN Wu (2020) Learning latent space energy-based prior model. Neural Information Processing Systems (NeurIPS), 2020.
pdf (one-page code in appendix) project pageslides Comment: This paper originates from an early work IJCV 2003 by Guo, Zhu, Wu, where a top-down model generates textons, and the energy-based model regulates perceptual organization of textons, or describes the Gestalt law of textons.
The latent space EBM stands on a top-down generation network. It is like a value network or cost function defined in latent space.
The scalar-valued energy function is an objective function, a cost function, an evaluator or a critic. It is about constraints, regularities, rules, perceptual organizations, and Gestalt laws. The energy-based model is descriptive instead of generative, which is the reason we used to call it the descriptive model. It only describes what it wants without bothering with how to get it. Compared to generator model (whose output is high dimensional instead of scalar), the energy-based model is like setting up an equation, whereas the generator model is like generating the solution directly. It is much easier to set up the equation than giving the answer, i.e., it is easier to specify a scalar-valued energy function than a vector-valued generation function, the latter is like a policy network.
The energy-based model in latent space is simple and yet expressive, capturing rules or regularities implicitly but effectively. The latent space seems the right home for energy-based model.
Short-run MCMC in latent space for prior and posterior sampling is efficient and mixes well. One can amortize MCMC with learned network (see our recent work on semi-supervised learning), but in this initial paper we prefer to keep it pure and simple, without mixing in tricks from VAE and GAN.
(Left: latent EBM captures chemical rules implicitly in latent space. Right: generated molecules) B Pang, T Han, and YN Wu (2020) Learning latent space energy-based prior model for molecule generation.
Machine Learning for Molecules Workshop at NeurIPS 2020.
pdf Comment: The EBM in latent space captures the chemical rules effectively (and implicitly).
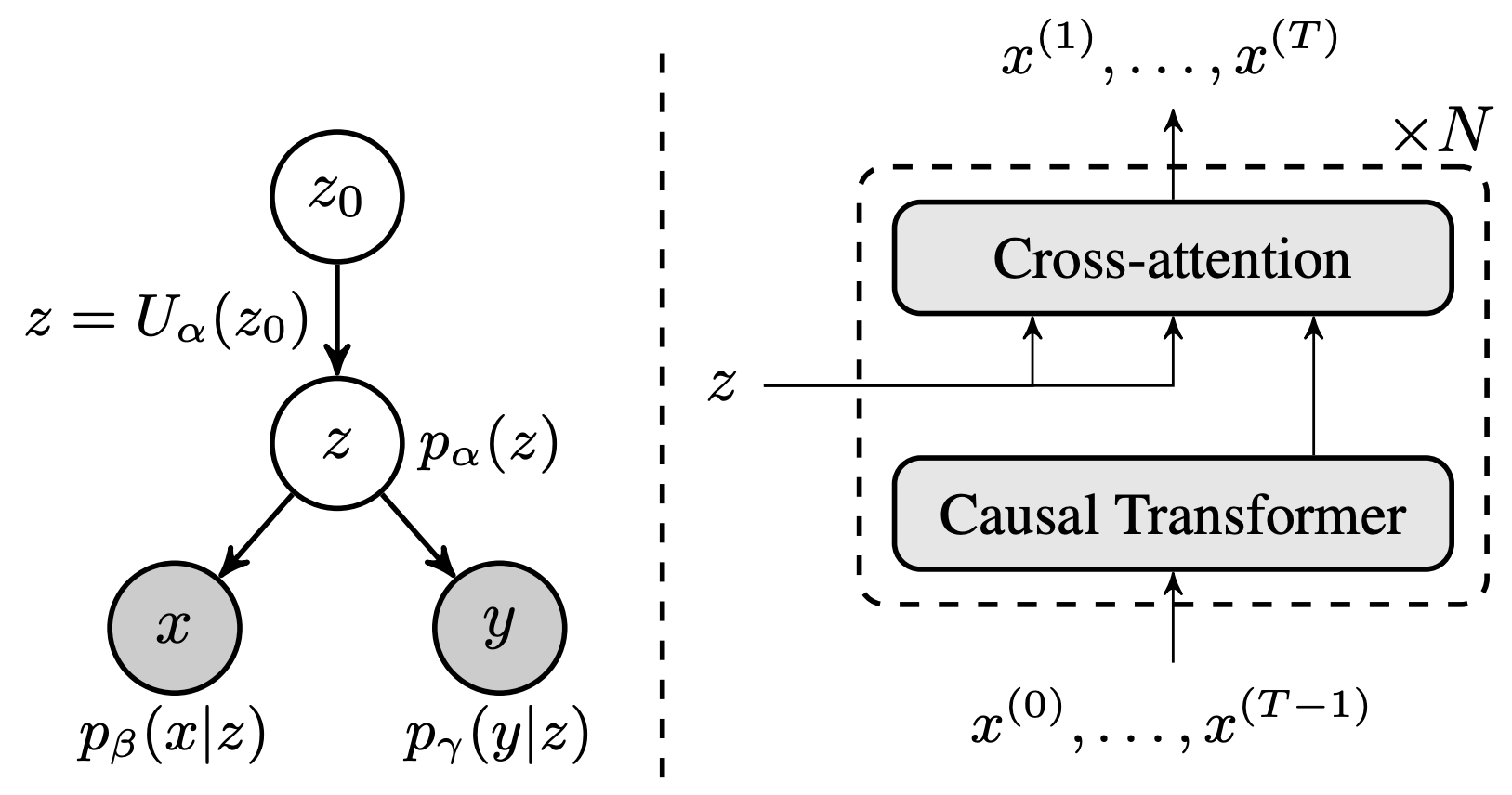
(the symbolic one-hot y is coupled with dense vector z to form an associative memory, and z is the information bottleneck between x and y) B Pang, E Nijkamp, J Cui, T Han, and YN Wu (2020) Semi-supervised learning by latent space energy-based model of symbol-vector coupling. ICBINB Workshop at NeurIPS 2020.
pdf Comment: In this paper, we jointly train the model with an inference network to amortize posterior sampling. The EBM in latent space couples dense vector for generation and one-hot vector for classification. The symbol-vector coupling is like a coin that has a symbolic side and a dense vector side, similar to the particle-wave duality. There may be many such coins and they may be organized in multiple layers. The symbol-vector coupling seeks to model the interaction between hippocampus and entorhinal cortex. The latent vector captures information bottleneck.
(VAE as alternating projection) T Han, J Zhang and YN Wu (2020) From em-projections to variational auto-encoder. Deep Learning through Information Geometry Workshop at NeurIPS 2020.
pdf E Nijkamp*, B Pang*, T Han, L Zhou, SC Zhu, and YN Wu (2020) Learning multi-layer latent variable model via variational optimization of short run MCMC for approximate inference, European Conference on Computer Vision (ECCV).
pdfproject page Comment: The goal is to completely do away with a learned inference network. Short-run MCMC is convenient and automatic for complex top-down models, where top-down feedback and lateral inhibition automatically emerge, and short-run MCMC can be compared to attractor dynamics in neuroscience. J Xie*, Z Zheng*, R Gao, W Wang, SC Zhu, and YN Wu (2020) Generative VoxelNet: learning energy-based models for 3D shape synthesis and analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI). Accepted.
pdfproject page
(The model generates both displacement field and appearance) X Xing, R Gao, T Han, SC Zhu, and YN Wu (2020) Deformable generator networks: unsupervised disentanglement of appearance and geometry. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI). Accepted. pdfproject page Comment: Separating geometry and appearance is crucial for vision. The model represents the displacement of the image grid explicitly.
(neural-symbolic learning) Q Li, S Huang, Y Hong, Y Chen, YN Wu, and SC Zhu (2020) Closed loop neural-symbolic learning via integrating neural perception, grammar parsing, and symbolic reasoning. International Conference on Machine Learning (ICML).
pdfproject page R Gao, E Nijkamp, DP Kingma, Z Xu, AM Dai, and YN Wu (2020) Flow contrastive estimation of energy-based model. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pdfproject page Comment: Noise contrastive estimation (NCE) with flow-based model serving as the contrastive or negative distribution. The flow-based model transports the Gaussian noise distribution to be closer to the data distribution, thus providing stronger contrast. X Xing, T Wu, SC Zhu, and YN Wu (2020) Inducing hierarchical compositional model by sparsifying generator network. Computer Vision and Pattern Recognition (CVPR). pdfproject page Comment: By sparsifying the activities of neurons at multiple layers of a dense top-down model, the learned connections are also sparsified as a result, so that a hierarchical compositional model can emerge.
(Three densities in joint space: pi: latent EBM, p: generator, q: inference) T Han, E Nijkamp, B Pang, L Zhou, SC Zhu, and YN Wu (2020) Joint training of variational auto-encoder and latent energy-based model. Computer Vision and Pattern Recognition (CVPR). pdfproject page Comment: Another version of divergence triangle that unifies variational learning and adversarial learning by an objective function that is of a symmetric and anti-symmetric form that consists of three Kullback-Leibler divergences between three joint distributions. J Xie*, R Gao*, Z Zheng, SC Zhu, and YN Wu (2020) Motion-based generator model: unsupervised disentanglement of appearance, trackable and intrackable motions in dynamic patterns.
AAAI-20: 34th AAAI Conference on Artificial Intelligence. pdfproject page E Nijkamp*, M Hill*, T Han, SC Zhu, and YN Wu (2020) On the anatomy of MCMC-based maximum likelihood learning of energy-based models. (* equal contribution). AAAI-20: 34th AAAI Conference on Artificial Intelligence. pdfproject page J Xie, R Gao, E Nijkamp, SC Zhu, and YN Wu (2020) Representation learning: a statistical perspective. Annual Review of Statistics and Its Application (ARSIA). pdf J Xie, Y Lu, R Gao, SC Zhu, and YN Wu (2020) Cooperative learning of descriptor and generator networks. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI). pdfslidesproject pagevideo Comment: The descriptor is an energy-based model, which we used to call descriptive model, random field model, or Gibbs model in our earlier work on FRAME (Filters, Random field, And Maximum Entropy) model, which was one of the earliest energy-based models before the term energy-based model was coined. The generator serves as a learned sampler of EBM to amortize the MCMC sampling of EBM. The generator learns from MCMC samples by a temporal difference scheme which we call MCMC teaching. The MCMC samples can be considered the internal data. The point is that the neural network can learn from external data of observations for modeling, but it can also learn from internal data of computations for amortized computing.
(reconstruction by short-run MCMC, yes it can reconstruct observed images) E Nijkamp, M Hill, SC Zhu, and YN Wu (2019) On learning non-convergent non-persistent short-run MCMC toward energy-based model. Neural Information Processing Systems (NeurIPS), 2019 pdf (code in appendix) Z Zhang*, Z Pan*, Y Ying, Z Xie, S Adhikari, J Phillips, RP Carstens, DL Black, YN Wu, and Y Xing (2019) Deep-learning augmented RNA-seq analysis of transcript splicing. Nature Methods, 16:307-10, pdf T Han, X Xing, J Wu, and YN Wu (2019) Replicating neuroscience observations on ML/MF and AM face patches by deep generative model. Neural Computation, pdf
(learned grid cells) R Gao*, J Xie*, SC Zhu, and YN Wu (2019) Learning grid cells as vector representation of self-position coupled with matrix representation of self-motion. (* equal contribution). International Conference on Learning Representations (ICLR). pdfproject page Comment: While vector can be used to represent entities (nouns), matrix can be used to represent actions, changes, and relations (verbs) that form groups. Group representation is a central topic in modern mathematics and physics.
(videos generated by the learned model) T Han, L Yang, J Wu, X Xing, and YN Wu (2019) Learning generator networks for dynamic patterns. Winter Conference on Applications of Computer Vision (WACV 2019).
pdf project page Comment: The video is generated by a single thought vector via a top-down spatial-temporal deconvolutional network, where we treat time as a �spatial� dimension. The spatial-temporal approach models the whole sequence (or trajectory or event) and avoids auto-regressive (or hidden Markovian or dynamic) modeling.
(videos generated by the learned model) J Xie, SC Zhu, and YN Wu (2019) Learning energy-based spatial-temporal generative ConvNet for dynamic patterns. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI).
pdf project page Comment: The video is generated by an EBM where the energy function is defined by a bottom-up spatial-temporal convolutional network, where we treat time as a �spatial� dimension.
(faces generated and interpolated by the learned model)
(pi is EBM, p is generator, q is inference) T Han*, E Nijkamp*, X Fang, M Hill, SC Zhu, YN Wu (2019) Divergence triangle for joint training of generator model, energy-based model, and inference model.(* equal contribution). Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pdfproject page Comment: The divergence triangle unifies variational learning and adversarial learning by an objective function that is of a symmetric and anti-symmetric form that consists of three Kullback-Leibler divergences between three joint distributions. X Xing, T Han, R Gao, SC Zhu, and YN Wu (2019) Unsupervised disentanglement of appearance and geometry by deformable generator network. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pdfproject page
(videos generated by the learned model) J Xie*, R Gao*, Z Zheng, SC Zhu, and YN Wu (2019) Learning dynamic generator model by alternating back-propagation through time. AAAI-19: 33rd AAAI Conference on Artificial Intelligence. pdfproject page Comment: The model is a non-linear generalization of state space model, where each image frame I_t of the video is generated by a latent state vector s_t, which follows an auto-regressive model s_t+1 = f(s_t, e_t), where e_t is innovation noise vector. YN Wu, R Gao, T Han, and SC Zhu (2019) A tale of three probabilistic families: discriminative, descriptive and generative models. Quarterly of Applied Mathematics. pdf T Han, J Wu, and YN Wu (2018) Replicating active appearance model by generator network. International Joint Conference on Artificial Intelligence (IJCAI). pdf J Xie*, Z Zheng*, R Gao, W Wang, SC Zhu, and YN Wu (2018) Learning descriptor networks for 3D shape synthesis and analysis. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
pdfproject page
(face rotation by the learned model) T Han, X Xing, and YN Wu (2018) Learning multi-view generator network for shared representation. 24th International Conference on Pattern Recognition (ICPR 2018).
pdf R Gao*, Y Lu*, J Zhou, SC Zhu, and YN Wu (2018) Learning generative ConvNets via multigrid modeling and sampling. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
pdfproject page Comment: Scale up maximum likelihood learning of modern ConvNet energy-based model to big datasets. S Huang, S Qi, Y Xiao, Y Zhu, YN Wu and SC Zhu (2018) Cooperative holistic scene understanding: unifying 3D object, layout, and camera pose estimation. Neural Information Processing Systems (NeurIPS). J Xie, Y Lu, R Gao, and YN Wu (2018) Cooperative learning of energy-based model and latent variable model via MCMC teaching. AAAI-18: 32nd AAAI Conference on Artificial Intelligence.
pdfslidesproject page Comment: The EBM is the teacher, and the generator is the student. Student writes a draft, teacher revises it, student learns from revision. Compared to GAN, the cooperative learning has a revision process that improves the results from generator. J Xie, SC Zhu, and YN Wu (2017) Synthesizing dynamic patterns by spatial-temporal generative ConvNet. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
pdf project page Comment: The paper gives adversarial interpretation of maximum likelihood learning of ConvNet-parametrized energy-based model.
(learning directly from occluded images. Row 1: original images, not available to model; Row 2: training images. Row 3: learning and reconstruction. ) T Han*, Y Lu*, SC Zhu, and YN Wu (2017) Alternating back-propagation for generator network. AAAI-17: 31st AAAI Conference on Artificial Intelligence. pdf |
project page |
Pytorch code |
TensorFlow code Comment: Maximum likelihood learning of generator network, without resorting to inference model.
(left: observed; right: synthesized.) J Xie*, Y Lu*, SC Zhu, and YN Wu (2016) A theory of generative ConvNet. International Conference on Machine Learning (ICML).
pdf project page Comment: Maximum likelihood learning of modern ConvNet-parametrized energy-based model, with connections to Hopfield network, auto-encoder, score matching and contrastive divergence. About energy-based model: (a) It is an unnormalized density defined by scalar-valued energy function. (b) It actually is a big softmax probability. (c) It learns soft regularizations, rules, or constraints, or soft objective function, value function or cost function. (d) It is a generative classifier that can be learned discriminatively or contrastively. (e) Defining energy function in the latent abstract solution space of a top-down model can be particularly convenient.
(Langevin dynamics for sampling ConvNet-EBM) Y Lu, SC Zhu, and YN Wu (2016) Learning FRAME models using CNN filters. AAAI-16: 30th AAAI Conference on Artificial Intelligence. pdf project page Comment: The modern ConvNet-parametrized energy-based model is a multi-layer generalization of FRAME (Filter, Random field, And Maximum Entropy) model, Neural Computation 1997, Zhu, Wu, and Mumford. This paper generates realistic images by Langevin sampling of modern ConvNet-EBM. The Langevin dynamics was interpreted as Gibbs Reaction And Diffusion Equations (GRADE) by PAMI 1998, Zhu and Mumford. J Dai, Y Lu, and YN Wu (2015) Generative modeling of convolutional neural networks. International Conference on Learning Representations (ICLR). pdf project page Comment: The paper formulates modern ConvNet-parametrized energy-based model as exponential tilting of a reference distribution, and connect it to discriminative ConvNet classifier.
Below are selected earlier papers
J Xie, Y Lu, SC Zhu, and YN Wu (2016) Inducing wavelets into random fields via generative boosting. Applied and Computational Harmonic Analysis, 41, 4-25. pdf project page
J Xie, W Hu, SC Zhu, and YN Wu (2014) Learning sparse FRAME models for natural image patterns.
International Journal of Computer Vision.
pdf project page
J Dai, Y Hong, W Hu, SC Zhu, and YN Wu (2014) Unsupervised learning of dictionaries of hierarchical compositional models. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
pdf project page
J Dai, YN Wu, J Zhou, and SC Zhu (2013) Cosegmentation and cosketch by unsupervised learning. Proceedings of International Conference on Computer Vision (ICCV).
pdf project page
Y Hong, Z Si, WZ Hu, SC Zhu, and YN Wu (2013) Unsupervised learning of
compositional sparse code for natural image representation. Quarterly of Applied Mathematics.
pdfproject page
YN Wu, Z Si, H Gong, SC Zhu (2010) Learning active basis model for object
detection and recognition. International Journal of Computer Vision,
90, 198-235.
pdf project page
Z Si, H Gong, SC Zhu, YN Wu (2010) Learning active basis models by EM-type algorithms.
Statistical Science, 25, 458-475.
pdf project page
YN Wu, C Guo, SC Zhu (2008) From information scaling of natural images to
regimes of statistical models. Quarterly of Applied Mathematics, 66, 81-122.
pdf
YN Wu, Z Si, C Fleming, and SC Zhu (2007) Deformable template as active basis.
Proceedings of International Conference of Computer Vision.
pdf project page
M Zheng, LO Barrera, B Ren, YN Wu (2007) ChIP-chip: data, model and analysis.
Biometrics, 63, 787-796.
pdf
C Guo, SC Zhu, and YN Wu (2007) Primal sketch: integrating structure
and texture. Computer Vision and Image Understanding, 106, 5-19.
pdf project page
C Guo, SC Zhu, and YN Wu (2003) Towards a mathematical theory of primal
sketch and sketchability. Proceedings of International Conference of Computer Vision.
1228-1235.
pdf project page
G Doretto, A Chiuso, YN Wu, S Soatto (2003) Dynamic textures. International
Journal of Computer Vision, 51, 91-109.
pdf (source
code given in paper)
project page
C Guo, SC Zhu, and YN Wu (2003) Modeling visual patterns by integrating descriptive and generative models. International Journal of Computer Vision, 53(1), 5-29. pdf
JC Pinheiro, C Liu, YN Wu (2001) Efficient algorithms for robust estimation in linear mixed-effects models using the multivariate t distribution. Journal of Computational and Graphical Statistics 10 (2), 249-276. pdf
YN Wu, SC Zhu, X Liu (2000) Equivalence of Julesz ensembles and FRAME models.
International Journal of Computer Vision, 38, 247-265.
pdf project page
JS Liu, YN Wu (1999) Parameter expansion for data augmentation. Journal of
the American Statistical Association, 94, 1264-1274.
pdf
C Liu, DB Rubin, YN Wu (1998) Parameter expansion to accelerate EM -- the PX-EM
algorithm. Biometrika, 85, 755-770.
pdf
SC Zhu, YN Wu, DB Mumford (1998) Minimax entropy principle and its application
to texture modeling. Neural Computation, 9, 1627-1660.
pdf
SC Zhu, YN Wu, DB Mumford (1997) Filter, Random field, And Maximum Entropy
(FRAME): towards a unified theory for texture modeling. International Journal
of Computer Vision, 27, 107-126.
pdf
YN Wu (1995) Random shuffling: a new approach to matching problem.
Proceedings of American Statistical Association, 69-74. Longer version
pdf